Hadoop之HDFS原理及文件上传下载源码分析(下)
上篇Hadoop之HDFS原理及文件上传下载源码分析(上)楼主主要介绍了hdfs原理及FileSystem的初始化源码解析, Client如何与NameNode建立RPC通信。本篇将继续介绍hdfs文件上传、下载源解析。
文件上传
先上文件上传的方法调用过程时序图:
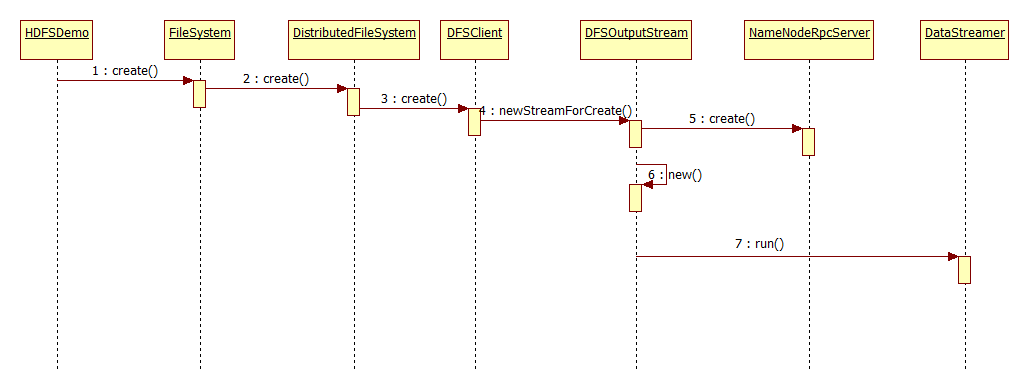
其主要执行过程:
- FileSystem初始化,Client拿到NameNodeRpcServer代理对象,建立与NameNode的RPC通信(楼主上篇已经介绍过了)
- 调用FileSystem的create()方法,由于实现类为DistributedFileSystem,所有是调用该类中的create()方法
- DistributedFileSystem持有DFSClient的引用,继续调用DFSClient中的create()方法
- DFSOutputStream提供的静态newStreamForCreate()方法中调用NameNodeRpcServer服务端的create()方法并创建DFSOutputStream输出流对象返回
- 通过hadoop提供的IOUtil工具类将输出流输出到本地
下面我们来看下源码:
首先初始化文件系统,建立与服务端的RPC通信
HDFSDemo.java
OutputStream os = fs.create(new Path("/test.log"));
调用FileSystem的create()方法,由于FileSystem是一个抽象类,这里实际上是调用的该类的子类create()方法
//FileSystem.java
public abstract FSDataOutputStream create(Path f,
FsPermission permission,
boolean overwrite,
int bufferSize,
short replication,
long blockSize,
Progressable progress) throws IOException;
前面我们已经说过FileSystem.get()返回的是DistributedFileSystem对象,所以这里我们直接进入DistributedFileSystem:
//DistributedFileSystem.java
@Override
public FSDataOutputStream create(final Path f, final FsPermission permission,
final EnumSet<CreateFlag> cflags, final int bufferSize,
final short replication, final long blockSize, final Progressable progress,
final ChecksumOpt checksumOpt) throws IOException {
statistics.incrementWriteOps(1);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver<FSDataOutputStream>() {
@Override
public FSDataOutputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,
cflags, replication, blockSize, progress, bufferSize,
checksumOpt);
//dfs为DistributedFileSystem所持有的DFSClient对象,这里调用DFSClient中的create()方法
return dfs.createWrappedOutputStream(dfsos, statistics);
}
@Override
public FSDataOutputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.create(p, permission, cflags, bufferSize,
replication, blockSize, progress, checksumOpt);
}
}.resolve(this, absF);
}
DFSClient的create()返回一个DFSOutputStream对象:
//DFSClient.java
public DFSOutputStream create(String src,
FsPermission permission,
EnumSet<CreateFlag> flag,
boolean createParent,
short replication,
long blockSize,
Progressable progress,
int buffersize,
ChecksumOpt checksumOpt,
InetSocketAddress[] favoredNodes) throws IOException {
checkOpen();
if (permission == null) {
permission = FsPermission.getFileDefault();
}
FsPermission masked = permission.applyUMask(dfsClientConf.uMask);
if(LOG.isDebugEnabled()) {
LOG.debug(src + ": masked=" + masked);
}
//调用DFSOutputStream的静态方法newStreamForCreate,返回输出流
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
src, masked, flag, createParent, replication, blockSize, progress,
buffersize, dfsClientConf.createChecksum(checksumOpt),
getFavoredNodesStr(favoredNodes));
beginFileLease(result.getFileId(), result);
return result;
}
我们继续看下newStreamForCreate()中的业务逻辑:
//DFSOutputStream.java
static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,
FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,
short replication, long blockSize, Progressable progress, int buffersize,
DataChecksum checksum, String[] favoredNodes) throws IOException {
TraceScope scope =
dfsClient.getPathTraceScope("newStreamForCreate", src);
try {
HdfsFileStatus stat = null;
boolean shouldRetry = true;
int retryCount = CREATE_RETRY_COUNT;
while (shouldRetry) {
shouldRetry = false;
try {
//这里通过dfsClient的NameNode代理对象调用NameNodeRpcServer中实现的create()方法
stat = dfsClient.namenode.create(src, masked, dfsClient.clientName,
new EnumSetWritable<CreateFlag>(flag), createParent, replication,
blockSize, SUPPORTED_CRYPTO_VERSIONS);
break;
} catch (RemoteException re) {
IOException e = re.unwrapRemoteException(
AccessControlException.class,
DSQuotaExceededException.class,
FileAlreadyExistsException.class,
FileNotFoundException.class,
ParentNotDirectoryException.class,
NSQuotaExceededException.class,
RetryStartFileException.class,
SafeModeException.class,
UnresolvedPathException.class,
SnapshotAccessControlException.class,
UnknownCryptoProtocolVersionException.class);
if (e instanceof RetryStartFileException) {
if (retryCount > 0) {
shouldRetry = true;
retryCount--;
} else {
throw new IOException("Too many retries because of encryption" +
" zone operations", e);
}
} else {
throw e;
}
}
}
Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");
//new输出流对象
final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,
flag, progress, checksum, favoredNodes);
out.start();//调用内部类DataStreamer的start()方法,DataStreamer继承Thread,所以说这是一个线程,从NameNode中申请新的block信息;
同时前面我们介绍hdfs原理的时候提到的流水线作业(Pipeline)也是在这里实现,有兴趣的同学可以去研究下,这里就不带大家看了
return out;
} finally {
scope.close();
}
}
到此,Client拿到了服务端的输出流对象,那么后面就容易了,都是一些简答的文件输出,输入流的操作(hadoop提供的IOUitl)。
文件下载
文件上传的大致流程与文件下载类似,与上传一样,我们先上程序方法调用时序图:
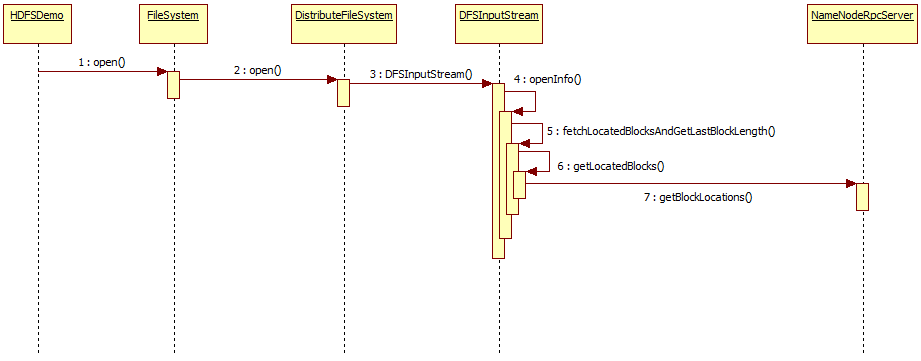
主要执行过程:
- FileSystem初始化,Client拿到NameNodeRpcServer代理对象,建立与NameNode的RPC通信(与前面一样)
- 调用FileSystem的open()方法,由于实现类为DistributedFileSystem,所有是调用该类中的open()方法
- DistributedFileSystem持有DFSClient的引用,继续调用DFSClient中的open()方法
- 实例化DFSInputStream输入流
- 调用openinfo()方法
- 调用fetchLocatedBlocksAndGetLastBlockLength()方法,抓取block信息并获取最后block长度
- 调用DFSClient中的getLocatedBlocks()方法,获取block信息
- 在callGetBlockLocations()方法中通过NameNode代理对象调用NameNodeRpcServer的getBlockLocations()方法
- 将block信息写入输出流
- 交给IOUtil,下载文件到本地
接下来,我们开始看源码:
首先任然是FileSystem的初始化,前面有,这里就不贴出来了,我们直接从DistributedFileSystem的open()开始看。
//DistributedFifeSystem.java
@Override
public FSDataInputStream open(Path f, final int bufferSize)
throws IOException {
statistics.incrementReadOps(1);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver<FSDataInputStream>() {
@Override
public FSDataInputStream doCall(final Path p)
throws IOException, UnresolvedLinkException {
final DFSInputStream dfsis =
dfs.open(getPathName(p), bufferSize, verifyChecksum);
//dfs为DFSClient对象,调用open()返回输入流
return dfs.createWrappedInputStream(dfsis);
}
@Override
public FSDataInputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.open(p, bufferSize);
}
}.resolve(this, absF);
}
DFSClient中并没有直接使用NameNode的代理对象,而是传给了DFSInputStream:
//DFSClient.java
public DFSInputStream open(String src, int buffersize, boolean verifyChecksum)
throws IOException, UnresolvedLinkException {
checkOpen();
TraceScope scope = getPathTraceScope("newDFSInputStream", src);
try {
//这里并没有直接通过NameNode的代理对象调用服务端的方法,直接new输入流并把当前对象作为参数传入
return new DFSInputStream(this, src, verifyChecksum);
} finally {
scope.close();
}
}
那么在DFSInputStream必须持有DFSClient的引用:
//DFSInputStream.java 构造
DFSInputStream(DFSClient dfsClient, String src, boolean verifyChecksum
) throws IOException, UnresolvedLinkException {
this.dfsClient = dfsClient;//只有DFSClient的引用
this.verifyChecksum = verifyChecksum;
this.src = src;
synchronized (infoLock) {
this.cachingStrategy = dfsClient.getDefaultReadCachingStrategy();
}
openInfo();//调openInfo()
}
openInfo()用来抓取block信息:
void openInfo() throws IOException, UnresolvedLinkException {
synchronized(infoLock) {
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();//抓取block信息
int retriesForLastBlockLength = dfsClient.getConf().retryTimesForGetLastBlockLength;//获取配置信息,尝试抓取的次数,楼主记得在2.6以前这里写的3;当然,现在的默认值也为3
while (retriesForLastBlockLength > 0) {
if (lastBlockBeingWrittenLength == -1) {
DFSClient.LOG.warn("Last block locations not available. "
+ "Datanodes might not have reported blocks completely."
+ " Will retry for " + retriesForLastBlockLength + " times");
waitFor(dfsClient.getConf().retryIntervalForGetLastBlockLength);
lastBlockBeingWrittenLength = fetchLocatedBlocksAndGetLastBlockLength();
} else {
break;
}
retriesForLastBlockLength--;
}
if (retriesForLastBlockLength == 0) {
throw new IOException("Could not obtain the last block locations.");
}
}
}
获取block信息:
//DFSInputStream.java
private long fetchLocatedBlocksAndGetLastBlockLength() throws IOException {
final LocatedBlocks newInfo = dfsClient.getLocatedBlocks(src, 0);
//回到DFSClient中来获取当前block信息
if (DFSClient.LOG.isDebugEnabled()) {
DFSClient.LOG.debug("newInfo = " + newInfo);
}
if (newInfo == null) {
throw new IOException("Cannot open filename " + src);
} if (locatedBlocks != null) {
Iterator<LocatedBlock> oldIter = locatedBlocks.getLocatedBlocks().iterator();
Iterator<LocatedBlock> newIter = newInfo.getLocatedBlocks().iterator();
while (oldIter.hasNext() && newIter.hasNext()) {
if (! oldIter.next().getBlock().equals(newIter.next().getBlock())) {
throw new IOException("Blocklist for " + src + " has changed!");
}
}
}
locatedBlocks = newInfo;
long lastBlockBeingWrittenLength = 0;
if (!locatedBlocks.isLastBlockComplete()) {
final LocatedBlock last = locatedBlocks.getLastLocatedBlock();
if (last != null) {
if (last.getLocations().length == 0) {
if (last.getBlockSize() == 0) {
return 0;
}
return -1;
}
final long len = readBlockLength(last);
last.getBlock().setNumBytes(len);
lastBlockBeingWrittenLength = len;
}
} fileEncryptionInfo = locatedBlocks.getFileEncryptionInfo();
//返回block开始写的位置
return lastBlockBeingWrittenLength;
}
回到DFSClient中:
DFSClient.java
@VisibleForTesting
public LocatedBlocks getLocatedBlocks(String src, long start, long length)
throws IOException {
TraceScope scope = getPathTraceScope("getBlockLocations", src);
try {
//这里NameNode作为参数传递到callGetBlockLocations()中
return callGetBlockLocations(namenode, src, start, length);
} finally {
scope.close();
}
}
调用服务端方法,返回block信息:
//DFSClient.java
static LocatedBlocks callGetBlockLocations(ClientProtocol namenode,
String src, long start, long length)
throws IOException {
try {
//看到这里,不用做过多的解释了吧?
return namenode.getBlockLocations(src, start, length);
} catch(RemoteException re) {
throw re.unwrapRemoteException(AccessControlException.class,
FileNotFoundException.class,
UnresolvedPathException.class);
}
}
最终将文件block相关信息写入输入流,通过工具类IOUtil输出到本地文件。
那关于hadoop之hdfs原理及文件上传下载源码解析就写到这里,下系列的文章,楼主会写一些关于mapreduce或者hive相关的文章分享给大家。
示例代码地址:https://github.com/LJunChina/hadoop
Hadoop之HDFS原理及文件上传下载源码分析(下)的更多相关文章
- Hadoop之HDFS原理及文件上传下载源码分析(上)
HDFS原理 首先说明下,hadoop的各种搭建方式不再介绍,相信各位玩hadoop的同学随便都能搭出来. 楼主的环境: 操作系统:Ubuntu 15.10 hadoop版本:2.7.3 HA:否(随 ...
- php实现文件上传的源码
php实现文件上传的源码,更多php技术开发就去php教程网,http://php.662p.com <?php ##author :Androidyue ##sina @androidyue ...
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(32)-swfupload多文件上传[附源码]
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(32)-swfupload多文件上传[附源码] 文件上传这东西说到底有时候很痛,原来的asp.net服务器 ...
- swfupload多文件上传[附源码]
swfupload多文件上传[附源码] 文件上传这东西说到底有时候很痛,原来的asp.net服务器控件提供了很简单的上传,但是有回传,还没有进度条提示.这次我们演示利用swfupload多文件上传,项 ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(32)-swfupload多文件上传[附源码]
系列目录 文件上传这东西说到底有时候很痛,原来的asp.net服务器控件提供了很简单的上传,但是有回传,还没有进度条提示.这次我们演示利用swfupload多文件上传,项目上文件上传是比不可少的,大家 ...
- web大文件上传断点续传源码
总结一下大文件分片上传和断点续传的问题.因为文件过大(比如1G以上),必须要考虑上传过程网络中断的情况.http的网络请求中本身就已经具备了分片上传功能,当传输的文件比较大时,http协议自动会将文件 ...
- PHP大文件上传断点续传源码
文件夹数据库处理逻辑 publicclass DbFolder { JSONObject root; public DbFolder() { this.root = new JSONObject(); ...
- element-ui Upload 上传组件源码分析整理笔记(十四)
简单写了部分注释,upload-dragger.vue(拖拽上传时显示此组件).upload-list.vue(已上传文件列表)源码暂未添加多少注释,等有空再补充,先记下来... index.vue ...
- .net大文件上传断点续传源码
IE的自带下载功能中没有断点续传功能,要实现断点续传功能,需要用到HTTP协议中鲜为人知的几个响应头和请求头. 一. 两个必要响应头Accept-Ranges.ETag 客户端每次提交下载请求时,服务 ...
随机推荐
- CentOs下安装PHP环境的步骤
前言 在CentOs环境下安装php开发环境,需要首先安装一些源文件,然后使用yum命令直接安装即可,在Fedora 20 源中已经有了PHP的源,直接可以使用以下命令安装即可: # yum inst ...
- 分享小知识:善用Group By排序
以下列举了公用表/临时表/聚合函数三个因素为例子(覆盖索引因素除外,有利用此类索引都会以索引顺序) 环境: Microsoft SQL Server 2014 (SP1-GDR) (KB319472 ...
- JavaScript数据结构——队列的实现
前面楼主简单介绍了JavaScript数据结构栈的实现,http://www.cnblogs.com/qq503665965/p/6537894.html,本次将介绍队列的实现. 队列是一种特殊的线性 ...
- java 文件操作(二)---Files和Path
自从java 7以来,引入了FIles类和Path接口.他们两封装了用户对文件的所有可能的操作,相比于java 1的File类来说,使用起来方便很多.但是其实一些本质的操作还是很类似的.主要需要知道的 ...
- 【记录】解析具有合并单元格的Excel
最近公司让做各种数据表格的导入导出,就涉及到电子表格的解析,做了这么多天总结一下心得. 工具:NOPI 语言:C# 目的:因为涉及到导入到数据库,具有合并单元格的多行必然要拆分,而NPOI自动解析的时 ...
- vue组件递归
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Sublime Text3 编辑器我的最爱
简介 Sublime Text 3是一个神奇的文本编辑器,适合程序员.作家.它有很多亮点功能,比如多选择.Go Anything.命令面板.多选择可以让你同时编辑多出代码,Got Anything 像 ...
- 【已解决】Windows下 MySQL大小写敏感 解决方案及分析
Windows下 MySQL大小写敏感配置 zoerywzhou@163.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2017-3-27 最近在window ...
- 模块“XXX.dll”加载失败
具体问题:模块“XXX.dll”加载失败 请确保该二进制存储在指定的路径中,或者调试它以检查该二进制或相关的.DLL文件是否有问题 找不到指定的模块. 1.在安装C++软件的时候,有时候安装失败提示 ...
- iframe 自适应内容高度
在使用iframe的时候,会出现iframe不能随着内容的高度自动改变的情况,下面就介绍一种可以自适应高度的办法.<br/> <pre> <iframe id=" ...