Python爬虫知识点四--scrapy框架
一。scrapy结构数据
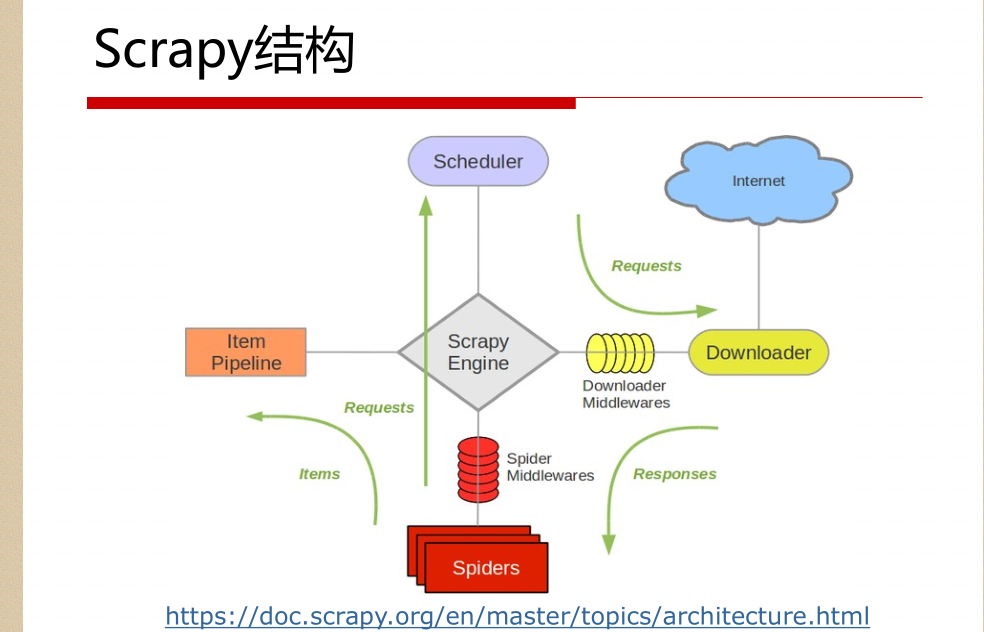
解释:
1.名词解析:
o 引擎(Scrapy Engine)
o 调度器(Scheduler)
o 下载器(Downloader)
o 蜘蛛(Spiders)
o 项目管道(Item Pipeline)
o 下载器中间件(Downloader Middlewares)
o 蜘蛛中间件(Spider Middlewares)
o 调度中间件(Scheduler Middlewares)
2.具体解析
绿线是数据流向
从初始URL开始,Scheduler会将其交给Downloader进
行下载
下载之后会交给Spider进行分析
Spider分析出来的结果有两种
一种是需要进一步抓取的链接,如 “下一页”的链接,它们
会被传回Scheduler;另一种是需要保存的数据,它们被送到Item Pipeline里,进行
后期处理(详细分析、过滤、存储等)。
在数据流动的通道里还可以安装各种中间件,进行必
要的处理。
二。初始化爬虫框架 Scrapy
命令: scrapy startproject qqnews
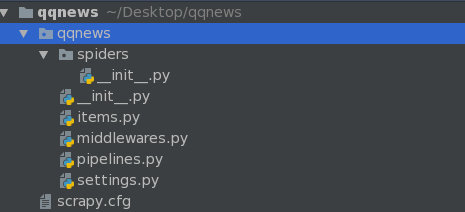
ps:真正的项目是在spiders里面写入的
三。scrapy组件spider
爬取流程
1. 先初始化请求URL列表,并指定下载后处
理response的回调函数。
2. 在parse回调中解析response并返回字典,Item
对象,Request对象或它们的迭代对象。
3 .在回调函数里面,使用选择器解析页面内容
,并生成解析后的结果Item。
4. 最后返回的这些Item通常会被持久化到数据库
中(使用Item Pipeline)或者使用Feed exports将
其保存到文件中。
标准项目结构实例:
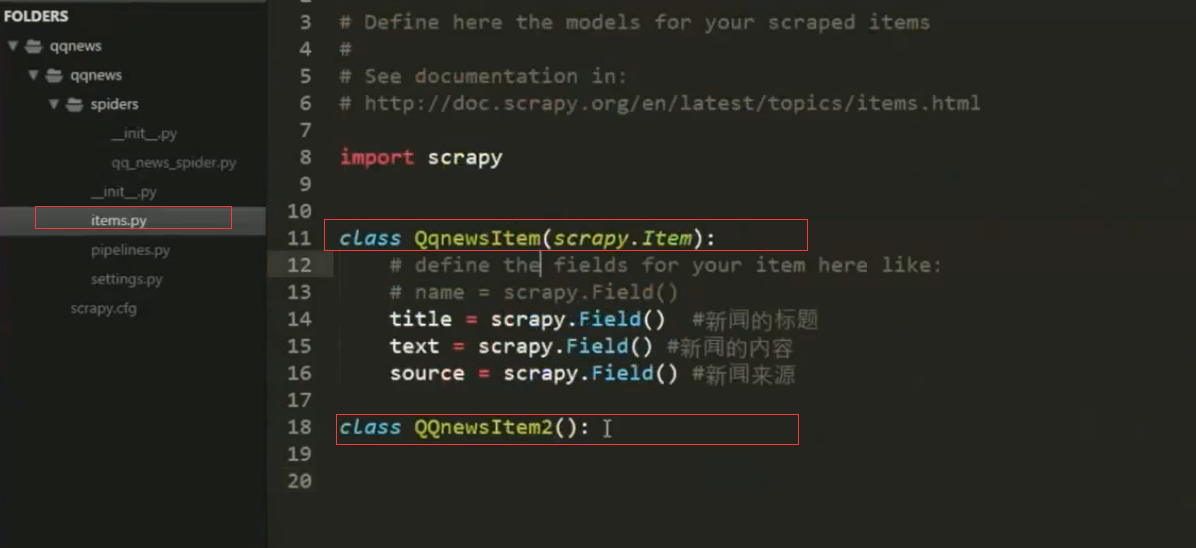
1.items结构:定义变量,根据不同种数据结构定义
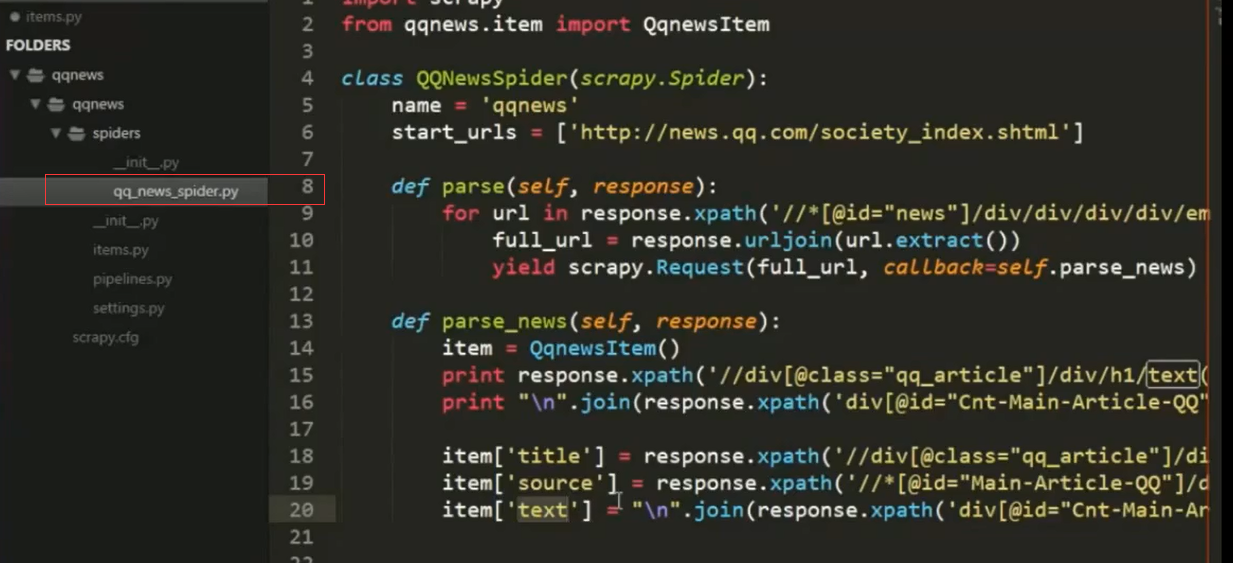
2.spider结构中引入item里面,并作填充item
3。pipline去清洗,验证,存入数据库,过滤等等 后续处理
Item Pipeline常用场景
清理HTML数据
验证被抓取的数据(检查item是否包含某些字段)
重复性检查(然后丢弃)
将抓取的数据存储到数据库中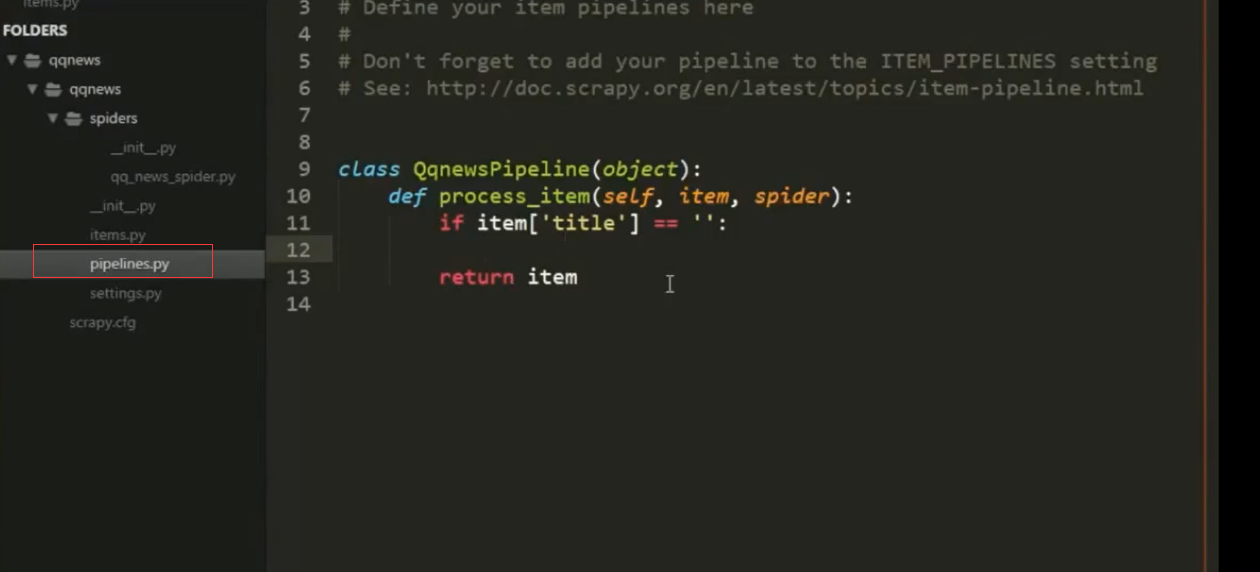
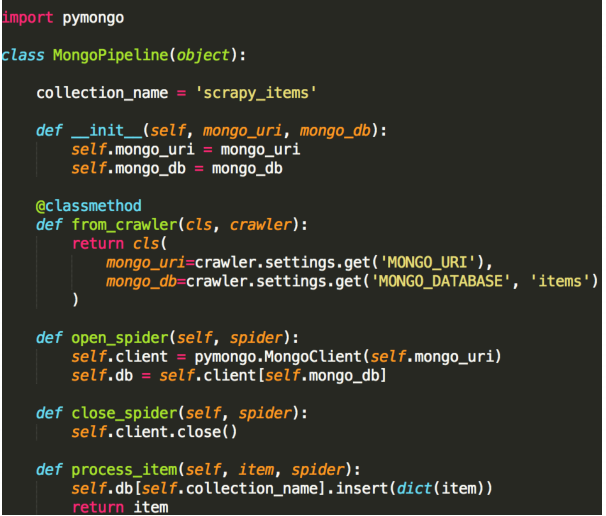
4.Scrapy组件Item Pipeline
经常会实现以下的方法:
open_spider(self, spider) 蜘蛛打开的时执行
close_spider(self, spider) 蜘蛛关闭时执行
from_crawler(cls, crawler) 可访问核心组件比如配置和
信号,并注册钩子函数到Scrapy中
pipeline真正处理逻辑
定义一个Python类,实现方法process_item(self, item,
spider)即可,返回一个字典或Item,或者抛出DropItem
异常丢弃这个Item。
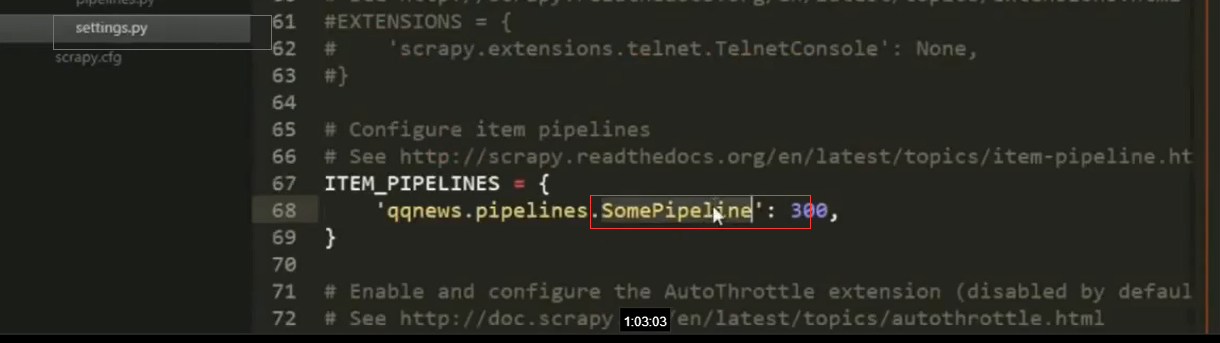
5.settings中定义哪种类型的pipeline
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Python爬虫知识点四--scrapy框架的更多相关文章
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- python爬虫学习之Scrapy框架的工作原理
一.Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网 ...
- PYTHON 爬虫笔记十一:Scrapy框架的基本使用
Scrapy框架详解及其基本使用 scrapy框架原理 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了 ...
- python 爬虫相关含Scrapy框架
1.从酷狗网站爬取 新歌首发的新歌名字.播放时长.链接等 from bs4 import BeautifulSoup as BS import requests import re import js ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- 【Python爬虫实战】Scrapy框架的安装 搬运工亲测有效
windows下亲测有效 http://blog.csdn.net/liuweiyuxiang/article/details/68929999这个我们只是正确操作步骤详解的搬运工
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- Learning Scrapy 中文版翻译 第一章
第一章:scrapy介绍 欢迎来到scrapy之旅.通过这本书,我们将帮助你从只会一点或者零基础的Scrapy初学者达到熟练使用这个强大的框架在互联网或者其他资源抓取海量的数据.在这一章节,我们将给你 ...
- JavaScript之“创意时钟”项目
“时钟展示项目”说明文档(文档尾部附有相应代码) 一.最终效果展示: 二.项目亮点 1.代码结构清晰明了 2.可以实时动态显示当前时间与当前日期 3.界面简洁.美观.大方 4.提高浏览器兼容性 三.知 ...
- JavaScript函数之实际参数对象(arguments) / callee属性 / caller属性 / 递归调用 / 获取函数名称的方法
函数的作用域:调用对象 JavaScript中函数的主体是在局部作用域中执行的,该作用域不同于全局作用域.这个新的作用域是通过将调用对象添加到作用域链的头部而创建的(没怎么理解这句话,有理解的亲可以留 ...
- 【ASP.NET MVC 学习笔记】- 12 Filter
本文参考:http://www.cnblogs.com/willick/p/3331520.html 1.Filter(过滤器)是基于AOP(Aspect-Oriented Programming 面 ...
- PHP简洁之道
前言 前几天在GitHub看到一篇写PHP简洁之道的译文,觉得还不错,所以转在了自己的博客中,只不过有一些地方好像没有翻译,再加上排版上的一些小问题,所以决定自己翻译一遍. 原文地址:https:// ...
- MySQL复制之理论篇
一.MySQL复制概述 MySQL支持两种复制方式:基于行的复制和基于语句的复制(逻辑复制).这两种方式都是通过在主库上记录 二进制日志.在备库重放日志的方式来实现异步的数据复制,其工作原理如下图: ...
- 初识Http协议抓包工具—Fiddler
1.Fiddler简介 Fiddler是用一款使用C#编写的http协议调试代理工具.它支持众多的http调试任务,能够记录并检查所有你的电脑和互联网之间的http通讯,可以设置断点,查看所有的“进出 ...
- c语言15行实现简易cat命令
刚刚和舍友打赌.舍友说PY20行能做xlsx文件分析整理,C20行屁都干不了.我说简单的cat还是能做的嘛.他说不信.我说不处理非文件的参数的话10行能做啊. 下面直接贴代码吧: #include & ...
- Leetcode题解(四)
12/13.Integer to Roman/Roman to Integer 题目 罗马数字规则: 符号 I V X L C D M 数字 1 5 10 50 100 500 1000 代码如下: ...
- FatMouse and Cheese
FatMouse and Cheese Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u ...