C++实现多组数据合并输出
思路
假设有多组数据,每一组都是按从小到大的顺序输入的,设计如下数据结构
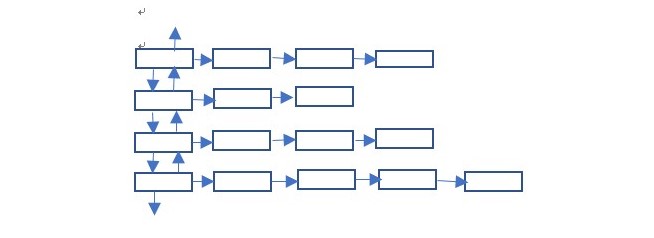
前面一列是每一组数据的首部,后面是真正的数据,首部的定义为:
struct head {
Node* next;
head* down;
head* up;
};
数据部分的定义为:
struct Node {
int data;
Node* next;
};
1.我们称左上角为根,左下角为尾,根的前指针(up)和尾的后指针(down)为NULL,next指向数据,那么在输出的时候,只需要遍历第二列选出最小的数据即可,在输出该结点之后将该节点删除,并更新该数据结构。
2.定义两个指针p和q,分别用来遍历和指向最小数据。
a.如果q(指向最小数据的指针)指到了根,并且p->next->next=NULL,则表示根所在的一行已经输出完毕,需要更新根,于是判断根的下指针是否也为NULL,如果是,表示已经结束,如果不是则将下一行首部设置为根。
b.如果p->next->next不等于NULL,则只需要将p的next指向p的next的next即p->next = p->next->next。
c.如果q指向除根以外的首部,并且,后面有多的数据,则p->next = p->next->next,如果没有多余数据表示这一行已经全部输出,删除p和p->next指向的空间,并将p的上一行的首部的下指针指向p的下一行的首部,下一行的上指针指向p的上一行首部。
3.输出的时候只需要当前数据与前一个输出的数据不同即可。
代码:
namespace SORT {
using namespace std;
struct Node {//数据结点
int data;
Node* next;
};
struct head {//头结点
Node* next;
head* down;
head* up;
};
void Create(Node*& root) {
int tmp;
if (root == NULL) {
cin >> tmp;
if (tmp == -)//输入-1是结束该行输入
return;
root = new Node;
root->data = tmp;
root->next = NULL;
Create(root->next);
}
return;
}
void Destory(head*& root) {
head* p = root;//循环遍历指针
head* q = root->down;//每次都指向最小
Node* tmp = NULL;
int num = ;//保存前一次输出的值
while (p != NULL && q != NULL)
{
while (p != NULL) {
if (p->next->data < q->next->data) {
q = p;
p = p->down;
}
else {
p = p->down;
}
}
if (q->next->data != num) {
cout << q->next->data << " ";
num = q->next->data;
}
if (q->up == NULL) {
if (q->next->next == NULL) {
p = root;
if (root->down == NULL) {
delete root->next;
delete root;
return;
}
root->down->up = NULL;
root = root->down;
delete p->next;
delete p;
p = q = root;
}
else {
tmp = q->next;
q->next = q->next->next;
delete tmp;
tmp = NULL;
p = q = root;
}
}//if
else {
if (q->next->next == NULL) {
q->up->down = q->down;
if (q->down == NULL) {
q->up->down = NULL;
delete q->next;
delete q;
}
else {
q->down->up = q->up;
delete q->next;
delete q;
}
p = q = root;
}
else {
tmp = q->next;
q->next = q->next->next;
delete tmp;
tmp = NULL;
p = q = root;
}//else
}//else
}//while
}
void CreateHead(int n) {//n表示有几行数据
head* root = new head;
root->down = NULL;
root->up = NULL;
root->next = NULL;
Create(root->next);//第一行单独创建
head* p = root;
for (int i = ; i < n; i++)
{
head* N = new head;
N->down = NULL;
N->next = NULL;
N->up = p;
p->down = N;
p = N;
Create(p->next);
}
Destory(root);
}
}
调用:
int main() {
int num;
std::cin >> num;
SORT::CreateHead(num);
}
运行结果:

如果有什么错误欢迎大家指正。
C++实现多组数据合并输出的更多相关文章
- jquery: json树组数据输出到表格Dom树的处理方法
项目背景 项目中需要把表格重排显示 处理方法 思路主要是用历遍Json数组把json数据一个个append到5个表格里,还要给每个单元格绑定个单击弹出自定义对话框,表格分了单双行,第一行最后还要改ro ...
- NOIP提高组2004 合并果子题解
NOIP提高组2004 合并果子题解 描述:在一个果园里,多多已经将所有的果子打了下来,而且按果子的不同种类分成了不同的堆.多多决定把所有的果子合成一堆. 每一次合并,多多可以把两堆果子合并到一起,消 ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- PANDAS 数据合并与重塑(join/merge篇)
pandas中也常常用到的join 和merge方法 merge pandas的merge方法提供了一种类似于SQL的内存链接操作,官网文档提到它的性能会比其他开源语言的数据操作(例如R)要高效. 和 ...
- JUint4的下载、配置及对一个算法编写单元测试用例(测试多组数据每组多个参数)
一.JUnit4 jar包下载 链接:https://pan.baidu.com/s/1AdeVGGikcY5dfL151ZnWHA 提取码:h1am 下载完成后,解压一下即可. 二.导入JUnit4 ...
- ggpubr进行“paper”组图合并,也许比PS,AI更简单
本文转载自微信公众号 “生信补给站”,https://mp.weixin.qq.com/s/41iKTulTwGcY-dHtqqSnLA 多个图形进行组图展示,可以既展示一个“事情”的多个角度,也可以 ...
- SQL将多行数据合并成一行【转】
转:https://blog.csdn.net/AntherFantacy/article/details/83824182 今天同事问了一个需求,就是将多行数据合并成一行进行显示,查询了一些资料,照 ...
- excel多组数据散点图生成
在研究数据分布时,散点图是一类比较常用的方法,通过三点图可以很好的显示数据的分布位置.一组数据生成散点图,利用excel是很容易生成的:但是,多组数据生成散点图,不同组数据用不同颜色表示,那该怎么生成 ...
- checkbox提交多组数据到action
突然想通过checkbox来提交多组数据到action,一时间想不起来怎么写,到网上流岚大婶们的笔迹之后,有了新发现! 方法一: 在action用一个String类型的变量来接受checkbox传过来 ...
随机推荐
- 在Ubuntu16.04 TLS 安装LAMP
准备在虚拟机上搭建一个靶机系统(DoraBox),但是还不想使用一键搭建所以起了心思准备使用LAMP框架搭载这个靶机系统,于是有了以下文章,先从百度搜索一下,Ubuntu搭建LAMP. 然后点进去第一 ...
- TCP/IP协议、三次握手、四次挥手
1.什么是TCP/IP协议 TCP/IP 是一类协议系统,它是用于网络通信的一套协议集合. 传统上来说 TCP/IP 被认为是一个四层协议 1) 网络接口层: 主要是指物理层次的一些接口,比如电缆等. ...
- find文件删除
find /root/title/test -type f -name '*.txt' -exec rm {} \; 查找并删除test文件夹下所有txt文件 find /root/title/t ...
- ASP.NET、.NET和C#的关系是怎样的?
1..NET是什么?.Net全称.NET Framework是一个开发和运行环境,该战略是微软的一项全新创意,它将使得“互联网行业进入一个更先进的阶段”,.NET不是一种编程语言. 简单说就是一组类库 ...
- ASP.NET--Repeater控件分页功能实现
这两天由于‘销售渠道’系统需要实现新功能,开发了三个页面,三个界面功能大致相同. 功能:分页显示特定sql查询结果,点击上一页下一页均可显示.单击某记录可以选定修改某特定字段<DropDownL ...
- AT173 単位:题解
题目链接:https://www.luogu.org/problemnew/show/AT173 分析: 首先,我们可以做如下排序: sort(a+1,a+1+n); 因为题目告诉我们了要出席最少的次 ...
- [leetcode]python 283. Move Zeroes
Given an array nums, write a function to move all 0's to the end of it while maintaining the relativ ...
- 微信小程序踩坑日记1——调用微信授权窗口
0. 引言 微信小程序为了优化用户体验,取消了在进入小程序时立马出现授权窗口.需要用户主动点击按钮,触发授权窗口. 那么,在我实践过程中,出现了以下问题. . 无法弹出授权窗口 . 希望在用户已经授权 ...
- 一键布署WEB应用脚本
一.本机脚本(基于mac) #!/bin/sh if [ $# -lt 1 ]; then echo "deploy.sh <version number>" exi ...
- 六、SQL 多张表数据叠加到一个视图里面
1 create view vABC as select * from a,b,c where a.id = b.aid and b.id = c.bid ---------------------- ...