读RCNN论文笔记
1. RCNN的模型(如下图)描述:
RCNN相比传统的物体检测,还是引入传统的物体检测的基本流程,先找出候选目标物体,逐个的提取特征,不过rbg大神引入了当时炙手可热的CNN卷积网络取代传统上的HOG,DPM,LBP,SIFT等算法来对图像的特征进行提取,值得说道的是CNN由于可以放到GPU上,所以也大幅度的减少了了物体检测需要的时间,然后在使用svm/softmax分类器进行分类识别.
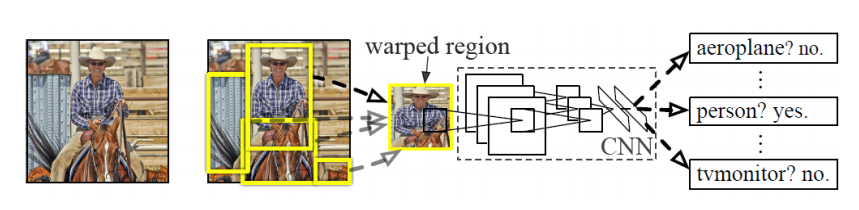
| 候选区域目标(RP) | 特征提取 | 分类 | |
| RCNN | selective search | CNN | SVM |
| 传统的算法 |
objectness, constrainedparametric min-cuts, sliding window,edge boxes,.... |
HOG , SIFT, LBP, BoW, DPM,... |
SVM |
2. RCNN模型的三个组成部分:
1. 先使用ILSVRC2012数据集训练一个1000类的分类器模型,并将这个模型保存下来.
2. 加载1步骤中的模型,使用这个模型中特征提取参数来初始化我们这里的CNN中的参数,并使用那些经过变形的区域目标来训练模型,这里获取到的区域目标指的是
和经过SS算法提取到的区域目标和我们标注的目标区域的IOU【两张图片的交集/两张图片的并集】>0.5时,我们将这个SS算法提取的区域目标作为我们标注的类(及该类的正样本)进行训练,否则作为负样本进行训练,并且值得注意的是对于每一个SGD(随机梯度)迭代,我们使用一个128的小批次,其中使用32个当前类的样本,和96个背景样本作为负样本。
3. 训练二分类目标分类器,作者列举检测车的例子,“对于那种沿着车边缘分割出的车的区域,我们可以很清楚的知道这是一个正样本,而对于那种不包含任何车信息的区域,我们也容易直到这是一个负样本,但是对于那种包含了部分车的区域,我们切没有明确的界限来定义”,这里作者经过一系列的实验【0,0.1,0.2,0.3,0.4,0.5】,当为0.5时,MAP(平均APA)会下降5%,当为0时,会下降4%,只有当SS算法分割出的区域和我们打样本时标注的区域的IOU大于0.3时,我们的MAP最高.对于每一个类,候选的正样本使用ground-truth bounding boexs来定义,也就是大于IOU大于0.7认为是正样本,小于0.3认为是负样本,鉴于0.3~0.7之间的丢掉不用来训练.而且对每一个类使用线性SVM进行分类,但是因为训练数据有时会非常大,为了不爆内存,作者使用了[背景bg/前景fg(即样本)]=3:1的比例进行.
2.1 关于图片的转换(warp):

图片在经过CNN卷积网络需要将图片统一成固定大小,论文中给出了三种方法的对比A为原始图片
一方法: 在原始区域目标周围去一块区域进行等比缩放到CNN需要的图片大小,结果图B
二方法: 去除原始目标区域然后对目标区域进行填充,在等比缩放到CNN需要的图片大小,结果C
三方法: 直接将原始目标区域非等比缩放到CNN需要的图片大小,图D
3. 预测目标区域:
在测试时,我们使用ss算法在每一张测试图片上提取大约2000个区域目标,对每一个区域目标
进行变形放入到CNN提取特征向量.然后对每一个类,我们使用对这个训练好的SVM来对每一个区域目标打分.
对一张图片中的所有打分的区域目标,我们使用一种非极大值抑制算法(NMS)来去掉两个区域目标中交集/并集大于阈值时,区中评分较低的那个区域.
4. 所以在训练的过程中也需要进行分步骤训练:
1. 对CNN网络进行微调.
先使用ILSVRC2012数据集训练一个1000类的分类器模型,然后使用该模型来初始化我们的CNN模型参数,使用我们的train和val数据集合进行微调.
2. 对每一个样本进行线性SVM分类模型训练.
来自于验证集(val)和训练集(train)中的所有目标区域被充当对应类的正样本,而每一个的负样本使用的是随机取自验证集val
3. 边框回归训练
边框回归使用的也是val集合
5. Positive vs. Negative examples and softmax
关于正负样本选取,在CNN训练阶段和SVM阶段为什么或出现阈值不同[0.5和0.3],经过作者多次测试后得到的结果.至于为什么使用SVM而不是用softmax进行分类.
作者说如果使用softmax进行分类mAP会从54.2%掉到50.9%,作者给出的是sofxmax在取任意的样本的负样本,也就是是所有的负样本共享,而SVM是只专门取对应类的负样本.
6.边框回归 具体步骤:
6.1 当使用SVM分类器对SS提供的候选区域目标[经过筛选后的]进行打分之后,模型会使用一个边框回归器会对这区域给出一个预测的区域坐标【我们称之为bounding box】,并在经过CNN提取的特征图上进行回归.
6.2 具体流程如下:
6.2.1 输入N(我们的类别为N) 对{Pi,Gi} i=1,....,N 其中P是预测区域,G为我们标注的区域 且P={Pix,Piy,Piw,Pih}表示的(x,y,w,h)分别是中心坐标:x,y坐标w,h宽高
G和P拥有同样的结构,我们的目的是学习一种变换能够将预测的P映射到实际的G上.
四个参数使用四个函数来表示dx(P),dy(P),dw(p),dh(p),其中前两个使用x,y平移变换,w,h做缩放变换
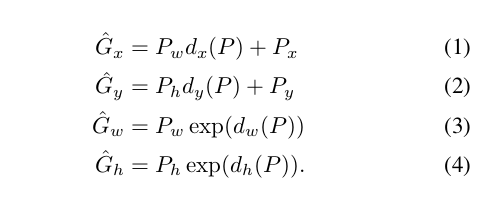
--------------------------推导部分--------------------------
强调: P,G对应的点是原图上的值,或者说对应的区域目标是未经过CNN处理过的.
那么将这些点映射到feature map 上如何计算呢?
我们先计算出我们打的标签位置G映射回feature map是(x,y,w,h)的变化量:
tx = (Gx - Px)/Pw ; (1)
注: Gx 表示的是在原图上的左上角x的坐标,Px表示的是SS算法等处理过后的区域目标在原图上的中心坐标x. Pw表示SS算法等处理过后的区域目标在原图上的宽度. tx 表示x的变化量
ty = (Gy - Py)/Ph ; (2)
注: Gy 表示的是在原图上的左上角y的坐标,Py表示是SS算法等处理过后的区域目标在原图上的中心坐标y. Ph表示是SS算法等处理过后的区域目标在原图上的高度. ty 表示y的变化量
tw = log(Gw/Pw); (3)
注: Gw 表示的是在原图上的宽度,Pw表示是SS算法等处理过后的区域目标在原图上的宽度. tw 表示w的变化量
th = log(Gh/Ph); (4)
注: Gh 表示的是在原图上的高度,Ph表示是SS算法等处理过后的区域目标在原图上的高度. th 表示h的变化量
综上,我们就得到了G'(tx,ty,tw,th)这一组,我们标注的标签,从原图映射回特征图上的映射关系. 那么我们的预测值呢?
我们的预测值就是上图公式中的P'(dx(P),dy(P),dw(P),dh(P))这一组,我们经过SS算法以及非极大抑制算法之后得到的区域目标从原图映射回特征图上的映射关系. 也就是说如果我们的预测值要和实际标注值趋近,那就需要G‘和P'两个近似相等.
也就是使得:
dx(P) ~ tx (1)
dy(P) ~ ty (2)
dw(P) ~ tw (3)
dh(P) ~ th (4)
那么我们的dx(P),dy(P),dw(P),dh(P)是如何得到的呢? 我们用d*(P)通用变量来代表这四个具体变量.
然后我们使用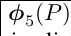 表示经过CNN提取之后的区域目标向量(即我们图片抽象数据),我们设置一个学习模型参数W* 我们用使用目标向量和学习模型参数矩阵相乘,来得到我们的目标函数:
表示经过CNN提取之后的区域目标向量(即我们图片抽象数据),我们设置一个学习模型参数W* 我们用使用目标向量和学习模型参数矩阵相乘,来得到我们的目标函数:
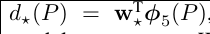
这样的话,我们的损失函数也就可以得到了,这里我们使用一个通用的公式来表示:
LOSS = 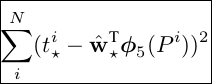 , 包含了(x,y,w,h)的损失函数,
, 包含了(x,y,w,h)的损失函数,
知道了损失函数,我们就不难得到我们优化目标函数: 对于N个类,我们每次去损失值最小的那一组进行学习:
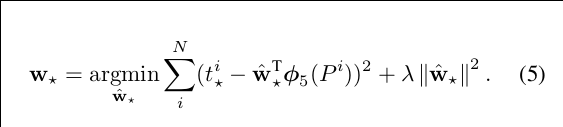 ,并且我们设定入=1000.
,并且我们设定入=1000.
有了优化目标,就可以使用SGD函数来的到最优的W参数了.
关于是不是在进行边框回归的时候,所有的区域目标都可以用来进行训练?
特别强调的是,模型在选取训练样本的时候,选择的是离Ground Truth(我们标注的目标)较近的目标,要达到选择的目标和GT目标的IOU值>0.6.
参考:
Rich feature hierarchies for accurate object detection and semantic segmentation Tech report [1]
R-CNN for Object Detection [2]
读RCNN论文笔记的更多相关文章
- 一种有效的压缩感知方法——读Levin论文笔记
原文链接:http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.122.2942&rep=rep1&type=pdf 1 基 ...
- 深度学习论文笔记:Fast R-CNN
知识点 mAP:detection quality. Abstract 本文提出一种基于快速区域的卷积网络方法(快速R-CNN)用于对象检测. 快速R-CNN采用多项创新技术来提高训练和测试速度,同时 ...
- 论文笔记:CNN经典结构1(AlexNet,ZFNet,OverFeat,VGG,GoogleNet,ResNet)
前言 本文主要介绍2012-2015年的一些经典CNN结构,从AlexNet,ZFNet,OverFeat到VGG,GoogleNetv1-v4,ResNetv1-v2. 在论文笔记:CNN经典结构2 ...
- 【目标检测】Cascade R-CNN 论文解析
目录 0. 论文链接 1. 概述 2. 网络结构的合理性 3. 网络结构 4. 参考链接 @ 0. 论文链接 Cascade R-CNN 1. 概述 这是CVPR 2018的一篇文章,这篇文章也为 ...
- R-CNN学习笔记
R-CNN学习笔记 step1:总览 步骤: 输入图片 先挑选大约2000个感兴趣区域(ROI)使用select search方法:[在输入的图像中寻找blobby regions(可能相同纹理,颜色 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 论文笔记(2):A fast learning algorithm for deep belief nets.
论文笔记(2):A fast learning algorithm for deep belief nets. 这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm ...
- 论文笔记:Rich feature hierarchies for accurate object detection and semantic segmentation
在上计算机视觉这门课的时候,老师曾经留过一个作业:识别一张 A4 纸上的手写数字.按照传统的做法,这种手写体或者验证码识别的项目,都是按照定位+分割+识别的套路.但凡上网搜一下,就能找到一堆识别的教程 ...
- Deep Learning论文笔记之(三)单层非监督学习网络分析
Deep Learning论文笔记之(三)单层非监督学习网络分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
随机推荐
- RabbitMQ 3.6.1集群搭建
MQ的集群首先需要搭建erlang集群1.把cat /root/.erlang.cookie 内容改为一致 cat /root/.erlang.cookie 2.更改cookie文件权限 chmod ...
- java面向对象--类加载器及Class对象
类加载器 jvm 和 类的关系 当调用 java命令运行一个java程序时,会启动一个java虚拟机进程.同一个jvm的所有线程.所有变量都处于同一个进程里,都使用该jvm进程的内存区. jvm进程终 ...
- 记一次亲身踩过的hibernate的bug
记一次亲身踩过的hibernate的bug 在写实体类时,经常会对域增加校验,例如@NotNull表示哪个字段不能为空,昨天晚上调试代码,就遇到了问题, @Entity public class Ap ...
- CentOS上安装NodeJs
(1)参照:http://www.cnblogs.com/zhangqingsh/archive/2013/04/15/3022583.html 安装Python2.7 (2)安装Nodejs yu ...
- ECMAScript 6.0 简介
ECMAScript 6.0 在es6中有 许多语法.还有lambda的使用.以及 class 的使用 还有一些新的对象来解决一些事情 可以提高开发效率 但更重要的是 颠覆 javascript 在你 ...
- PHP科普
1.PHP是什么意思? 超文本预处理器(Hypertext Preprocessor) 2.PHP是干什么用的? PHP是一种通用开源脚本语言.语法吸收了C语言.Java和Perl(实际抽取与汇报语言 ...
- JVM-5.字节码执行引擎
一.概述 二.栈帧结构 三.方法调用 四.方法执行 一.概述 虚拟机与物理机 虚拟机是一个相对于物理机的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器.硬件. ...
- Mybatis中如何查询时间段内的数据
最后一个是正确的,前边的三个是可能遇到的坑,给大家展示一下,如果不需要的,可以直接跳到最后看: 有时候我们需要查询一张表内一段时间内操作的数据,大家很容易就想到了 between ? and ? 这个 ...
- [python标准库]XML模块
1.什么是XML XML是可扩展标记语言(Extensible Markup Language)的缩写,其中的 标记(markup)是关键部分.您可以创建内容,然后使用限定标记标记它,从而使每个单词. ...
- Sqlmap注入Base64编码的注入点
不小心删了,找快照才找到的.补回来... 上次遇到一个Base64的注入点,手工注入太麻烦,于是在网上看了一下sqlmap Base64注入的方法,如下: sqlmap -u http://xxxx. ...