Hibench对大数据平台CDH/HDP基准性能测试
一、部署方式
1.1、源码/包:https://github.com/Intel-bigdata/HiBench
部署方法:
https://github.com/Intel-bigdata/HiBench/blob/master/docs/build-hibench.md
注意:hibench执行需hadoop客户端jar包环境
如何使用HiBench进行基准测试说明:
https://cloud.tencent.com/developer/article/1158310
二、目录/文件简介

主要介绍下bin执行文件目录和conf配置文件目录。
·2.1配置文件目录--conf

benchmarks.lst 配置需测试项
frameworks.lst 配置测试hadoop或spark
hibench.conf 配置数据量级别及文件数等
hadoop.conf hadoop home、master等配置项
spark.conf spark home、master、 Yarn运行核数、内存等配置项
workloads目录 存放各种具体测试项配置文件
·2.2配置文件说明
|
文件名 |
主要用途 |
|
benchmarks.lst |
主要用于配置benchmarks的模块 |
|
flink.conf.template |
Flink测试的配置参数 |
|
frameworks.lst |
主要用于配置HiBench支持的测试框架 |
|
gearpump.conf.template |
gearpump测试相关配置文件 |
|
hadoop.conf.template |
Hadoop测试相关配置文件 |
|
hibench.conf |
HiBench配置文件 |
|
spark.conf.template |
Spark配置文件 |
|
storm.conf.template |
Strom配置文件 |
·2.3配置文件说明
··2.3.1. benchmarks.lst配置文件
主要用于配置benchmarks列表,配置如下,可以对不需要测试的模块进行屏蔽或者删除,在需要屏蔽在前面加“#”如下:(适用于执行run_all.sh)
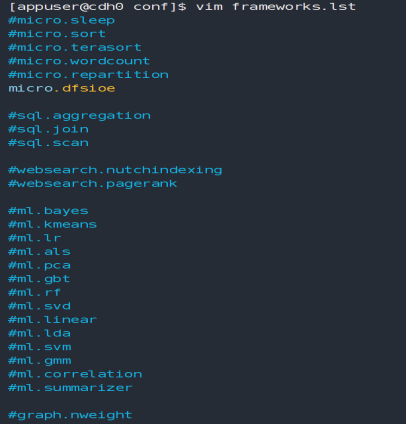
··2.3.2. hadoop.conf.template配置文件
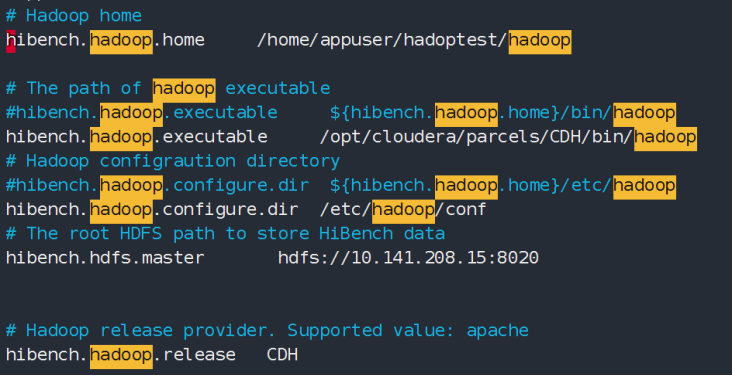
该配置文件主要用于配置Hadoop的环境,如果需要对Hadoop做benchmark测试则需要将该文件重命名为hadoop.conf。
编辑hadoop.conf文件,配置Hadoop环境,此处以CDH的目录配置为例,配置如下:
··2.3.3. spark.conf.template配置文件
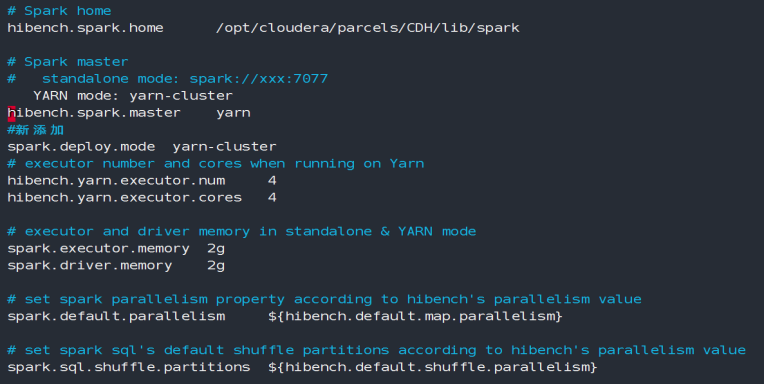
主要用于配置Spark的环境及运行参数,如果需要测试Saprk框架则需要将该配置文件重命名为spark.conf。
编辑spark.conf文件,配置Spark的环境,此处以CDH的目录配置为例,配置如下:根据集群环境调整相应参数。
··2.3.4. hibench.conf配置文件
主要配置HiBench的运行参数及HiBench各个模块的home环境配置,根据需要修改相应的配置参数:
主要关注参数hibench.scale.profile、hibench.default.map.parallelism和hibench.default.shuffle.parallelism配置:
hibench.scale.profile:主要配置HiBench测试的数据规模;
hibench.default.map.parallelism:主要配置MapReduce的Mapper数量;
hibench.default.shuffle.parallelism:配置Reduce数量;
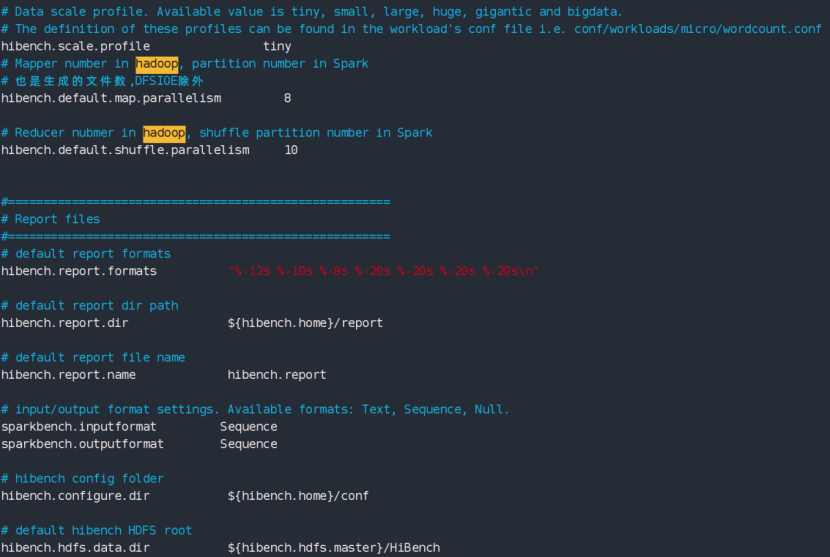
注意:
# 也是生成的文件数,DFSIOE除外
例如 hibench.default.map.parallelism 10
wordcount.conf配置数据量为10000000字节(10M),10个文件,及每个文件为1M。
三、数据规模说明
HiBench的默认数据规模有:tiny, small, large, huge, gigantic andbigdata,在这几种数据规模之外Fayson还介绍如何自己指定数据量。
·3.1DFSIOE数据规模介绍及自定义
配置文件:${hibench.home}/conf/workloads/micro/dfsioe.conf
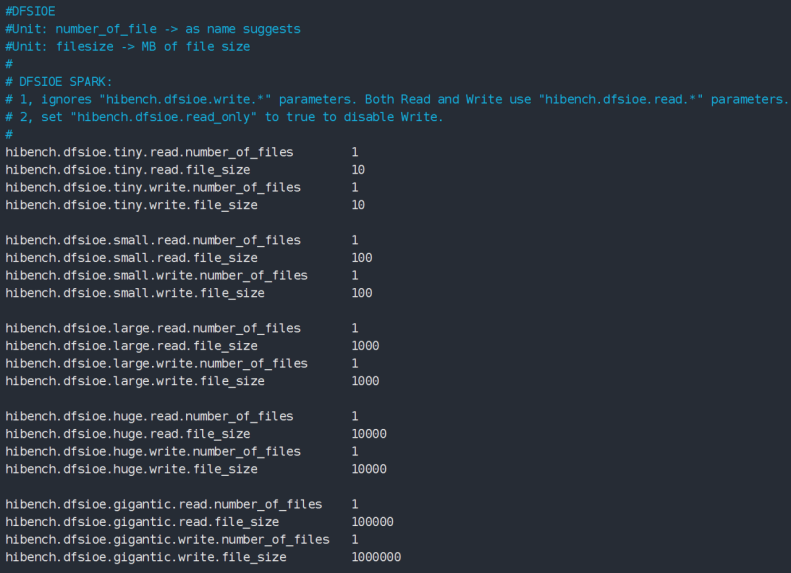
DFSIOE测试用例通过定义读或写的文件数和文件的大小来指定测试数据量的规模,如果需要自定义测试规模则修改文件数和文件的大小即可,文件大小以MB为单位。
例如:我需要自定义一个5TB数量级的DFSIOE测试,在hibench.conf文件中hibench.scale.profile配置的是mybigdata,需要在dfsioe.conf配置文件中增加读写文件数为5120,文件大小设置为1024,具体配置如下:
hibench.dfsioe.mybigdata.read.number_of_files 5120
hibench.dfsioe.mybigdata.read.file_size 1024
hibench.dfsioe.mybigdata.write.number_of_files 5120
hibench.dfsioe.mybigdata.write.file_size 1024
读写测试的数据量均为5TB = 5120 * 1024MB
·3.2举例配置单词统计测试项 数据量大小

进入/conf/workloads/micro目录下,修改wordcount.conf

注意:dfsioe单位:MB,terasort单位:kb,其他测试项单位为:字节。
四、执行文件目录--bin

方式一:
sh run_all.sh
通过在conf下文件配置好数据量及测试项,批量执行测试项测试,包含数据准备及运行。
方式二:
1、具体测试某一项,以单词统计举例,准备数据可进入
/bin/workloads/micro/wordcount/prepare/
执行prepare.sh
(可执行命令hadoop fs -du -h /Hibench/Wordcount 查看对应各个用例生成的测试数据及用例结果
删除测试数据:sudo -u hdfs hadoop fs -rm -r /Hibench/Wordcount)
2、运行测试,进入/bin/workloads/micro/wordcount/hadoop/ 执行run.sh

五、查看报告文件

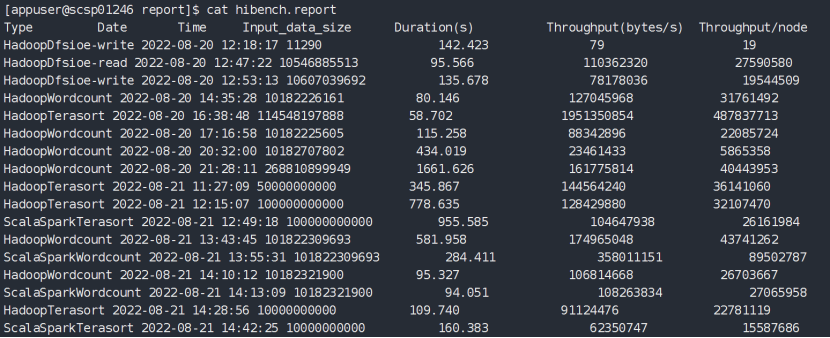
进入/report下,查看 hibench.report,其中包含类型、执行日期和时间,数据量,主要关注:持续时间,吞吐量/秒和吞吐量/节点。
Hibench对大数据平台CDH/HDP基准性能测试的更多相关文章
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
- 大数据 -- Cloudera Manager(简称CM)+CDH构建大数据平台
一.Cloudera Manager介绍 Cloudera Manager(简称CM)是Cloudera公司开发的一款大数据集群安装部署利器,这款利器具有集群自动化安装.中心化管理.集群监控.报警等功 ...
- HDP 企业级大数据平台
一 前言 阅读本文前需要掌握的知识: Linux基本原理和命令 Hadoop生态系统(包括HDFS,Spark的原理和安装命令) 由于Hadoop生态系统组件众多,导致大数据平台多节点的部署,监控极其 ...
- CM记录-CDH大数据平台实施经验总结2016(转载)
CDH大数据平台实施经验总结2016(转载) 2016年负责实施了一个生产环境的大数据平台,用的CDH平台+docker容器的方式,过了快半年了,现在把总结发出来. 1. 平台规划注意事项 1.1 业 ...
- product of大数据平台搭建------CM 和CDH安装
一.安装说明 CM是由cloudera公司提供的大数据组件自动部署和监控管理工具,相应的和CDH是cloudera公司在开源的hadoop社区版的基础上做了商业化的封装的大数据平台. 采用离线安装模式 ...
- CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager
CDH构建大数据平台-使用自建的镜像地址安装Cloudera Manager 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搭建CM私有仓库 详情请参考我的笔记: http ...
- CDH 大数据平台搭建
一.概述 Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,简称“CDH”),基于Web的用户界面,支持大多数Hadoop组件,包括 ...
- HDP 大数据平台搭建
一.概述 Apache Ambari是一个基于Web的支持Apache Hadoop集群的供应.管理和监控的开源工具,Ambari已支持大多数Hadoop组件,包括HDFS.MapReduce.Hiv ...
- CDH构建大数据平台-配置集群的Kerberos认证安全
CDH构建大数据平台-配置集群的Kerberos认证安全 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 当平台用户使用量少的时候我们可能不会在一集群安全功能的缺失,因为用户少,团 ...
- CDH构建大数据平台-Kerberos高可用部署【完结篇】
CDH构建大数据平台-Kerberos高可用部署[完结篇] 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.安装Kerberos相关的软件包并同步配置文件 1>.实验环境 ...
随机推荐
- Linux 设置 VI 快捷键 -- 在多个打开的文件中切换
场景 部署完一系列服务后,想要查看所有服务的 catelina.out 日志: vi $(find /data/http | grep catalina.out | grep -v bak) 这个命令 ...
- LiveCD 与 救援模式、紧急模式
LiveCD 参考:live CD LiveCD 能够使你在不安装到硬盘的前提下,体验操作系统.大多数 Linux 桌面发行版都提供 LiveCD,这是宣传自己的一种很有效的方式. 救援模式 救援模式 ...
- Web通用漏洞--文件包含
Web通用漏洞--文件包含 文件包含原理 在项目开发过程中,开发人员通常会将重复使用的函数写入单个文件中,在使用该类函数时,直接调用文件即可,无需重新编写,这种调用文件的过程成为文件包含.在文件包含过 ...
- 【opencv】传统目标检测:HOG+SVM实现行人检测
传统目标分类器主要包括Viola Jones Detector.HOG Detector.DPM Detector,本文主要介绍HOG Detector与SVM分类器的组合实现行人检测. HOG(Hi ...
- Java Maven POM配置参考
介绍 什么是POM? POM代表"项目对象模型".它是一个名为pom.XML的文件中保存的Maven项目的XML表示. 快速概览 这是一个直接位于POM项目元素下的元素列表.请注意 ...
- Redis系列21:缓存与数据库的数据一致性讨论
Redis系列1:深刻理解高性能Redis的本质 Redis系列2:数据持久化提高可用性 Redis系列3:高可用之主从架构 Redis系列4:高可用之Sentinel(哨兵模式) Redis系列5: ...
- 数据可视化【原创】vue+arcgis+threejs 实现立体光圈闪烁效果
本文适合对vue,arcgis4.x,threejs,ES6较熟悉的人群食用. 效果图: 素材: 主要思路: 先用arcgis externalRenderers封装了一个ExternalRender ...
- B2C在线教育商城--前后端分离部署
博客地址:https://www.cnblogs.com/zylyehuo/ 技术栈:vue + nginx + uwsgi + django + mariadb + redis 基本流程 vue打包 ...
- 【krpano】KRPano自动缩略图分组插件
该插件可以展示场景缩略图,并支持场景分组. 下载地址:http://pan.baidu.com/s/1dFj7v0l 使用说明: 插件共有两个文件,auto_thumbs.xml和tooltip.xm ...
- MyBatis-Plus和PageHelper冲突导致Factory method sqlSessionFactory threw exception,并且如何分页显示全部
springboot开始引入了mybaits-plus.后来想引入pagehelper进行分页,引入之后报错 Error starting ApplicationContext. To display ...