爬虫入门 手写一个Java爬虫
本文内容 涞源于 罗刚 老师的 书籍 << 自己动手写网络爬虫一书 >> ;
本文将介绍 1: 网络爬虫的是做什么的? 2: 手动写一个简单的网络爬虫;
1: 网络爬虫是做什么的? 他的主要工作就是 跟据指定的url地址 去发送请求,获得响应, 然后解析响应 , 一方面从响应中查找出想要查找的数据,另一方面从响应中解析出新的URL路径,
然后继续访问,继续解析;继续查找需要的数据和继续解析出新的URL路径 .
这就是网络爬虫主要干的工作. 下面是流程图:
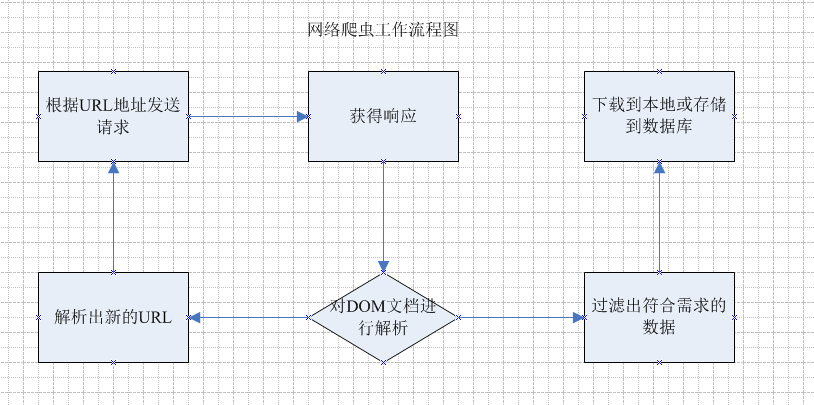
通过上面的流程图 能大概了解到 网络爬虫 干了哪些活 ,根据这些 也就能设计出一个简单的网络爬虫出来.
一个简单的爬虫 必需的功能:
1: 发送请求和获取响应的功能 ;
2: 解析响应的功能 ;
3: 对 过滤出的数据 进行存储 的功能 ;
4: 对解析出来的URL路径 处理的功能 ;
下面是包结构:

下面就上代码:
RequestAndResponseTool 类: 主要方法: 发送请求 返回响应 并把 响应 封装成 page 类 ;
package com.etoak.crawl.page; import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams; import java.io.IOException; public class RequestAndResponseTool { public static Page sendRequstAndGetResponse(String url) {
Page page = null;
// 1.生成 HttpClinet 对象并设置参数
HttpClient httpClient = new HttpClient();
// 设置 HTTP 连接超时 5s
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(5000);
// 2.生成 GetMethod 对象并设置参数
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler());
// 3.执行 HTTP GET 请求
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: " + getMethod.getStatusLine());
}
// 4.处理 HTTP 响应内容
byte[] responseBody = getMethod.getResponseBody();// 读取为字节 数组
String contentType = getMethod.getResponseHeader("Content-Type").getValue(); // 得到当前返回类型
page = new Page(responseBody,url,contentType); //封装成为页面
} catch (HttpException e) {
// 发生致命的异常,可能是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放连接
getMethod.releaseConnection();
}
return page;
}
}
page 类: 主要作用: 保存响应的相关内容 对外提供访问方法;
package com.etoak.crawl.page; import com.etoak.crawl.util.CharsetDetector;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document; import java.io.UnsupportedEncodingException; /*
* page
* 1: 保存获取到的响应的相关内容;
* */
public class Page { private byte[] content ;
private String html ; //网页源码字符串
private Document doc ;//网页Dom文档
private String charset ;//字符编码
private String url ;//url路径
private String contentType ;// 内容类型 public Page(byte[] content , String url , String contentType){
this.content = content ;
this.url = url ;
this.contentType = contentType ;
} public String getCharset() {
return charset;
}
public String getUrl(){return url ;}
public String getContentType(){ return contentType ;}
public byte[] getContent(){ return content ;} /**
* 返回网页的源码字符串
*
* @return 网页的源码字符串
*/
public String getHtml() {
if (html != null) {
return html;
}
if (content == null) {
return null;
}
if(charset==null){
charset = CharsetDetector.guessEncoding(content); // 根据内容来猜测 字符编码
}
try {
this.html = new String(content, charset);
return html;
} catch (UnsupportedEncodingException ex) {
ex.printStackTrace();
return null;
}
} /*
* 得到文档
* */
public Document getDoc(){
if (doc != null) {
return doc;
}
try {
this.doc = Jsoup.parse(getHtml(), url);
return doc;
} catch (Exception ex) {
ex.printStackTrace();
return null;
}
} }
PageParserTool: 类 主要作用 提供了 根据选择器来选取元素 属性 等方法 ;
package com.etoak.crawl.page; import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import java.util.ArrayList;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set; public class PageParserTool { /* 通过选择器来选取页面的 */
public static Elements select(Page page , String cssSelector) {
return page.getDoc().select(cssSelector);
} /*
* 通过css选择器来得到指定元素;
*
* */
public static Element select(Page page , String cssSelector, int index) {
Elements eles = select(page , cssSelector);
int realIndex = index;
if (index < 0) {
realIndex = eles.size() + index;
}
return eles.get(realIndex);
} /**
* 获取满足选择器的元素中的链接 选择器cssSelector必须定位到具体的超链接
* 例如我们想抽取id为content的div中的所有超链接,这里
* 就要将cssSelector定义为div[id=content] a
* 放入set 中 防止重复;
* @param cssSelector
* @return
*/
public static Set<String> getLinks(Page page ,String cssSelector) {
Set<String> links = new HashSet<String>() ;
Elements es = select(page , cssSelector);
Iterator iterator = es.iterator();
while(iterator.hasNext()) {
Element element = (Element) iterator.next();
if ( element.hasAttr("href") ) {
links.add(element.attr("abs:href"));
}else if( element.hasAttr("src") ){
links.add(element.attr("abs:src"));
}
}
return links;
} /**
* 获取网页中满足指定css选择器的所有元素的指定属性的集合
* 例如通过getAttrs("img[src]","abs:src")可获取网页中所有图片的链接
* @param cssSelector
* @param attrName
* @return
*/
public static ArrayList<String> getAttrs(Page page , String cssSelector, String attrName) {
ArrayList<String> result = new ArrayList<String>();
Elements eles = select(page ,cssSelector);
for (Element ele : eles) {
if (ele.hasAttr(attrName)) {
result.add(ele.attr(attrName));
}
}
return result;
}
}
Link 包 ;
Links 类: 两个属性: 一个是存放 已经访问的url集合的set ; 一个是存放待访问url集合的 queue ;
package com.etoak.crawl.link; import java.util.HashSet;
import java.util.LinkedList;
import java.util.Set; /*
* Link主要功能;
* 1: 存储已经访问过的URL路径 和 待访问的URL 路径;
*
*
* */
public class Links { //已访问的 url 集合 已经访问过的 主要考虑 不能再重复了 使用set来保证不重复;
private static Set visitedUrlSet = new HashSet(); //待访问的 url 集合 待访问的主要考虑 1:规定访问顺序;2:保证不提供重复的带访问地址;
private static LinkedList unVisitedUrlQueue = new LinkedList(); //获得已经访问的 URL 数目
public static int getVisitedUrlNum() {
return visitedUrlSet.size();
} //添加到访问过的 URL
public static void addVisitedUrlSet(String url) {
visitedUrlSet.add(url);
} //移除访问过的 URL
public static void removeVisitedUrlSet(String url) {
visitedUrlSet.remove(url);
} //获得 待访问的 url 集合
public static LinkedList getUnVisitedUrlQueue() {
return unVisitedUrlQueue;
} // 添加到待访问的集合中 保证每个 URL 只被访问一次
public static void addUnvisitedUrlQueue(String url) {
if (url != null && !url.trim().equals("") && !visitedUrlSet.contains(url) && !unVisitedUrlQueue.contains(url)){
unVisitedUrlQueue.add(url);
}
} //删除 待访问的url
public static Object removeHeadOfUnVisitedUrlQueue() {
return unVisitedUrlQueue.removeFirst();
} //判断未访问的 URL 队列中是否为空
public static boolean unVisitedUrlQueueIsEmpty() {
return unVisitedUrlQueue.isEmpty();
} }
LinkFilter 接口: 可以起过滤作用;
package com.etoak.crawl.link;
public interface LinkFilter {
public boolean accept(String url);
}
util 工具类
CharsetDetector 类; 获取字符编码
/*
* Copyright (C) 2014 hu
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
*/
package com.etoak.crawl.util; import org.mozilla.universalchardet.UniversalDetector; import java.io.UnsupportedEncodingException;
import java.util.regex.Matcher;
import java.util.regex.Pattern; /**
* 字符集自动检测
*
* @author hu
*/
public class CharsetDetector { //从Nutch借鉴的网页编码检测代码
private static final int CHUNK_SIZE = 2000; private static Pattern metaPattern = Pattern.compile(
"<meta\\s+([^>]*http-equiv=(\"|')?content-type(\"|')?[^>]*)>",
Pattern.CASE_INSENSITIVE);
private static Pattern charsetPattern = Pattern.compile(
"charset=\\s*([a-z][_\\-0-9a-z]*)", Pattern.CASE_INSENSITIVE);
private static Pattern charsetPatternHTML5 = Pattern.compile(
"<meta\\s+charset\\s*=\\s*[\"']?([a-z][_\\-0-9a-z]*)[^>]*>",
Pattern.CASE_INSENSITIVE); //从Nutch借鉴的网页编码检测代码
private static String guessEncodingByNutch(byte[] content) {
int length = Math.min(content.length, CHUNK_SIZE); String str = "";
try {
str = new String(content, "ascii");
} catch (UnsupportedEncodingException e) {
return null;
} Matcher metaMatcher = metaPattern.matcher(str);
String encoding = null;
if (metaMatcher.find()) {
Matcher charsetMatcher = charsetPattern.matcher(metaMatcher.group(1));
if (charsetMatcher.find()) {
encoding = new String(charsetMatcher.group(1));
}
}
if (encoding == null) {
metaMatcher = charsetPatternHTML5.matcher(str);
if (metaMatcher.find()) {
encoding = new String(metaMatcher.group(1));
}
}
if (encoding == null) {
if (length >= 3 && content[0] == (byte) 0xEF
&& content[1] == (byte) 0xBB && content[2] == (byte) 0xBF) {
encoding = "UTF-8";
} else if (length >= 2) {
if (content[0] == (byte) 0xFF && content[1] == (byte) 0xFE) {
encoding = "UTF-16LE";
} else if (content[0] == (byte) 0xFE
&& content[1] == (byte) 0xFF) {
encoding = "UTF-16BE";
}
}
} return encoding;
} /**
* 根据字节数组,猜测可能的字符集,如果检测失败,返回utf-8
*
* @param bytes 待检测的字节数组
* @return 可能的字符集,如果检测失败,返回utf-8
*/
public static String guessEncodingByMozilla(byte[] bytes) {
String DEFAULT_ENCODING = "UTF-8";
UniversalDetector detector = new UniversalDetector(null);
detector.handleData(bytes, 0, bytes.length);
detector.dataEnd();
String encoding = detector.getDetectedCharset();
detector.reset();
if (encoding == null) {
encoding = DEFAULT_ENCODING;
}
return encoding;
} /**
* 根据字节数组,猜测可能的字符集,如果检测失败,返回utf-8
* @param content 待检测的字节数组
* @return 可能的字符集,如果检测失败,返回utf-8
*/
public static String guessEncoding(byte[] content) {
String encoding;
try {
encoding = guessEncodingByNutch(content);
} catch (Exception ex) {
return guessEncodingByMozilla(content);
} if (encoding == null) {
encoding = guessEncodingByMozilla(content);
return encoding;
} else {
return encoding;
}
}
}
FileTool 文件下载类:
package com.etoak.crawl.util; import com.etoak.crawl.page.Page; import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException; /* 本类主要是 下载那些已经访问过的文件*/
public class FileTool { private static String dirPath; /**
* getMethod.getResponseHeader("Content-Type").getValue()
* 根据 URL 和网页类型生成需要保存的网页的文件名,去除 URL 中的非文件名字符
*/
private static String getFileNameByUrl(String url, String contentType) {
//去除 http://
url = url.substring(7);
//text/html 类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|<>\"]", "_") + ".html";
return url;
}
//如 application/pdf 类型
else {
return url.replaceAll("[\\?/:*|<>\"]", "_") + "." +
contentType.substring(contentType.lastIndexOf("/") + 1);
}
} /*
* 生成目录
* */
private static void mkdir() {
if (dirPath == null) {
dirPath = Class.class.getClass().getResource("/").getPath() + "temp\\";
}
File fileDir = new File(dirPath);
if (!fileDir.exists()) {
fileDir.mkdir();
}
} /**
* 保存网页字节数组到本地文件,filePath 为要保存的文件的相对地址
*/ public static void saveToLocal(Page page) {
mkdir();
String fileName = getFileNameByUrl(page.getUrl(), page.getContentType()) ;
String filePath = dirPath + fileName ;
byte[] data = page.getContent();
try {
//Files.lines(Paths.get("D:\\jd.txt"), StandardCharsets.UTF_8).forEach(System.out::println);
DataOutputStream out = new DataOutputStream(new FileOutputStream(new File(filePath)));
// for (int i = 0; i < data.length; i++) {
// out.write(data[i]);
// }
out.write(data);
out.flush();
out.close();
System.out.println("文件:"+ fileName + "已经被存储在"+ filePath );
} catch (IOException e) {
e.printStackTrace();
}
} }
RegexRule 正则表达式类;
/*
* Copyright (C) 2014 hu
*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version 2
* of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program; if not, write to the Free Software
* Foundation, Inc., 59 Temple Place - Suite 330, Boston, MA 02111-1307, USA.
*/
package com.etoak.crawl.util; import java.util.ArrayList;
import java.util.regex.Pattern; /**
*
* @author hu
*/
public class RegexRule { public RegexRule(){ }
public RegexRule(String rule){
addRule(rule);
} public RegexRule(ArrayList<String> rules){
for (String rule : rules) {
addRule(rule);
}
} public boolean isEmpty(){
return positive.isEmpty();
} private ArrayList<String> positive = new ArrayList<String>();
private ArrayList<String> negative = new ArrayList<String>(); /**
* 添加一个正则规则 正则规则有两种,正正则和反正则
* URL符合正则规则需要满足下面条件: 1.至少能匹配一条正正则 2.不能和任何反正则匹配
* 正正则示例:+a.*c是一条正正则,正则的内容为a.*c,起始加号表示正正则
* 反正则示例:-a.*c时一条反正则,正则的内容为a.*c,起始减号表示反正则
* 如果一个规则的起始字符不为加号且不为减号,则该正则为正正则,正则的内容为自身
* 例如a.*c是一条正正则,正则的内容为a.*c
* @param rule 正则规则
* @return 自身
*/
public RegexRule addRule(String rule) {
if (rule.length() == 0) {
return this;
}
char pn = rule.charAt(0);
String realrule = rule.substring(1);
if (pn == '+') {
addPositive(realrule);
} else if (pn == '-') {
addNegative(realrule);
} else {
addPositive(rule);
}
return this;
} /**
* 添加一个正正则规则
* @param positiveregex
* @return 自身
*/
public RegexRule addPositive(String positiveregex) {
positive.add(positiveregex);
return this;
} /**
* 添加一个反正则规则
* @param negativeregex
* @return 自身
*/
public RegexRule addNegative(String negativeregex) {
negative.add(negativeregex);
return this;
} /**
* 判断输入字符串是否符合正则规则
* @param str 输入的字符串
* @return 输入字符串是否符合正则规则
*/
public boolean satisfy(String str) { int state = 0;
for (String nregex : negative) {
if (Pattern.matches(nregex, str)) {
return false;
}
} int count = 0;
for (String pregex : positive) {
if (Pattern.matches(pregex, str)) {
count++;
}
}
if (count == 0) {
return false;
} else {
return true;
} }
}
主类:
MyCrawler :
package com.etoak.crawl.main; import com.etoak.crawl.link.LinkFilter;
import com.etoak.crawl.link.Links;
import com.etoak.crawl.page.Page;
import com.etoak.crawl.page.PageParserTool;
import com.etoak.crawl.page.RequestAndResponseTool;
import com.etoak.crawl.util.FileTool;
import org.jsoup.select.Elements; import java.util.Set; public class MyCrawler { /**
* 使用种子初始化 URL 队列
*
* @param seeds 种子 URL
* @return
*/
private void initCrawlerWithSeeds(String[] seeds) {
for (int i = 0; i < seeds.length; i++){
Links.addUnvisitedUrlQueue(seeds[i]);
}
} /**
* 抓取过程
*
* @param seeds
* @return
*/
public void crawling(String[] seeds) { //初始化 URL 队列
initCrawlerWithSeeds(seeds); //定义过滤器,提取以 http://www.baidu.com 开头的链接
LinkFilter filter = new LinkFilter() {
public boolean accept(String url) {
if (url.startsWith("http://www.baidu.com"))
return true;
else
return false;
}
}; //循环条件:待抓取的链接不空且抓取的网页不多于 1000
while (!Links.unVisitedUrlQueueIsEmpty() && Links.getVisitedUrlNum() <= 1000) { //先从待访问的序列中取出第一个;
String visitUrl = (String) Links.removeHeadOfUnVisitedUrlQueue();
if (visitUrl == null){
continue;
} //根据URL得到page;
Page page = RequestAndResponseTool.sendRequstAndGetResponse(visitUrl); //对page进行处理: 访问DOM的某个标签
Elements es = PageParserTool.select(page,"a");
if(!es.isEmpty()){
System.out.println("下面将打印所有a标签: ");
System.out.println(es);
} //将保存文件
FileTool.saveToLocal(page); //将已经访问过的链接放入已访问的链接中;
Links.addVisitedUrlSet(visitUrl); //得到超链接
Set<String> links = PageParserTool.getLinks(page,"img");
for (String link : links) {
Links.addUnvisitedUrlQueue(link);
System.out.println("新增爬取路径: " + link);
}
}
} //main 方法入口
public static void main(String[] args) {
MyCrawler crawler = new MyCrawler();
crawler.crawling(new String[]{"http://www.baidu.com"});
}
}
运行结果:

源码下载链接: https://pan.baidu.com/s/1ge7Nkzx 下载密码: mz5b 文章主要参考: 1: 自己动手写网络爬虫;
2: https://github.com/CrawlScript/WebCollector
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。
爬虫入门 手写一个Java爬虫的更多相关文章
- 手写一个Java程序输出HelloWorld
` 创建一个Hello.java文件使用记事本打开 public class Hello{ public static void main(String [] args){ System.out.pr ...
- webmagic的设计机制及原理-如何开发一个Java爬虫 转
此文章是webmagic 0.1.0版的设计手册,后续版本的入门及用户手册请看这里:https://github.com/code4craft/webmagic/blob/master/user-ma ...
- webmagic的设计机制及原理-如何开发一个Java爬虫
之前就有网友在博客里留言,觉得webmagic的实现比较有意思,想要借此研究一下爬虫.最近终于集中精力,花了三天时间,终于写完了这篇文章.之前垂直爬虫写了一年多,webmagic框架写了一个多月,这方 ...
- 教你如何使用Java手写一个基于链表的队列
在上一篇博客[教你如何使用Java手写一个基于数组的队列]中已经介绍了队列,以及Java语言中对队列的实现,对队列不是很了解的可以我上一篇文章.那么,现在就直接进入主题吧. 这篇博客主要讲解的是如何使 ...
- Python之小测试:用正则表达式写一个小爬虫用于保存贴吧里的所有图片
很简单的两步: 1.获取网页源代码 2.利用正则表达式提取出图片地址 3.下载 #!/usr/bin/python #coding=utf8 import re # 正则表达式 import urll ...
- 搞定redis面试--Redis的过期策略?手写一个LRU?
1 面试题 Redis的过期策略都有哪些?内存淘汰机制都有哪些?手写一下LRU代码实现? 2 考点分析 1)我往redis里写的数据怎么没了? 我们生产环境的redis怎么经常会丢掉一些数据?写进去了 ...
- 【spring】-- 手写一个最简单的IOC框架
1.什么是springIOC IOC就是把每一个bean(实体类)与bean(实体了)之间的关系交给第三方容器进行管理. 如果我们手写一个最最简单的IOC,最终效果是怎样呢? xml配置: <b ...
- 利用SpringBoot+Logback手写一个简单的链路追踪
目录 一.实现原理 二.代码实战 三.测试 最近线上排查问题时候,发现请求太多导致日志错综复杂,没办法把用户在一次或多次请求的日志关联在一起,所以就利用SpringBoot+Logback手写了一个简 ...
- 看年薪50W的架构师如何手写一个SpringMVC框架
前言 做 Java Web 开发的你,一定听说过SpringMVC的大名,作为现在运用最广泛的Java框架,它到目前为止依然保持着强大的活力和广泛的用户群. 本文介绍如何用eclipse一步一步搭建S ...
随机推荐
- Hadoop就是一个别人造好的轮子
这个想法源自于我看了<Hadoop: The Definitive Guide>的Part I Ch 2中MapReduce的引入和介绍,书中先说了怎么通过原始的办法处理数据,然后引入到如 ...
- Python自学笔记-with详解
with的作用: with关键字是一个替你管理实现上下文协议对象的东西,适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的"清理"操作,释放资源,比如文件使用 ...
- ubuntu中运行python脚本
1. 运行方式一 新建test.py文件: touch test.py 然后vim test.py打开并编辑: print 'Hello World' 打开终端,输入命令: python test.p ...
- struts2中的结果视图类型
实际上在Struts2框架中,一个完整的结果视图配置文件应该是: <action name="Action名称" class="Action类路径" me ...
- CodeSmith(C#)简单示例及相关小知识
// 本文将介绍CodeSmith与数据库进行交互生成相应的存储过程,本例使用的数据库为SQL Server 2000. // 在与数据库进行交互时,我们使用到了一个CodeSmith自带的组件Sch ...
- Echarts数据可视化series-graph关系图,开发全解+完美注释
全栈工程师开发手册 (作者:栾鹏) Echarts数据可视化开发代码注释全解 Echarts数据可视化开发参数配置全解 6大公共组件详解(点击进入): title详解. tooltip详解.toolb ...
- 从零开始教你封装自己的vue组件
组件(component)是vue.js最强大的功能之一,它可以实现功能的复用,以及对其他逻辑的解耦.但经过一段时间的使用,我发现自己并没有在业务中发挥出组件的最大价值.相信很多刚开始使用vue的朋友 ...
- 解决Ubuntu中phpmyadmin对数据上传上限2M
本文部分参考自:http://www.myhack58.com/Article/sort099/sort0102/2011/29396.htm 原文有少量错误或者过时的(相对于ubuntu15来说)内 ...
- Android实现购物车功能
如图: 主要代码如下: actvity中的代码: publicclassShoppingCartActivity extendsBaseActivity { private List< ...
- Django数据库操作性能相关
Django数据库操作性能相关 案例: 现在我们的数据库中有两张表如下: 1.职员表: class UserInfo(models.Model): name = models.CharField(ma ...