宽字符wchar_t和窄字符char区别和相互转换
转自:http://blog.csdn.net/nodeathphoenix/article/details/7416725
1. 首先,说下窄字符char了,大家都很清楚,就是8bit表示的byte,长度固定。char字符只能表示ASII码表中的256个字符,包括前128个可见字符和后面的128个不可见字符。
而wchar_t则是因为char所能表示的字符数太少(256个)而应运而生的,它的长度可以8bit,16bit,32bit,长度是与不同平台上的c库相关的。其实这个长度是根据指定平台上想要用的encoding编码方式来设定的。
在win32 MSVC环境下,c库中wchar_t的长度是2个byte,定义如下:
typedef unsigned short wchar_t; /* 16 bits */
它是按照utf-16编码,但是因为wchar_t定义的长度只有2个字节,所以它不能表示utf-16编码长度为4个字节的字符。即wchar_t只表示了utf-16的一个子集。换句话话说,就是MSVC下,wchar_t是utf-16编码的,但是只能表示utf-16的一个子集。按utf-16编码时,大部分字符都以固定长度的字节 (2字节) 储存.
在Linux-x86的GCC环境下,c库中wchar_t的长度为四个字节,用UCS-4(即utf-32编码方式)。
wchar_t就是存储的字符的unicode码值的编码值,如windows下就是unicode码值的utf-16编码值:
TCHAR wide[] = L"态";
在vs中watch为: [0] 24577 L'态' wchar_t,即对应的十进制为24577,而"态"unicode表中查到的码值为十六进制的6001,而0x6001对应的十进制值就是24577.
TCHAR wide[] = L"a"; 因为a的unicode值与ASCII值一样,为97. 如果unicode码值U小于0x10000,则U的UTF-16编码就是U对应的16位无符号整数。
所以可知,0x6001的utf-16编码值就是0x6001。
wchar_t w1= L'中'; //Unicode 编码 ,宽字符字符串前面要加L
wchar_t w2= '中'; //Ansi编码
printf( "%0x %0x ",w1,w2);
结果:
4e2d d6d0
虽然同样是赋值给wchar_t,但是不同的编码则值是不同的。同时也说明了wchar_t不光是可以存储Unicode宽字符,也可以存储其它的编码。但是如果是存储的Ansi编码,则按照宽字符的格式输出的是什么呢?
wchar_t c= L'中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述代码能正常输出'中'字
wchar_t c= '中';
wcout.imbue(locale("chs"));
wcout<<c<<endl;
上述代码不能正常输出'中'字,结果是什么也没输出。
所以如果是需要宽字符参数的API里传入值为Ansi编码值的wchar_t可能会得到不可预测的结果。
c/c++标准只是声明wchar_t是一个可以表示字符集中的任意一个字符的足够宽的变量类型。wchar_t可以用任何encoding编码方式来存储这个字符,如ANSI, or UCS-2, or UCS- 4, 甚至是SCU-128,只不过我们通常是用unicode编码方式。wchar_t是与实现相关的。
所以为了可移植性,我们不能假定wchar_t的编码方式,然后根据编码方式做一些相关性操作,我们只能理解它为一个足够宽的字符类型。
参考:http://prog.eskosoft.com/2007/01/13/19
2. ANSI码
ANSI码(American National Standards Institute),中文:美国国家标准学会的标准码。
我们说的ansi码,指windows平台的一种ascii扩展码,他将ascii码扩展到8bits,增加了0x80-0xff共128个字符。
对于ANSI码表而言,它兼容ASCII码表,0x00~0x7F之间的字符,依旧是1个字节代表1个字符。为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个非英语字符。
像GB2312, BIG5, JIS 等使用ANSI码表的0x80~0xFF范围的 2 个字节来代表一个字符的各种汉字延伸编码方式,统称为ANSI 编码。比如:汉字 '中' 在GB2312码表中,使用 [0xD6,0xD0] 这两个字节存储。ANSI 编码与UTF-8一样,也是一种编码方式。
ANSI用一个字节来表示英语字符,用两个字节来表示一个非英语字符----这个字符位于某个字符集中的value。而字符集则可以是象GB2312,BIG5等在ASCII码表基础上扩展的字符集。这些字符集中兼容ASCII码表,并且加入了汉字(或繁体等)的字符集。
在vs 的c++环境下,可以通过如下方式查看汉字的ANSI编码值。char类型取值范围为-128~127。-42对应的char类型数据的原码为“10101010”,反码为"11010101",补码为"11010110",即十六进制为0xD6。同理-48则为0xD0.由此我们可知,ANSI,是通过两个窄字符char来表示一个汉字的。
当我们 在VS里输入一个“中”字时,其实它在GB2312里对应的两个字符值为0xD6和0xD0,那么VS里其实记录的就是[0xD6,0xD0]这个编码值。当我们电脑控制面板里设置的system locale为中文的时候,[0xD6,0xD0]在VS里就是呈现出“中”字;但是如果system locale设置为韩文时,[0xD6,0xD0]在VS里就是呈现出的就是它所表示的韩文字。即同一个ANSI编码值,对于不同的system
locale值(不同的字符集),显示出来的字符是不一样的。
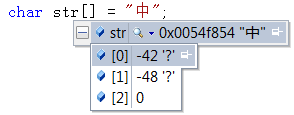
在VS工程属性里无论你选择Multi-Byte Character Set 或 Unicode Character Set字符集,char str[] = "中";这个表达式里,"中"都是ANSI编码,编码值都是[0xD6,0xD0]。即默认情况下,如果不加_T或L,默认情况下所有的字符都是ANSI编码。
3. 相互转换:
转换的时候是与encoding相关的,转换完后显示是和本地的language相关的。
windows:
MultiByteToWideChar和WideCharToMultiByte, MultiByteToWideChar可将utf-8编码的多字节或是ANSI编码的多字节(即两个字节)等转换为Unicode的宽字符wchar_t。例如,两个byte的窄字符表示的ANSI汉字转换为Unicode的宽字符wchar_t。WideCharToMultiByte可以将wchar_t转换utf-8或ANSI
等编码的多字节。
linux:mbstowcs和wcstombs
MultiByteToWideChar根据接口中指定的encoding方式将source多字符转换为对应的unicode值的宽字符;WideCharToMultiByte则刚好相反,是根据指定的encoding编码方式将unicode字符转换为指定的编码方式的多字符。
char str[] = "中";
int len=MultiByteToWideChar(CP_ACP,0,str, -1, NULL,0);
wchar_t *w_string = new wchar_t[len];
memset(w_string,0,sizeof(wchar_t)*len);
MultiByteToWideChar(CP_ACP, 0, str,-1,w_string, len);
运行结果:
则len的长度为2,得到两个宽字符。*w_string则是'中'的宽字符值,*(w_string+1)则为结束符'\0'对应的宽字符值0.
详细的转换过程,下面的link中有详细描述:
http://www.ccw.com.cn/college/soft/b2c/os/htm2011/20111128_954237.shtml
另外附上一个非常不错的文章链接:
http://club.topsage.com/thread-2227977-1-1.html
宽字符wchar_t和窄字符char区别和相互转换的更多相关文章
- 宽字符wchar_t和窄字符char——putwchar、wprintf
宽字符wchar_t 与 窄字符char 先说下窄字符char,这个大部分读者应该很清楚,char类型的变量占一个字节(byte)(也就是8个bit(比特)),能表示256个字符,那char的范围有两 ...
- C++ 宽字符(wchar_t)与窄字符(char)的转换
了解 长度 宽字符wchar_t的长度16位,可以用来显示中文等除英文外的其他文字, 窄字符 char 的长度 8 位,只能处理英文. 哪里可以见到 在VS2010, 2012, 2013 ...
- volatile,可变参数,memset,内联函数,宽字符窄字符,国际化,条件编译,预处理命令,define中##和#的区别,文件缓冲,位域
1.volatile: 要求参数修改每次都从内存中的读取.这种情况要比普通运行的变量需要的时间长. 当设置了成按照C99标准运行之后,使用volatile变量之后的程序运行的时间将比register的 ...
- GBK转utf-8,宽字符转窄字符
//GBK转UTF8 string CAppString::GBKToUTF8(const string & strGBK) { string strOutUTF8 = "" ...
- C语言小程序——推箱子(窄字符和宽字符)
C语言小程序——推箱子(窄字符Version) 推箱子.c #include <stdio.h> #include <conio.h> #include <stdlib. ...
- char,wchar_t,WCHAR,TCHAR,ACHAR的区别----LPCTSTR
转自http://blog.chinaunix.net/uid-7608308-id-2048125.html 简介:这是DWORD及LPCTSTR类型的了解的详细页面,介绍了和类,有关的知识,加入收 ...
- 使用Unicode(宽字节字符集);多字节字符集中定义宽字节变量
2012-03-25 14:54 (分类:计算机程序) 2.2 宽字符和C 宽字符不一定是Unicode.Unicode是宽字符集的一种.然而,因为本书的焦点是Windows而不是C执行的理论,所以书 ...
- c++中获取字符cin,getchar,get,getline的区别
http://www.imeee.cn/News/GouWu/20090801/221298.html cin.get()与getchar()函数有什么区别? 详细点..C++中几个输入函数的用法和区 ...
- strlen 字符型数组和字符数组 sizeof和strlen的区别 cin.get(input,Arsize)
strlenstrlen所作的仅仅是一个计数器的工作,它从内存的某个位置(可以是字符串开头,中间某个位置,甚至是某个不确定的内存区域)开始扫描,直到碰到第一个字符串结束符'\0'为止,然后返回计数器值 ...
随机推荐
- Linux内核设计基础(九)之进程管理和调度
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/BlueCloudMatrix/article/details/30799225 在Linux中进程用 ...
- rtmp播放器
rtmp测试地址: rtmp://live.hkstv.hk.lxdns.com/live 有的时候连接不上,不是很流畅 参考: 1,simplest flashmedia example http: ...
- [原创]java WEB学习笔记27:深入理解面向接口编程
本博客为原创:综合 尚硅谷(http://www.atguigu.com)的系统教程(深表感谢)和 网络上的现有资源(博客,文档,图书等),资源的出处我会标明 本博客的目的:①总结自己的学习过程,相当 ...
- ubuntu 部署的mysql无法远程链接
允许远程用户登录访问mysql的方法 从任何主机上使用root用户,密码:youpassword(你的root密码)连接到mysql服务器: # mysql -u root -proot mysql& ...
- Delphi程序的自动升级功能的实现(AutoUpdate使用指南)
在UtiMnid组件下,利用auAutoUpgrader实现自动升级(已经测试通过) 第一步:下载AutoUpgrader.Pro.v4.6.4. 第二步:打开AutoUpgrader.Pro.v4. ...
- 算法(Algorithms)第4版 练习 2.1.24
代码实现: package com.qiusongde; import edu.princeton.cs.algs4.In; import edu.princeton.cs.algs4.StdOut; ...
- 编码,charset,乱码,unicode,utf-8与net简单释义
1.文件分为文本文件和二进制文件﹐不过本质都一样﹐都是些01. 2.计算机存储设备存储的0或1﹐称为计算机的一个二进制位(bit). 3.二进制文件的0和1有专门的应用程序来读﹐所以它们没有什么乱不乱 ...
- ubuntu commands mysql
use table; //选择某个表 show tables; //展现有几个表 select * from table; //显示表内容
- 用python实现的抓取腾讯视频所有电影的爬虫
1. [代码]用python实现的抓取腾讯视频所有电影的爬虫 # -*- coding: utf-8 -*-# by awakenjoys. my site: www.dianying.atim ...
- php: +1天, +3个月, strtotime(): +1 day, +3 month
php: +1天, +3个月, strtotime(): +1 day, +3 month 比如,我现在当前时间基础上+1天: strtotime("+1 day"); 比如我现 ...