Python爬虫知识点四--scrapy框架
一。scrapy结构数据
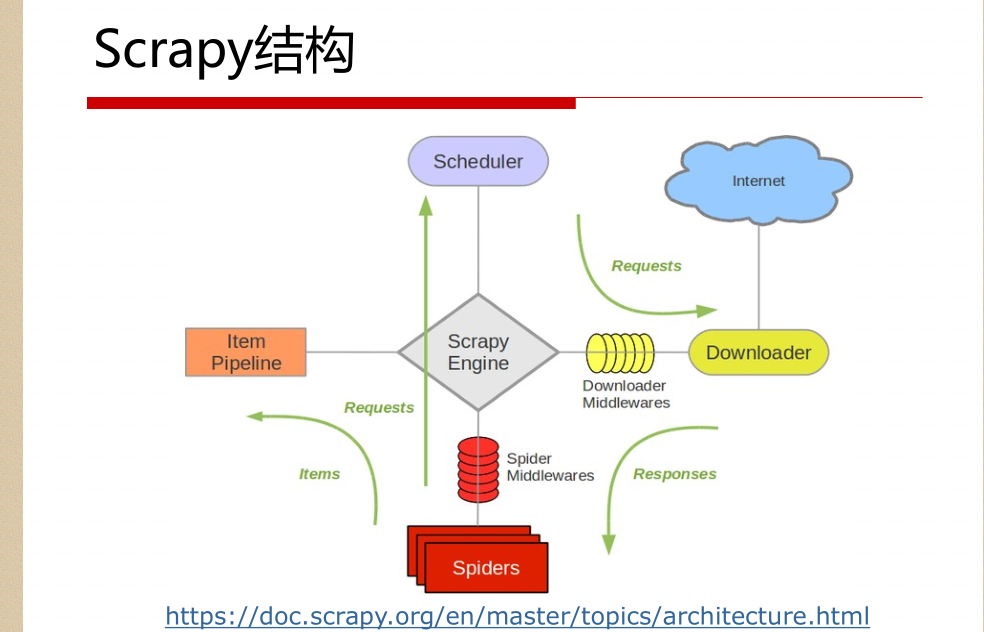
解释:
1.名词解析:
o 引擎(Scrapy Engine)
o 调度器(Scheduler)
o 下载器(Downloader)
o 蜘蛛(Spiders)
o 项目管道(Item Pipeline)
o 下载器中间件(Downloader Middlewares)
o 蜘蛛中间件(Spider Middlewares)
o 调度中间件(Scheduler Middlewares)
2.具体解析
绿线是数据流向
从初始URL开始,Scheduler会将其交给Downloader进
行下载
下载之后会交给Spider进行分析
Spider分析出来的结果有两种
一种是需要进一步抓取的链接,如 “下一页”的链接,它们
会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline里,进行
后期处理(详细分析、过滤、存储等)。
在数据流动的通道里还可以安装各种中间件,进行必
要的处理。
二。初始化爬虫框架 Scrapy
命令: scrapy startproject qqnews
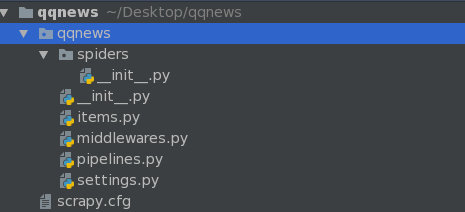
ps:真正的项目是在spiders里面写入的
三。scrapy组件spider
爬取流程
1. 先初始化请求URL列表,并指定下载后处
理response的回调函数。
2. 在parse回调中解析response并返回字典,Item
对象,Request对象或它们的迭代对象。
3 .在回调函数里面,使用选择器解析页面内容
,并生成解析后的结果Item。
4. 最后返回的这些Item通常会被持久化到数据库
中(使用Item Pipeline)或者使用Feed exports将
其保存到文件中。
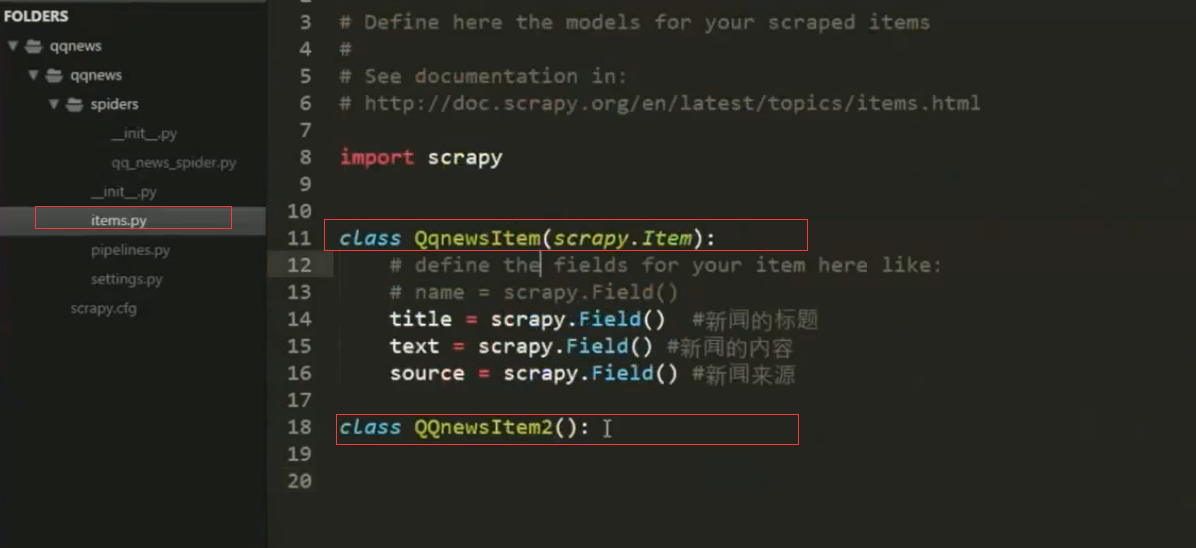
标准项目结构实例:
1.items结构:定义变量,根据不同种数据结构定义
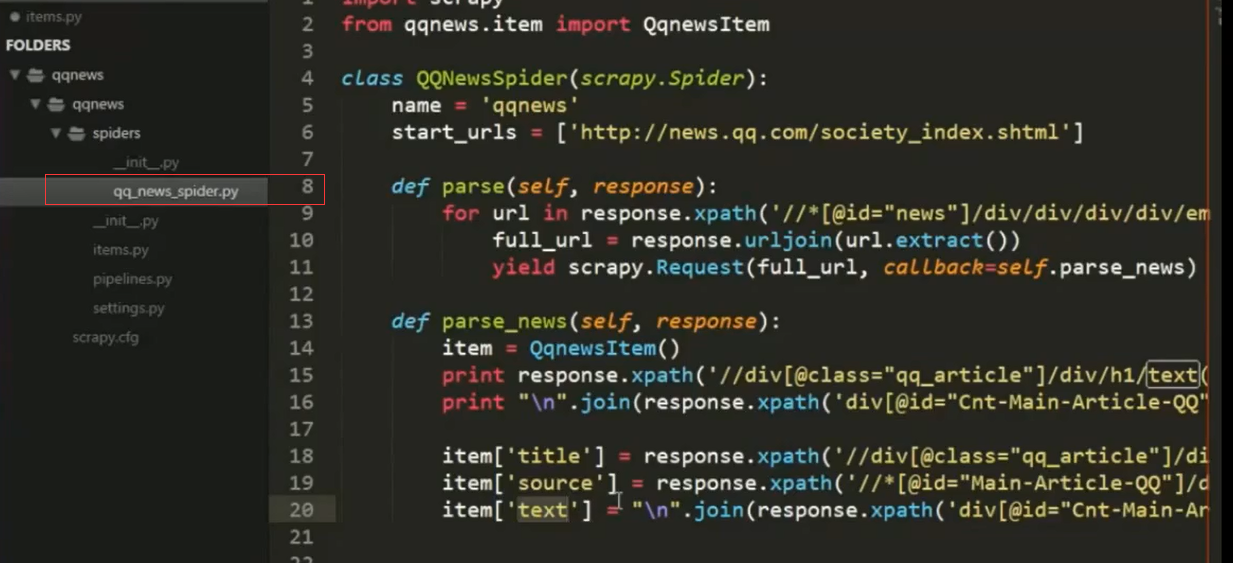
2.spider结构中引入item里面,并作填充item
3。pipline去清洗,验证,存入数据库,过滤等等 后续处理
Item Pipeline常用场景
清理HTML数据
验证被抓取的数据(检查item是否包含某些字段)
重复性检查(然后丢弃)
将抓取的数据存储到数据库中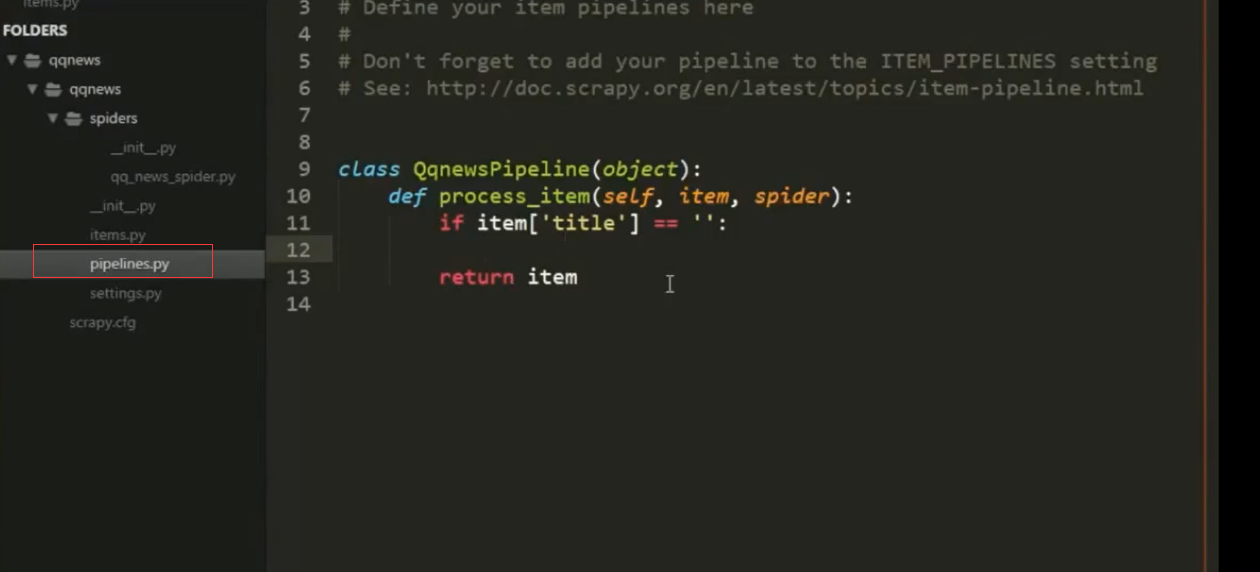
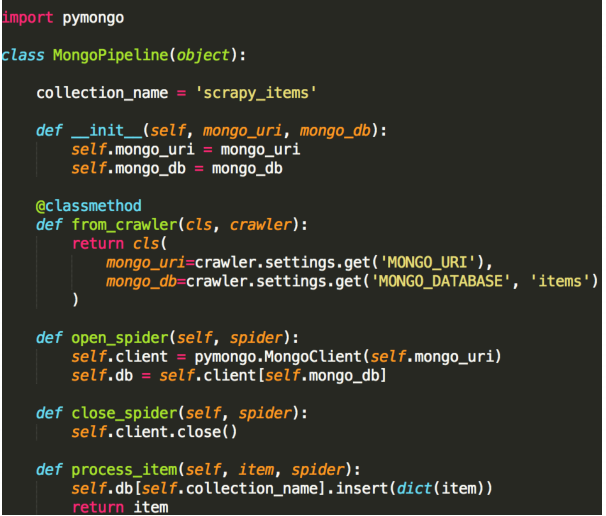
4.Scrapy组件Item Pipeline
经常会实现以下的方法:
open_spider(self, spider) 蜘蛛打开的时执行
close_spider(self, spider) 蜘蛛关闭时执行
from_crawler(cls, crawler) 可访问核心组件比如配置和
信号,并注册钩子函数到Scrapy中
pipeline真正处理逻辑
定义一个Python类,实现方法process_item(self, item,
spider)即可,返回一个字典或Item,或者抛出DropItem
异常丢弃这个Item。
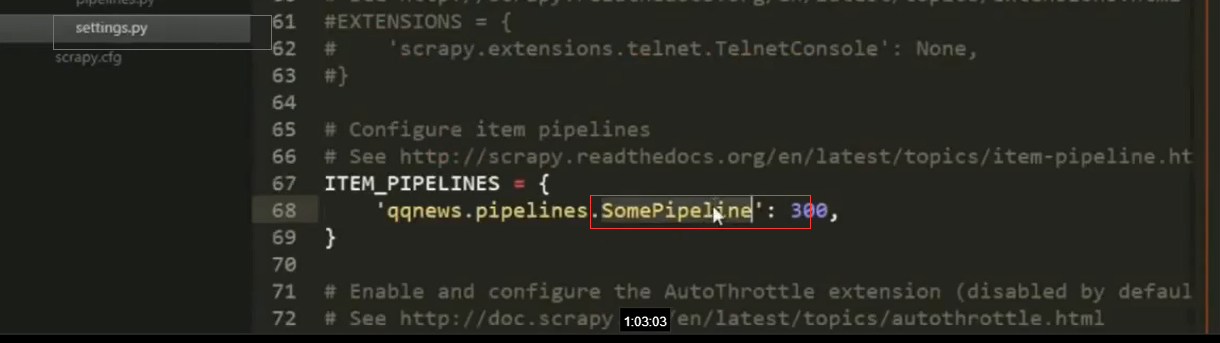
5.settings中定义哪种类型的pipeline
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Python爬虫知识点四--scrapy框架的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- JQuery自定义插件详解之Banner图滚动插件
前 言 JRedu JQuery是什么相信已经不需要详细介绍了.作为时下最火的JS库之一,JQuery将其"Write Less,Do More!"的口号发挥的极致.而帮助J ...
- 通过 PackageManager 获得你想要的 App 信息
一.前言 开门见山,开篇明义.有些场景下,我们会需要获取一些其它 App 的各项信息,例如:App 名称,包名.Icon 等.这个时候就需要使用到 PackageManager 这个类了. 本篇就 P ...
- java集合相关问题
1.Map/Set 的 key 为自定义对象时,必须重写 hashCode 和 equals: 2.ArrayList 的 subList 结果不可强转成 ArrayList,否则会抛出 ClassC ...
- 人工智能 tensorflow框架-->简介及安装01
简介:Tensorflow是google于2015年11月开源的第二代机器学习框架. Tensorflow名字理解:图形边中流动的数据叫张量(Tensor),因此叫Tensorflow 既 张量流动 ...
- JFinal快速上手及注意事项
官方手册虽然写的很详细但是忽略的很多小的细节方面,不看源码,网络资料又少,很多新手找不到解决办法.所以养成出了问题,多看源码的习惯 部署helloJFinal 项目结构 - 相关代码 `package ...
- JqueryMobile基础之创建页面
首先简答介绍一下JQueryMobile吧,我觉得用一句话来讲就是可以 "写更少的代码,做更多的事情" : 它可以通过一个灵活及简单的方式来布局网页,且兼容所有移动设备.这也是我自 ...
- input输入框校验,字母,汉字,数字等
<!DOCTYPE html><html><head> <meta charset="utf-8"> <meta http-e ...
- SpringBoot初体验(续)
1.如果你还不知道SpringBoot的厉害之处,或者你不知道SpringBoot的初级用法,请移步我的上一篇文章,传送门 2.SpringBoot中的表单验证 所谓验证,无非就是检验,对比,正如ja ...
- mybatis 参数为list时,校验list是否为空
校验objStatusList 是否为空 <if test="objStatusList != null and objStatusList.size() > 0 "& ...
- Python多进程应用
在我之前的一篇博文中详细介绍了Python多线程的应用: 进程,线程,GIL,Python多线程,生产者消费者模型都是什么鬼 但是由于GIL的存在,使得python多线程没有充分利用CPU的多核,为 ...