浅谈SQL优化小技巧
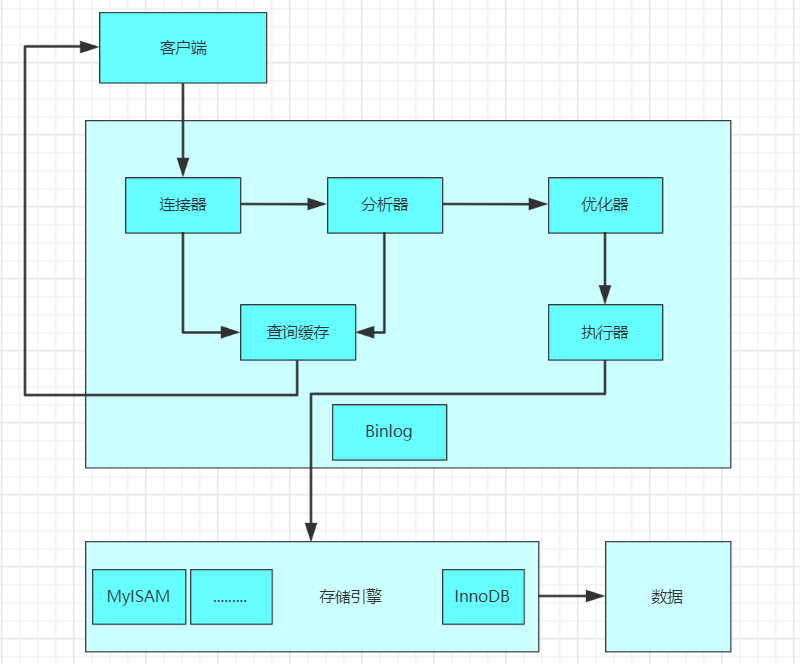
回顾MySQL的执行过程,帮助介绍如何进行sql优化。
(1)客户端发送一条查询语句到服务器;
(2)服务器先查询缓存,如果命中缓存,则立即返回存储在缓存中的数据;
(3)未命中缓存后,MySQL通过关键字将SQL语句进行解析,并生成一颗对应的解析树,MySQL解析器将使用MySQL语法进行验证和解析。
例如,验证是否使用了错误的关键字,或者关键字的使用是否正确;
(4)预处理是根据一些MySQL规则检查解析树是否合理,比如检查表和列是否存在,还会解析名字和别名,然后预处理器会验证权限;
根据执行计划查询执行引擎,调用API接口调用存储引擎来查询数据;
(5)将结果返回客户端,并进行缓存;
SQL语句性能优化常用策略
1、 为 WHERE 及 ORDER BY 涉及的列上建立索引
对查询进行优化,应尽量避免全表扫描,首先应考虑在 WHERE 及 ORDER BY 涉及的列上建立索引。
2、where中使用默认值代替null 应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,创建表时 NULL 是默认值,但大多数时候应该使用 NOT NULL,或者使用一个特殊的值,如 0,-1 作为默认值。
为啥建议where中使用默认值代替null,四个原因:
(1)并不是说使用了is null或者 is not null就会不走索引了,这个跟mysql版本以及查询成本都有关;
(2)如果mysql优化器发现,走索引比不走索引成本还要高,就会放弃索引,这些条件 !=,<>,is null,is not null经常被认为让索引失效;
(3)其实是因为一般情况下,查询的成本高,优化器自动放弃索引的;
(4)如果把null值,换成默认值,很多时候让走索引成为可能,同时,表达意思也相对清晰一点;
3、慎用 != 或 <> 操作符。
MySQL 只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的 LIKE。
所以:应尽量避免在 WHERE 子句中使用 != 或 <> 操作符, 会导致全表扫描。
4、慎用 OR 来连接条件
使用or可能会使索引失效,从而全表扫描;
应尽量避免在 WHERE 子句中使用 OR 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,
可以使用 UNION 合并查询:
select id from t where num=10
union all
select id from t where num=20
一个关键的问题是否用到索引。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用 UNION all 执行的效率更高。多个 OR 的字句没有用到索引,改写成 UNION 的形式再试图与索引匹配。
5、慎用 IN 和 NOT IN
IN 和 NOT IN 要慎用,否则会导致全表扫描。对于连续的数值,能用 BETWEEN 就不要用 IN:select id from t where num between 1 and 3。
6、慎用 左模糊like ‘%…’
模糊查询,程序员最喜欢的就是使用like,like很可能让索引失效。
比如:
select id from t where name like‘%abc%’ select id from t where name like‘%abc’ 而select id from t where name like‘abc%’才用到索引。
所以:
首先尽量避免模糊查询,如果必须使用,不采用全模糊查询,也应尽量采用右模糊查询, 即like ‘…%’,是会使用索引的; 左模糊like ‘%…’无法直接使用索引,但可以利用reverse + function index的形式,变化成 like ‘…%’; 全模糊查询是无法优化的,一定要使用的话建议使用搜索引擎,比如 ElasticSearch。 备注:如果一定要用左模糊like ‘%…’检索, 一般建议 ElasticSearch+Hbase架构
7、WHERE条件使用参数会导致全表扫描。
如下面语句将进行全表扫描:
select id from t where num=@num
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推 迟到 运行时;
它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
所以, 可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
8、用 EXISTS 代替 IN 是一个好的选择
很多时候用exists 代替in 是一个好的选择:
select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
9、索引并不是越多越好
索引固然可以提高相应的 SELECT 的效率,但同时也降低了 INSERT 及 UPDATE 的效。
因为 INSERT 或 UPDATE 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过 6 个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
10、尽量使用数字型字段
(1)因为引擎在处理查询和连接时会逐个比较字符串中每一个字符;
(2)而对于数字型而言只需要比较一次就够了;
(3)字符会降低查询和连接的性能,并会增加存储开销;
所以:尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
11、尽可能的使用 varchar, nvarchar 代替 char, nchar
(1)varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间;
(2)char按声明大小存储,不足补空格;
(3)其次对于查询来说,在一个相对较小的字段内搜索,效率更高;
因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
*14、查询SQL尽量不要使用select ,而是具体字段
最好不要使用返回所有:select * from t ,用具体的字段列表代替 “*”,不要返回用不到的任何字段。
select *的弊端:
(1)增加很多不必要的消耗,比如CPU、IO、内存、网络带宽;
(2)增加了使用覆盖索引的可能性;
(3)增加了回表的可能性;
(4)当表结构发生变化时,前端也需要更改;
(5)查询效率低;
15、将需要查询的结果预先计算好
将需要查询的结果预先计算好放在表中,查询的时候再Select,而不是查询的时候进行计算。
16、IN后出现最频繁的值放在最前面
如果一定用IN,那么:在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数。
17、尽量使用 EXISTS 代替 select count(1) 来判断是否存在记录。
count 函数只有在统计表中所有行数时使用,而且 count(1) 比 count(*) 更有效率。
18、用批量插入或批量更新
当有一批处理的插入或更新时,用批量插入或批量更新,绝不会一条条记录的去更新。
(1)多条提交
INSERT INTO user (id,username) VALUES(1,'xx'); INSERT INTO user (id,username) VALUES(2,'yy');
(2)批量提交
INSERT INTO user (id,username) VALUES(1,'xx'),(2,'yy'); 默认新增SQL有事务控制,导致每条都需要事务开启和事务提交,而批量处理是一次事务开启和提交,效率提升明显,达到一定量级,效果显著,平时看不出来。
19、将不需要的记录在 GROUP BY 之前过滤掉
提高 GROUP BY 语句的效率,可以通过将不需要的记录在 GROUP BY 之前过滤掉。
下面两个查询返回相同结果,但第二个明显就快了许多。
低效:
SELECT JOB, AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB = 'PRESIDENT' OR JOB = 'MANAGER' 高效:
SELECT JOB, AVG(SAL) FROM EMP WHERE JOB = 'PRESIDENT' OR JOB = 'MANAGER' GROUP BY JOB
20、避免死锁
在你的存储过程和触发器中访问同一个表时总是以相同的顺序;事务应经可能地缩短,在一个事务中应尽可能减少涉及到的数据量;永远不要在事务中等待用户输入。
21、索引创建规则:
表的主键、外键必须有索引;
数据量超过 300 的表应该有索引;
经常与其他表进行连接的表,在连接字段上应该建立索引;
经常出现在 WHERE 子句中的字段,特别是大表的字段,应该建立索引;
索引应该建在选择性高的字段上;
索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替;
正确选择复合索引中的主列字段,一般是选择性较好的字段;
复合索引的几个字段是否经常同时以 AND 方式出现在 WHERE 子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
如果复合索引中包含的字段经常单独出现在 WHERE 子句中,则分解为多个单字段索引;
如果复合索引所包含的字段超过 3 个,那么仔细考虑其必要性,考虑减少复合的字段;
如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
频繁进行数据操作的表,不要建立太多的索引; 删除无用的索引,避免对执行计划造成负面影响;
表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。
另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。 尽量不要对数据库中某个含有大量重复的值的字段建立索引。
22、在写 SQL 语句时,应尽量减少空格的使用
查询缓冲并不自动处理空格,因此,在写 SQL 语句时,应尽量减少空格的使用,尤其是在 SQL 首和尾的空格(因为查询缓冲并不自动截取首尾空格)。
23、每张表都设置一个 ID 做为其主键
我们应该为数据库里的每张表都设置一个 ID 做为其主键,而且最好的是一个 INT 型的(推荐使用 UNSIGNED),并设置上自动增加的 AUTO_INCREMENT 标志。
24、使用explain分析你SQL执行计划
(1)type
system:表仅有一行,基本用不到;
const:表最多一行数据配合,主键查询时触发较多;
eq_ref:对于每个来自于前面的表的行组合,从该表中读取一行。这可能是最好的联接类型,除了const类型;
ref:对于每个来自于前面的表的行组合,所有有匹配索引值的行将从这张表中读取;
range:只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range;
index:该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小;
all:全表扫描;
性能排名:system > const > eq_ref > ref > range > index > all。 实际sql优化中,最后达到ref或range级别。
(2)Extra常用关键字
Using index:只从索引树中获取信息,而不需要回表查询;
Using where:WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。需要回表查询。
Using temporary:mysql常建一个临时表来容纳结果,典型情况如查询包含可以按不同情况列出列的GROUP BY和ORDER BY子句时;
25、当只要一行数据时使用 LIMIT 1
当你查询表的有些时候,你已经知道结果只会有一条结果,但因为你可能需要去fetch游标,或是你也许会去检查返回的记录数。
在这种情况下,加上 LIMIT 1 可以增加性能。
这样一来,MySQL 数据库引擎会在找到一条数据后停止搜索,而不是继续往后查少下一条符合记录的数据。
26、将大的DELETE,UPDATE、INSERT 查询变成多个小查询
能写一个几十行、几百行的SQL语句是不是显得逼格很高?然而,为了达到更好的性能以及更好的数据控制,你可以将他们变成多个小查询。
27、合理分表 尽量控制单表数据量的大小,建议控制在500万以内
500万并不是MySQL数据库的限制,过大会造成修改表结构,备份,恢复都会有很大的问题。
可以用历史数据归档(应用于日志数据),分库分表(应用于业务数据)等手段来控制数据量大小。
作者:京东科技 梁发文
来源:京东云开发者社区 转载请注明来源
浅谈SQL优化小技巧的更多相关文章
- 浅谈SQL优化入门:3、利用索引
0.写在前面的话 关于索引的内容本来是想写的,大概收集了下资料,发现并没有想象中的简单,又不想总结了,纠结了一下,决定就大概写点浅显的,好吧,就是懒,先挖个浅坑,以后再挖深一点.最基本的使用很简单,直 ...
- 浅谈sql优化
问题的发现: 菜鸟D在工作的时候发现项目的sql语句很怪,例如 : select a.L_ZTBH, a.D_RQ, a.VC_BKDM, (select t.vc_name from tb ...
- 浅谈SQL优化入门:1、SQL查询语句的执行顺序
1.SQL查询语句的执行顺序 (7) SELECT (8) DISTINCT <select_list> (1) FROM <left_table> (3) <join_ ...
- 浅谈SQL优化入门:2、等值连接和EXPLAIN(MySQL)
1.等值连接:显性连接和隐性连接 在<MySQL必知必会>中对于等值连接有提到两种方式,第一种是直接在WHERE子句中规定如何关联即可,那么第二种则是使用INNER JOIN关键字.如下例 ...
- SQL优化小技巧
我们要做到不但会写SQL,还要做到写出性能优良的SQL语句. 1.使用表的别名(Alias): 当在SQL语句中连接多个表时, 请使用表的别名并把别名前缀于每个Column上.这样一来,就可以减少解析 ...
- IT咨询顾问:一次吐血的项目救火 java或判断优化小技巧 asp.net core Session的测试使用心得 【.NET架构】BIM软件架构02:Web管控平台后台架构 NetCore入门篇:(十一)NetCore项目读取配置文件appsettings.json 使用LINQ生成Where的SQL语句 js_jquery_创建cookie有效期问题_时区问题
IT咨询顾问:一次吐血的项目救火 年后的一个合作公司上线了一个子业务系统,对接公司内部的单点系统.我收到该公司的技术咨询:项目启动后没有规律的突然无法登录了,重新启动后,登录一断时间后又无法重新登 ...
- 浅谈SQL Server数据内部表现形式
在上篇文章 浅谈SQL Server内部运行机制 中,与大家分享了SQL Server内部运行机制,通过上次的分享,相信大家已经能解决如下几个问题: 1.SQL Server 体系结构由哪几部分组成? ...
- 浅谈SQL Server---1
浅谈SQL Server优化要点 https://www.cnblogs.com/wangjiming/p/10123887.html 1.SQL Server 体系结构由哪几部分组成? 2.SQL ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 转【】浅谈sql中的in与not in,exists与not exists的区别_
浅谈sql中的in与not in,exists与not exists的区别 1.in和exists in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表 ...
随机推荐
- 【技术积累】Linux中的命令行【理论篇】【九】
blkid命令 命令介绍 blkid命令是一个用于查看块设备属性的Linux命令.它可以识别和显示块设备的文件系统类型.UUID.LABEL.PARTUUID等信息. 命令说明 在Linux下可以使用 ...
- 春秋云镜像-CVE-2022-0788
准备: 攻击机:win10. 靶机:春秋云镜像-CVE-2022-0788. 写这个的时候在网上想查找下该漏洞的利用方式,没有找到相关的资料,因此记录下自己通过这个靶场的poc与exp. curl ' ...
- pycharm+anaconda的关联
Pycharm+anaconda的关联 关联好处:Pycharm和anaconda关联后,pycharm可以直接调用anaconda中已安装好的模块,而anaconda里安装和卸载模块都比较方便. 关 ...
- DevSecOps之应用安全测试工具及选型
上篇文章,有同学私信想了解有哪些DevSecOps工具,这里整理出来,供大家参考(PS: 非专业安全人士,仅从DevOps建设角度,给出自己见解) 软件中的漏洞和弱点很常见:84%的软件漏洞都是利用应 ...
- 循序渐进介绍基于CommunityToolkit.Mvvm 和HandyControl的WPF应用端开发(2)
在前面随笔<循序渐进介绍基于CommunityToolkit.Mvvm 和HandyControl的WPF应用端开发(1)>中介绍了Mvvm 的开发,以及一些界面效果,本篇随笔继续深入探讨 ...
- 前端三件套系例之BootStrap——BootStrap基础、 BootStrap布局
文章目录 1 BootStrap基础 1 什么是BootStrap 2 BootStrap的版本 3 BootStrap 下载 4 CDN服务 5 目录结构 6 基本模板 7 浏览器支持 8 浏览器兼 ...
- 什么是 CSS?
1.什么是 CSS? CSS 指的是层叠样式表* (Cascading Style Sheets) CSS 描述了如何在屏幕.纸张或其他媒体上显示 HTML 元素 CSS 节省了大量工作.它可以同时控 ...
- ERROR: <bits/stdc++.h>, 'cstdalign' file not found, running C++17
Modified 1 year, 1 month ago Viewed 9k times 4 I'm trying to run a piece of code in Visual Studio Co ...
- k8s集群部署初体验
目录 ██ 环境准备[所有节点] ██ 安装Docker/kubeadm/kubelet[所有节点] ██ 部署 k8s master ██ 部署 k8s node ██ 部署网络插件[CNI] ██ ...
- [SWPUCTF 2021 新生赛]老鼠走迷宫(详细版
附件下载 https://wwvc.lanzouj.com/iYLez1br84jg 解题思路 用pyinstxtrator解析exe 重点:将无后缀的5先修改后缀为pyc,然后随便找一个pyc文件补 ...