python语言绘图:绘制贝叶斯方法中最大后验密度(Highest Posterior Density, HPD)区间图的近似计算(续)
代码源自:
https://github.com/PacktPublishing/Bayesian-Analysis-with-Python
内容接前文:
python语言绘图:绘制贝叶斯方法中最大后验密度(Highest Posterior Density, HPD)区间图的近似计算
===========================================================
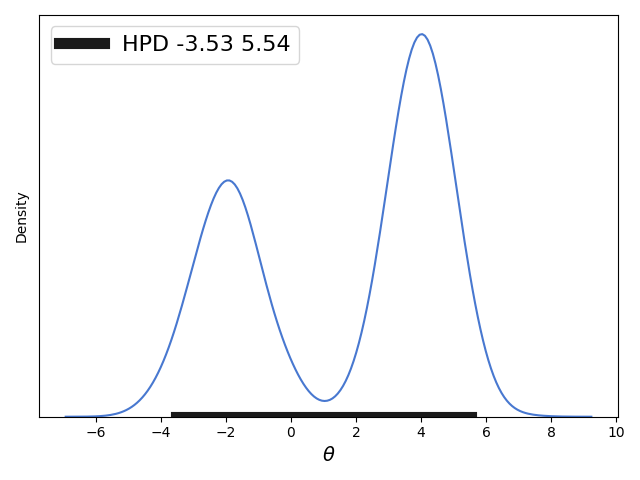
前文主要讨论的是对于单峰分布的概率分布求近似的HPD,但是对于双峰分布求解HPD并不是很好,如下图(前文内容中的图):
==============================================================
我们求解的近似HPD中间有一个概率密度很低的区间,当然如果HPD可以不是一个连续区间的话我们可以有更好的求解方法呢,下面给出解法:


from __future__ import division
import matplotlib.pyplot as plt
import numpy as np
from scipy import stats
import seaborn as sns
palette = 'muted'
sns.set_palette(palette); sns.set_color_codes(palette) np.random.seed(1)
gauss_a = stats.norm.rvs(loc=4, scale=0.9, size=3000)
gauss_b = stats.norm.rvs(loc=-2, scale=1, size=2000)
mix_norm = np.concatenate((gauss_a, gauss_b)) import numpy as np
import scipy.stats.kde as kde def hpd_grid(sample, alpha=0.05, roundto=2):
"""Calculate highest posterior density (HPD) of array for given alpha.
The HPD is the minimum width Bayesian credible interval (BCI).
The function works for multimodal distributions, returning more than one mode Parameters
---------- sample : Numpy array or python list
An array containing MCMC samples
alpha : float
Desired probability of type I error (defaults to 0.05)
roundto: integer
Number of digits after the decimal point for the results Returns
----------
hpd: array with the lower """
sample = np.asarray(sample)
sample = sample[~np.isnan(sample)]
# get upper and lower bounds
l = np.min(sample)
u = np.max(sample)
density = kde.gaussian_kde(sample)
x = np.linspace(l, u, 2000)
y = density.evaluate(x)
# y = density.evaluate(x, l, u) waitting for PR to be accepted
xy_zipped = zip(x, y / np.sum(y))
xy = sorted(xy_zipped, key=lambda x: x[1], reverse=True)
xy_cum_sum = 0
hdv = []
for val in xy:
xy_cum_sum += val[1]
hdv.append(val[0])
if xy_cum_sum >= (1 - alpha):
break
hdv.sort()
diff = (u - l) / 20 # differences of 5%
hpd = []
hpd.append(round(min(hdv), roundto))
for i in range(1, len(hdv)):
if hdv[i] - hdv[i - 1] >= diff:
hpd.append(round(hdv[i - 1], roundto))
hpd.append(round(hdv[i], roundto))
hpd.append(round(max(hdv), roundto))
ite = iter(hpd)
hpd = list(zip(ite, ite))
modes = []
for value in hpd:
x_hpd = x[(x > value[0]) & (x < value[1])]
y_hpd = y[(x > value[0]) & (x < value[1])]
modes.append(round(x_hpd[np.argmax(y_hpd)], roundto))
return hpd, x, y, modes import numpy as np
from scipy import stats
import matplotlib.pyplot as plt def plot_post(sample, alpha=0.05, show_mode=True, kde_plot=True, bins=50,
ROPE=None, comp_val=None, roundto=2):
"""Plot posterior and HPD Parameters
---------- sample : Numpy array or python list
An array containing MCMC samples
alpha : float
Desired probability of type I error (defaults to 0.05)
show_mode: Bool
If True the legend will show the mode(s) value(s), if false the mean(s)
will be displayed
kde_plot: Bool
If True the posterior will be displayed using a Kernel Density Estimation
otherwise an histogram will be used
bins: integer
Number of bins used for the histogram, only works when kde_plot is False
ROPE: list or numpy array
Lower and upper values of the Region Of Practical Equivalence
comp_val: float
Comparison value Returns
------- post_summary : dictionary
Containing values with several summary statistics """ post_summary = {'mean': 0, 'median': 0, 'mode': 0, 'alpha': 0, 'hpd_low': 0,
'hpd_high': 0, 'comp_val': 0, 'pc_gt_comp_val': 0, 'ROPE_low': 0,
'ROPE_high': 0, 'pc_in_ROPE': 0} post_summary['mean'] = round(np.mean(sample), roundto)
post_summary['median'] = round(np.median(sample), roundto)
post_summary['alpha'] = alpha # Compute the hpd, KDE and mode for the posterior
hpd, x, y, modes = hpd_grid(sample, alpha, roundto)
post_summary['hpd'] = hpd
post_summary['mode'] = modes ## Plot KDE.
if kde_plot:
plt.plot(x, y, color='k', lw=2)
## Plot histogram.
else:
plt.hist(sample, bins=bins, facecolor='b',
edgecolor='w') ## Display mode or mean:
if show_mode:
string = '{:g} ' * len(post_summary['mode'])
plt.plot(0, label='mode =' + string.format(*post_summary['mode']), alpha=0)
else:
plt.plot(0, label='mean = {:g}'.format(post_summary['mean']), alpha=0) ## Display the hpd.
hpd_label = ''
for value in hpd:
plt.plot(value, [0, 0], linewidth=10, color='b')
hpd_label = hpd_label + '{:g} {:g}\n'.format(round(value[0], roundto), round(value[1], roundto))
plt.plot(0, 0, linewidth=4, color='b', label='hpd {:g}%\n{}'.format((1 - alpha) * 100, hpd_label))
## Display the ROPE.
if ROPE is not None:
pc_in_ROPE = round(np.sum((sample > ROPE[0]) & (sample < ROPE[1])) / len(sample) * 100, roundto)
plt.plot(ROPE, [0, 0], linewidth=20, color='r', alpha=0.75)
plt.plot(0, 0, linewidth=4, color='r', label='{:g}% in ROPE'.format(pc_in_ROPE))
post_summary['ROPE_low'] = ROPE[0]
post_summary['ROPE_high'] = ROPE[1]
post_summary['pc_in_ROPE'] = pc_in_ROPE
## Display the comparison value.
if comp_val is not None:
pc_gt_comp_val = round(100 * np.sum(sample > comp_val) / len(sample), roundto)
pc_lt_comp_val = round(100 - pc_gt_comp_val, roundto)
plt.axvline(comp_val, ymax=.75, color='g', linewidth=4, alpha=0.75,
label='{:g}% < {:g} < {:g}%'.format(pc_lt_comp_val,
comp_val, pc_gt_comp_val))
post_summary['comp_val'] = comp_val
post_summary['pc_gt_comp_val'] = pc_gt_comp_val plt.legend(loc=0, framealpha=1)
frame = plt.gca()
frame.axes.get_yaxis().set_ticks([])
return post_summary plot_post(mix_norm, roundto=2, alpha=0.05)
plt.legend(loc=0, fontsize=16)
plt.xlabel(r"$\theta$", fontsize=14)
plt.savefig('B04958_01_09.png', dpi=300, figsize=(5.5, 5.5)) plt.show()
这个代码的代码量比较大,其实功能和前文的逻辑是一致的。
对HPD区间的求解核心代码:
def hpd_grid(sample, alpha=0.05, roundto=2):
"""Calculate highest posterior density (HPD) of array for given alpha.
The HPD is the minimum width Bayesian credible interval (BCI).
The function works for multimodal distributions, returning more than one mode Parameters
---------- sample : Numpy array or python list
An array containing MCMC samples
alpha : float
Desired probability of type I error (defaults to 0.05)
roundto: integer
Number of digits after the decimal point for the results Returns
----------
hpd: array with the lower """
sample = np.asarray(sample)
sample = sample[~np.isnan(sample)]
# get upper and lower bounds
l = np.min(sample)
u = np.max(sample)
density = kde.gaussian_kde(sample)
x = np.linspace(l, u, 2000)
y = density.evaluate(x)
# y = density.evaluate(x, l, u) waitting for PR to be accepted
xy_zipped = zip(x, y / np.sum(y))
xy = sorted(xy_zipped, key=lambda x: x[1], reverse=True)
xy_cum_sum = 0
hdv = []
for val in xy:
xy_cum_sum += val[1]
hdv.append(val[0])
if xy_cum_sum >= (1 - alpha):
break
hdv.sort()
diff = (u - l) / 20 # differences of 5%
hpd = []
hpd.append(round(min(hdv), roundto))
for i in range(1, len(hdv)):
if hdv[i] - hdv[i - 1] >= diff:
hpd.append(round(hdv[i - 1], roundto))
hpd.append(round(hdv[i], roundto))
hpd.append(round(max(hdv), roundto))
ite = iter(hpd)
hpd = list(zip(ite, ite))
modes = []
for value in hpd:
x_hpd = x[(x > value[0]) & (x < value[1])]
y_hpd = y[(x > value[0]) & (x < value[1])]
modes.append(round(x_hpd[np.argmax(y_hpd)], roundto))
return hpd, x, y, modes
同样都是使用蒙特卡洛模拟方法,但是与前文内容这里并不是直接使用原始概率分布来生成采样数据(似然分布)而是将获得的原始分布的数据进行高斯核函数估计出一个概率密度(概率函数),然后用这个估计出的概率函数再重新生成数据,这种方法虽然会造成得到的概率分布和原始概率分布的一定偏差不过该种方法十分适合无法获得原始概率分布的情况,而且经过本人测试使用高斯核函数估计出的概率函数基本和原始的概率分布吻合(十分的神奇)。
生成新的概率分布函数:
density = kde.gaussian_kde(sample)
生成新的样本数据:
x = np.linspace(l, u, 2000)
y = density.evaluate(x)
对新生成的样本数据数据的对应概率密度进行规则化:( 这样可以保证即使采样的数据量不是十分大的情况下生成的数据对应的概率密度区间的面积和为1,方便下面对0.95HPD区间面积加和求解时的计算)
xy_zipped = zip(x, y / np.sum(y))
对0.95的HPD区间求解,原理就是将区间各点概率从大到小排序然后求得加总后等于0.95的最少的区间点,这也是上一步对各点概率进行规则化的主要原因。这步求得的点对应的概率加和为0.95,并且保证样本点数目最少,这样也保证对应的区间尽可能的小以满足近似HPD最小区间的要求。
xy = sorted(xy_zipped, key=lambda x: x[1], reverse=True)
xy_cum_sum = 0
hdv = []
for val in xy:
xy_cum_sum += val[1]
hdv.append(val[0])
if xy_cum_sum >= (1 - alpha):
break
hdv.sort()
设置一个区间阈值diff,如果上一步求得的区间中如果有两个排序后相邻的点之间距离大于这个阈值就认为这两个点是不连续的(分属两个区间中),然后记录这两个点。计算结束后记录上步求得的HPD区间中的两个边界点。这样求得的hpd列表中每两个数代表一个区间,这样就保证最后求得的HPD区间可以是不连续的。
diff = (u - l) / 20 # differences of 5%
hpd = []
hpd.append(round(min(hdv), roundto))
for i in range(1, len(hdv)):
if hdv[i] - hdv[i - 1] >= diff:
hpd.append(round(hdv[i - 1], roundto))
hpd.append(round(hdv[i], roundto))
hpd.append(round(max(hdv), roundto))
这一步中求得的hpd列表为[-4.06, 0.16, 1.82, 6.18],其中[-4.06, 0.16,]代表一个区间,[1.82, 6.18]代表另一个区间。
上面的核心代码中还有求解所谓的众数的代码,由于这个概率分布时连续的因此所谓的众数就是概率密度最大的数。
ite = iter(hpd)
hpd = list(zip(ite, ite))
modes = []
for value in hpd:
x_hpd = x[(x > value[0]) & (x < value[1])]
y_hpd = y[(x > value[0]) & (x < value[1])]
modes.append(round(x_hpd[np.argmax(y_hpd)], roundto))
return hpd, x, y, modes
上面的代码不难,不过有个很有意思的python代码,其实搞python代码快10多个年头了即使是今天还会遇到一些没发现过的pythonic的代码,上面就有这种:
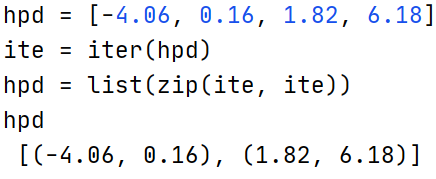
ite为列表hpd的迭代器。
zip(ite,ite)是惰性计算,在list(zip(ite,ite))时才会从迭代器ite中提取数据,虽然zip每次从两个迭代器中提取数据但是这两个迭代器都是一个ite迭代器,那么就会zip每次从两个ite中提取数据实际都是一个ite提供的,因此最终的提取结果就是hpd中的数据依次提取两个,最后的提取结果就是[(-4.06, 0.16), (1.82, 6.18)]。如果不这样写可能就得这么写这个代码了:
hpd2=[ ]
for i in range(1, len(hpd)):
hpd2.append((hpd[i-1], hpd[i]))
print(hpd2)

=========================================================
python语言绘图:绘制贝叶斯方法中最大后验密度(Highest Posterior Density, HPD)区间图的近似计算(续)的更多相关文章
- 概率编程:《贝叶斯方法概率编程与贝叶斯推断》中文PDF+英文PDF+代码
贝叶斯推理的方法非常自然和极其强大.然而,大多数图书讨论贝叶斯推理,依赖于非常复杂的数学分析和人工的例子,使没有强大数学背景的人无法接触.<贝叶斯方法概率编程与贝叶斯推断>从编程.计算的角 ...
- 使用pycharm手动搭建python语言django开发环境(四) django中buffer类型与str类型的联合使用
在django中,如果用到buffer类型时,buffer的编码格式是utf-8类型.使用str()进行转为字符串类型会异常. 异常会有如下提示:'ascii' codec can't decode ...
- 统计学习方法与Python实现(三)——朴素贝叶斯法
统计学习方法与Python实现(三)——朴素贝叶斯法 iwehdio的博客园:https://www.cnblogs.com/iwehdio/ 1.定义 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设 ...
- 第四章 朴素贝叶斯法(naive_Bayes)
总结 朴素贝叶斯法实质上是概率估计. 由于加上了输入变量的各个参量条件独立性的强假设,使得条件分布中的参数大大减少.同时准确率也降低. 概率论上比较反直觉的一个问题:三门问题:由于主持人已经限定了他打 ...
- Python实现 利用朴素贝叶斯模型(NBC)进行问句意图分类
目录 朴素贝叶斯分类(NBC) 程序简介 分类流程 字典(dict)构造:用于jieba分词和槽值替换 数据集构建 代码分析 另外:点击右下角魔法阵上的[显示目录],可以导航~~ 朴素贝叶斯分类(NB ...
- Python语言程序设计(3)--实例2-python蟒蛇绘制-turtle库
1. 2. 3.了解turtle库 Turtle,也叫海龟渲染器,使用Turtle库画图也叫海龟作图.Turtle库是Python语言中一个很流行的绘制图像的函数库.海龟渲染器,和各种三维软件都有着良 ...
- 基于python语言的经典排序法(冒泡法和选择排序法)
前 每逢周末就遇雨期,闲暇之余,捣鼓了下python,心心念想学习,今天就在电脑上装了个2.7,学习了下经典算法,冒泡与选择排序法 第一次写关于python的文章,说的不当之处,多多指正,我积极改正 ...
- 【机器学习实战笔记(3-2)】朴素贝叶斯法及应用的python实现
文章目录 1.朴素贝叶斯法的Python实现 1.1 准备数据:从文本中构建词向量 1.2 训练算法:从词向量计算概率 1.3 测试算法:根据现实情况修改分类器 1.4 准备数据:文档词袋模型 2.示 ...
- 了解 Python 语言中的时间处理
python 语言对于时间的处理继承了 C语言的传统,时间值是以秒为单位的浮点数,记录的是从1970年1月1日零点到现在的秒数,这个秒数可以转换成我们日常可阅读形式的日期和时间:我们下面首先来看一下p ...
- Python语言程序设计之一--for循环中累加变量是否要清零
最近学到了Pyhton中循环这一章.之前也断断续续学过,但都只是到了函数这一章就停下来了,写过的代码虽然保存了下来,但是当时的思路和总结都没有记录下来,很可惜.这次我开通了博客,就是要把这些珍贵的学习 ...
随机推荐
- 使用Microsoft.SemanticKernel基于本地运行的Ollama大语言模型实现Agent调用函数
大语言模型的发展日新月异,记得在去年这个时候,函数调用还是gpt-4的专属.到今年本地运行的大模型无论是推理能力还是文本的输出质量都已经非常接近gpt-4了.而在去年gpt-4尚未发布函数调用时,智能 ...
- python UI自动化,怎么在控制台调试代码?
Chrom 控制台调试脚本 http://testingpai.com/article/1606720137383 可以在任意网页按 F12 进入开发者工具,选择 console 输入 JS 代码: ...
- UIButton选择状态下长按时会变回原始状态
问题大概就像这样 (请无视那红字) 一般而言这是高亮状态的设置有所缺乏.完善代码如下: [_pupilBtn setImage:[UIImage imageNamed:@"a1"] ...
- 《最新出炉》系列入门篇-Python+Playwright自动化测试-52- 字符串操作 - 下篇
1.简介 在日常的自动化测试工作中进行断言的时候,我们可能经常遇到的场景.从一个字符串中找出一组数字或者其中的某些关键字,而不是将这一串字符串作为结果进行断言.这个时候就需要我们对字符串进行操作,宏哥 ...
- uniapp+thinkphp5实现微信扫码支付(APP支付)
前言 统一支付是JSAPI/NATIVE/APP各种支付场景下生成支付订单,返回预支付订单号的接口,目前微信支付所有场景均使用这一接口.下面介绍的是其中APP的支付的配置与实现流程 配置 1.首先登录 ...
- 核对不同文件夹所含内容的差异并提取缺失内容:Python代码
本文介绍基于Python语言,以一个大文件夹作为标准,对另一个大文件夹所包含的子文件夹或文件加以查漏补缺,并将查漏补缺的结果输出的方法. 首先,来明确一下本文所需实现的具体需求.现有一个大文件 ...
- yb课堂 核心数据库表字段设计和测试数据准备 《一》
设计对应的表字段(统一使用Innodb引擎,mysql5.7) video_banner video chapter episode video_order user 数据库脚本 CREATE TAB ...
- Claude是否超过Chatgpt,成为生成式AI的一哥?
Anthropic 周一推出了 Claude 3 ,据这家初创公司称,该系列中最有能力的 Claude 3 Opus 在各种基准测试中都优于 Openai 的竞争对手 GPT-4 和谷歌的 Gemin ...
- oeasy教您玩转vim - 30 - # 屏位行号
屏位行号 回忆上节课内容 上次我们主要讲的翻页 :set scrolloff=2 控制上下留天留地 上下翻页(这个最常用) ctrl + f 向下一屏 ctrl + b 向上一屏 上下移屏一行 c ...
- C# Winform与JS交互
一.C#调用JS函数 1.JS代码 < script language = "javascript" > function Hello(msg) { alert('我是 ...