XML的基本用法(转)
一、概述
XML全称为可扩展的标记语言。主要用于描述数据和用作配置文件。
XML文档在逻辑上主要由一下5个部分组成:
- XML声明:指明所用XML的版本、文档的编码、文档的独立性信息
- 文档类型声明:指出XML文档所用的DTD
- 元素:由开始标签、元素内容和结束标签构成
- 注释:以<!--开始,以-->结束,用于对文档中的内容起一个说明作用
- 处理指令:通过处理指令来通知其他应用程序来处理非XML格式的数据,格式为<?xml-stylesheet href="hello.css" type="text/css"?>
XML文档的根元素被称为文档元素,它和在其外部出现的处理指令、注释等作为文档实体的子节点,根元素本身和其内部的子元素也是一棵树。
二、XML文档解析
在解析XML文档时,通常是利用现有的XML解析器对XML文档进行分析,应用程序通过解析器提供的API接口得到XML数据。

XML解析方式分为两种:DOM和SAX:
DOM:用来解析相对较小的XML文件,容易增删改查。DOM的核心是节点,DOM在解析XML文档时,将组成文档的各个部分映射为一个对象,这个对象就叫做节点。使用DOM解析XML文档,需要将读入整个XML文档,然后在内存中创建DOM树,生成DOM树上的每个节点对象。

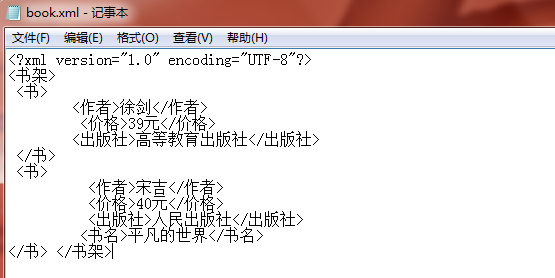
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<作者>李阳</作者>
<价格>39元</价格>
<出版社>高等教育出版社</出版社>
</书>
<书>
<作者>宋吉</作者>
<价格>40元</价格>
<出版社>人民出版社</出版社>
</书>
</书架>
使用DOM解析上述XML文档,代码如下:
package com.test.xml;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class Demo
{
public static void main(String args[])
{
//得到DOM解析器工厂类的实例
DocumentBuilderFactory dbf=DocumentBuilderFactory.newInstance();
try
{
//得到dom的解析器对象
DocumentBuilder db=dbf.newDocumentBuilder();
//解析XML文档,得到代表文档的document对象
File file=new File("D:\\Eclipse\\workSpace\\day_050401\\src\\book.xml");
Document doc=db.parse(file); //以文档顺序返回标签名字为书的所有后代元素
NodeList nl=doc.getElementsByTagName("书"); for(int i=0;i<nl.getLength();i++)
{
Element elt=(Element) nl.item(i);
Node eltAuthor=elt.getElementsByTagName("作者").item(0);
Node eltPricer=elt.getElementsByTagName("价格").item(0);
Node eltPublish=elt.getElementsByTagName("出版社").item(0); String Author=eltAuthor.getFirstChild().getNodeValue();
String Pricer=eltPricer.getFirstChild().getNodeValue();
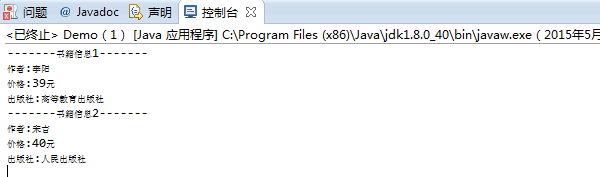
String Publish=eltPublish.getFirstChild().getNodeValue(); System.out.println("-------书籍信息"+(i+1)+"-------");
System.out.println("作者:"+Author);
System.out.println("价格:"+Pricer);
System.out.println("出版社:"+Publish);
} }
catch (ParserConfigurationException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
catch (SAXException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
} catch (IOException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
} }
}
执行结果如下:
SAX:内存消耗较小,适合读取操作。SAX是一种基于事件驱动的API,利用SAX解析XML文档涉及解析器和事件处理器两个部分。解析器负责读取XML文档,并向事件处理器发送事件,事件处理器则负责对事件作出相应,对传递的XML数据进行处理。
使用SAX解析XML文档,代码如下:
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
class Book
{
private String name;
private String author;
private String price;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
public String getAuthor()
{
return author;
}
public void setAuthor(String author)
{
this.author = author;
}
public String getPrice()
{
return price;
} public void setPrice(String price)
{
this.price = price; } }
public class Demo extends DefaultHandler
{
private List list=new ArrayList();
private String currentTag;
private Book book;
@Override
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException
{
currentTag=name;
if("书".equals(currentTag))
{
book=new Book();
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException
{
if("出版社".equals(currentTag))
{
String name=new String(ch,start,length);
book.setName(name);
}
if("作者".equals(currentTag))
{
String author=new String(ch,start,length);
book.setAuthor(author);
}
if("价格".equals(currentTag))
{
String price=new String(ch,start,length);
book.setPrice(price);
}
}
@Override
public void endElement(String uri, String localName, String name)
throws SAXException
{
if(name.equals("书"))
{
list.add(book);
book=null;
}
currentTag=null;
}
public List getBooks()
{
return list;
}
public static void main(String []args)
{
//1.创建解析工厂
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser sp=null;
try
{
//2.得到解析器
sp=factory.newSAXParser();
//3、得到读取器
XMLReader reader=sp.getXMLReader();
File file=new File("D:\\Eclipse\\workSpace\\day_050401\\src\\book.xml");
//4.设置内容处理器
Demo handle=new Demo();
//reader.setContentHandler(handle);
sp.parse(file,handle);
//5.读取xml文档内容
List<Book> list=handle.getBooks();
for(int i=0;i<list.size();i++)
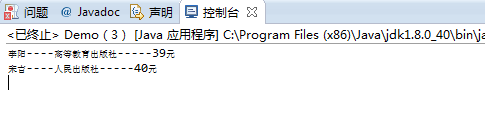
System.out.println(list.get(i).getAuthor()+"----"+list.get(i).getName()+"-----"+list.get(i).getPrice());
}
catch (ParserConfigurationException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
catch (SAXException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
catch (IOException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
运行结果如下:
三、dom4j解析XML文档
dom4j也是一种用于解析XML文档的开放源代码的Java库。下载地址http://sourceforge.net/projects/dom4j/。
使用dom4j进行读取XMl文档操作,代码如下:
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.security.KeyStore.Entry.Attribute; import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test; public class Demo
{
//读取xml文件第二本书的出版社
@Test
public void read()
{
SAXReader reader = new SAXReader();
try
{
Document document = reader.read("C:\\Users\\Administrator\\Desktop\\book.xml");
Element root =document.getRootElement();
Element book=(Element)root.elements("书").get(1);
String value=book.element("出版社").getText();
System.out.println(value);
}
catch (DocumentException e)
{
// TODO 自动生成的 catch 块
e.printStackTrace();
}
} //在第二本书上添加一个书名:<书名>平凡的世界</书名>
@Test
public void add() throws DocumentException, IOException
{
SAXReader reader = new SAXReader();
Document document = reader.read("C:\\Users\\Administrator\\Desktop\\book.xml"); Element book=(Element) document.getRootElement().elements("书").get(1);
book.addElement("书名").setText("平凡的世界");
//更新内存
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream("C:\\Users\\Administrator\\Desktop\\book.xml"),"UTF-8"));
writer.write(document);
writer.close();
}
}
运行结果:
PS:如果你的项目经常需要更换解析器,建议使用DOM和SAX,这样当更换解析器时不需要更改任何代码,如果没有这样的需求,建议使用dom4j,简单而又强大。
转自:http://www.cnblogs.com/xujian2014/p/4480198.html
XML的基本用法(转)的更多相关文章
- [转]Animation 动画详解(一)——alpha、scale、translate、rotate、set的xml属性及用法
转载:http://blog.csdn.net/harvic880925/article/details/39996643 前言:这几天做客户回访,感触很大,用户只要是留反馈信息,总是一种恨铁不成钢的 ...
- android.view.animation(1) - alpha、scale、translate、rotate、set的xml属性和用法(转)
一.ScaleAnimation ScaleAnimation(float fromX, float toX, float fromY, float toY, int pivotXType, floa ...
- 转:自定义控件三部曲之动画篇——alpha、scale、translate、rotate、set的xml属性及用法
第一篇: 一.概述 Android的animation由四种类型组成:alpha.scale.translate.rotate,对应android官方文档地址:<Animation Resour ...
- python学习第四十九天XML模块的用法
xml是实现不通语言或程序之间进行数据交换的协议,跟json差不多,但是json用起来简单,还没诞生json,以前都是用xml,下面讲述XML模块的用法. 1,导入xml模块 import xml 2 ...
- XSD(XML Schema Definition)用法实例介绍以及C#使用xsd文件验证XML格式
XML Schema 语言也称作 XML Schema 定义(XML Schema Definition,XSD),作用是定义 XML 文档的合法构建模块,类似 DTD,但更加强大. 作用有: ①定义 ...
- Animation 动画详解(一)——alpha、scale、translate、rotate、set的xml属性及用法
一.概述 Android的animation由四种类型组成:alpha.scale.translate.rotate,对应android官方文档地址:<Animation Resources&g ...
- 小白的Python之路 day5 模块XML特点和用法
模块XML的特点和用法 一.简介 xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今 ...
- SQLServer中sql for xml path 的用法
我们通常需要获取一个多行的某个字段拼出的字符串,我们可以使用for xml path进行处理:下面将介绍for xml path的具体用法: 创建测试表&插入测试数据 在数据库中新增测试表 C ...
- 自定义控件三部曲之动画篇(一)——alpha、scale、translate、rotate、set的xml属性及用法
前言:这几天做客户回访,感触很大,用户只要是留反馈信息,总是一种恨铁不成钢的心态,想用你的app,却是因为你的技术问题,让他们不得不放弃,而你一个回访电话却让他们尽释前嫌,当最后把手机号留给他们以便随 ...
- 28.XSD(XML Schema Definition)用法实例介绍以及C#使用xsd文件验证XML格式
转自https://www.cnblogs.com/gdjlc/archive/2013/09/08/3308229.html XML Schema 语言也称作 XML Schema 定义(XML S ...
随机推荐
- 嵌入式Linux中摄像头使用简要整理【转】
转自:http://www.cnblogs.com/emouse/archive/2013/03/03/2941938.html 本文涉及软硬件平台: 开发板:飞凌OK6410 系统:Ubuntu 1 ...
- Vue全局异常捕获
之前没注意过这么个小技巧 , 可能在Vue文档里也有 暂时先记下了 方便摘要 Vue全局配置 errorHandler可以进行全局错误收集,我们可以根据这个特性对前端异常做这样的处理:业务错误直接写 ...
- GitHub和GitLab的区别 转自(zhang_oracle)
把代码从GitHub上迁移到GitLab上,在使用一段时间过后,发现GitLab与GitHub还是有不少区别的. 先说一下相同点,二者都是基于web的Git仓库,在很大程度上GitLab是仿照GitH ...
- hdu 3264(枚举+二分+圆的公共面积)
Open-air shopping malls Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/ ...
- [BZOJ1032][JSOI2007]祖码Zuma 区间dp
1032: [JSOI2007]祖码Zuma Time Limit: 10 Sec Memory Limit: 162 MB Submit: 1105 Solved: 576 [Submit][S ...
- 允许root用户登录ssh
使用普通用户登录Ubuntu系统,打开命令行窗口 更改root用户密码,命令:sudo passwd root 首先输入当前用户的密码 然后输入root账户的密码 确认root用户的密码 编辑ssh的 ...
- Codeforces 938D Buy a Ticket (转化建图 + 最短路)
题目链接 Buy a Ticket 题意 给定一个无向图.对于每个$i$ $\in$ $[1, n]$, 求$min\left\{2d(i,j) + a_{j}\right\}$ 建立超级源点$ ...
- 前台vue的使用简单小结
前台vue的使用简单小结 本项目要求:安装有node.js 6.0以及以上安装npm使用vue.js官方安装方法初始化项目npm install安装VueResurce:npm install vue ...
- Jmeter正则表达式提取器--将上一个请求的结果作为下一个请求的参数
正则表达式提取器是一个后置处理器,作用是在请求完成后,从响应数据中截取一部分字符串保存到变量中,以便下一个请求使用 1.首先在线程组下添加两个HTTP请求, 2.添加好两个HTTP请求后,在每个HTT ...
- [LOJ6280]数列分块入门 4
题目大意: 给你一个长度为$n(n\leq50000)$的序列$A$,支持进行以下两种操作: 1.将区间$[l,r]$中所有数加上$c$: 2.询问区间$[l,r]$在模$c+1$意义下的和.思路: ...