这事没完,继续聊spring cloud stream和kafka的这些小事
上一篇文章讲了如何用spring cloud stream集成kafka,并且跑起来一个demo,如果这一次宣传spring cloud stream的文章,其实到这里就可以啦。但实际上,工程永远不是简单的技术会还是不会的问题,在实际的开发中,我们会遇到很多的细节问题(简称坑),这篇文章,会把其中一些很小的点说一下,算是用实例告诉大家,工程的复杂性,往往体现在实际的繁琐步骤中。
1、group的配置
在发送消息的配置里面,group是不用配置的

关于这一点的证明,可以在源代码的注释里面看到
org.springframework.cloud.stream.config.BindingProperties

2、修改topic的partitions
配置文件如下
bindings:
output:
binder: kafka
destination: wph-d-2 #消息发往的目的地,对应topic
content-type: text/plain #消息的格式
producer:
partitionCount: 7partitionCount是用来设置partition的数量,默认是1,如果这个topic已经建了,修改partitionCount无效,会提示错误
Caused by: org.springframework.cloud.stream.provisioning.ProvisioningException: The number of expected partitions was: 7, but 5 have been found instead.Consider either increasing the partition count of the topic or enabling `autoAddPartitions`
at org.springframework.cloud.stream.binder.kafka.provisioning.KafkaTopicProvisioner.createTopicAndPartitions(KafkaTopicProvisioner.java:384) ~[spring-cloud-stream-binder-kafka-core-3.0.0.M4.jar:3.0.0.M4]
at org.springframework.cloud.stream.binder.kafka.provisioning.KafkaTopicProvisioner.createTopicIfNecessary(KafkaTopicProvisioner.java:325) ~[spring-cloud-stream-binder-kafka-core-3.0.0.M4.jar:3.0.0.M4]
at org.springframework.cloud.stream.binder.kafka.provisioning.KafkaTopicProvisioner.createTopic(KafkaTopicProvisioner.java:302) ~[spring-cloud-stream-binder-kafka-core-3.0.0.M4.jar:3.0.0.M4]
... 14 common frames omitted根据错误的提示,添加autoAddPartitions
kafka:
binder:
brokers: #Kafka的消息中间件服务器地址
- localhost:9092
autoAddPartitions: true再次启动就可以看到partitions数已经改了
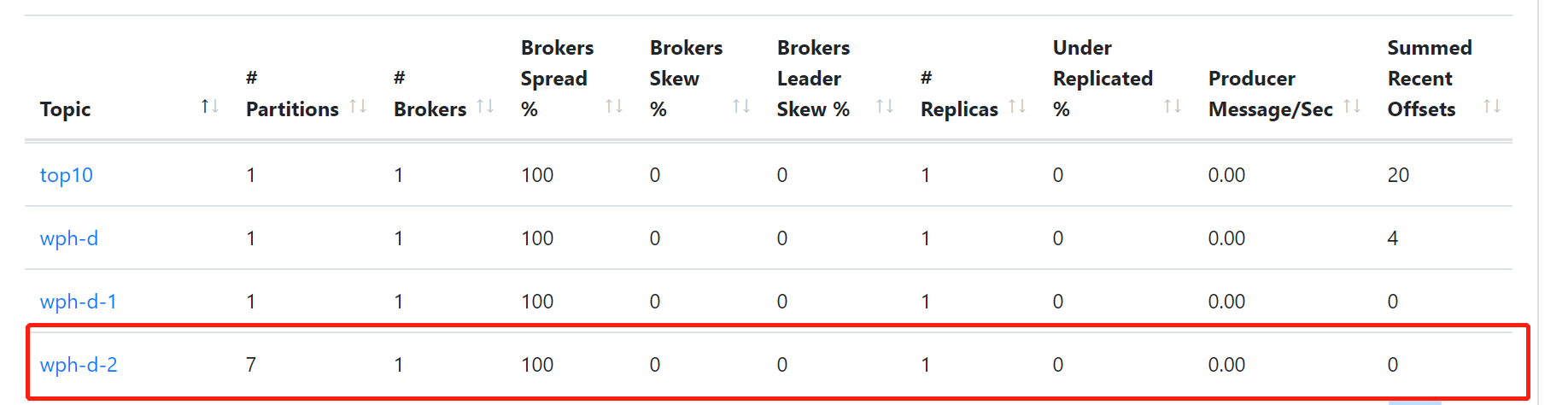
autoAddPartitions属性对应的类是org.springframework.cloud.stream.binder.kafka.properties.KafkaBinderConfigurationProperties
设置partitionCount属性的类是org.springframework.cloud.stream.binder.ProducerProperties
3、发送json报错
用postman发送sendMessage/complexType报错
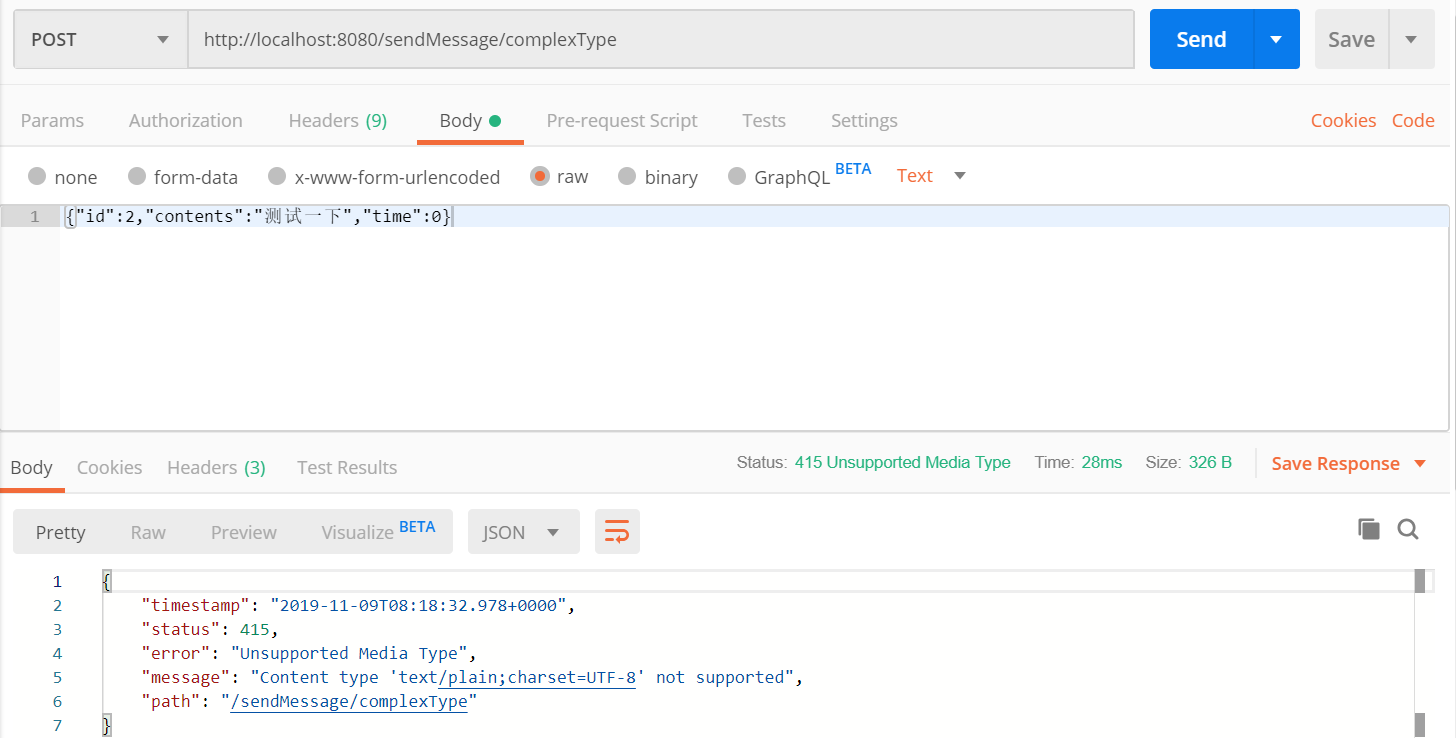
在服务器端的报错内容是:
Resolved [org.springframework.web.HttpMediaTypeNotSupportedException: Content type 'text/plain;charset=UTF-8' not supported]原因是数据传输格式传输错误,要改一下postman发送数据的格式
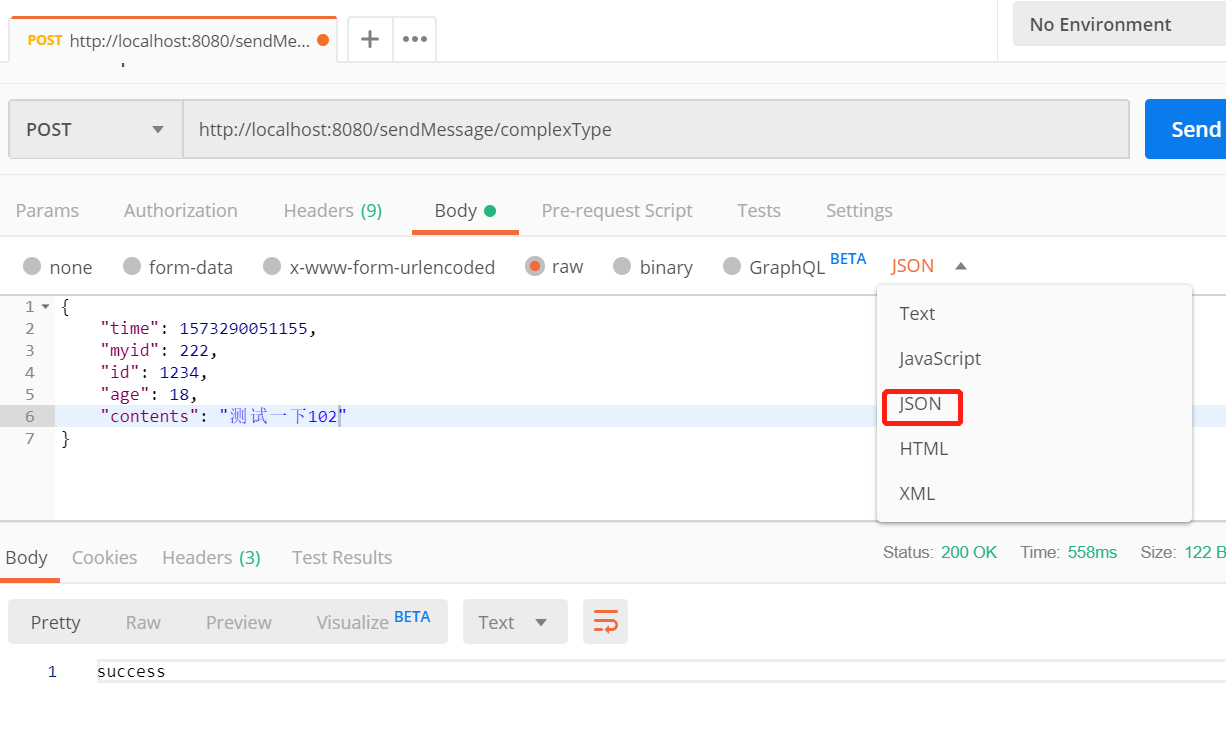
然后就能happy的发出去了

4、正确的发送json并转换成对象
如果我们需要传输json的信息,那么在发送消息端需要设置content-type为json(其实可以不写,默认content-type就是json,后面会讲)
bindings:
output:
binder: kafka
destination: wph-d-2 #消息发往的目的地,对应topic
content-type: application/json #消息的格式然后通过producer发送这个消息
@RequestMapping(value = "/sendMessage/complexType", method = RequestMethod.POST)
public String publishMessageComplextType(@RequestBody ChatMessage payload) {
logger.info(payload.toString());
producer.getMysource().output().send(MessageBuilder.withPayload(payload).setHeader("type", "chatMessage").build());
return "success";
}这里需要注意的一点是ChatMessage的field name必须要有getter和settr方法,两者有一就可以了,否则json转换成对象的时候,field name收不到值。
在订阅消息的时候,application.yml里面content-type可以不用配置,这个值默认就是“application/json”,这一点可以在org.springframework.cloud.stream.config.BindingProperties类的注释里面看到

和上面一样,ChatMessage的field name需要有getter或者setter的方法,二者之一就行。
接收json并转换成类的方法如下:
@StreamListener(target = Sink.INPUT, condition = "headers['type']=='chatMessage'")
public void handle(ChatMessage message) {
logger.info(message.toString());
}有坑警告:如果我们把发送消息端的content-type设置成text/plain,消息订阅端的content-type设置成application/json,就会在消息订阅端报这个错误
Caused by: java.lang.IllegalStateException: argument type mismatch
Endpoint [com.wphmoon.kscsclient.Consumer]如果颠倒过来的话,发送消息端的content-type设置成application/json,消息订阅端设置成text/plain,我实际测试过,是可以收到消息,并且能转换成ChatMessage对象,没有问题。
这事没完,继续聊spring cloud stream和kafka的这些小事的更多相关文章
- 简单聊一聊spring cloud stream和kafka的那点事
Spring Cloud Stream is a framework for building highly scalable event-driven microservices connected ...
- Kafka及Spring Cloud Stream
安装 下载kafka http://mirrors.hust.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz kafka最为重要三个配置依次为:broke ...
- Spring Cloud Stream教程(二)主要概念
Spring Cloud Stream提供了一些简化了消息驱动的微服务应用程序编写的抽象和原语.本节概述了以下内容: Spring Cloud Stream的应用模型 Binder抽象 持续的发布 - ...
- 细聊Spring Cloud Bus
细聊Spring Cloud Bus Spring 事件驱动模型 因为Spring Cloud Bus的运行机制也是Spring事件驱动模型所以需要先了解相关知识点: 上面图中是Spring事件驱动模 ...
- Spring Cloud Stream同一通道根据消息内容分发不同的消费逻辑
应用场景 有的时候,我们对于同一通道中的消息处理,会通过判断头信息或者消息内容来做一些差异化处理,比如:可能在消息头信息中带入消息版本号,然后通过if判断来执行不同的处理逻辑,其代码结构可能是这样的: ...
- Spring Cloud Stream消费失败后的处理策略(四):重新入队(RabbitMQ)
应用场景 之前我们已经通过<Spring Cloud Stream消费失败后的处理策略(一):自动重试>一文介绍了Spring Cloud Stream默认的消息重试功能.本文将介绍Rab ...
- Spring Cloud Stream消费失败后的处理策略(三):使用DLQ队列(RabbitMQ)
应用场景 前两天我们已经介绍了两种Spring Cloud Stream对消息失败的处理策略: 自动重试:对于一些因环境原因(如:网络抖动等不稳定因素)引发的问题可以起到比较好的作用,提高消息处理的成 ...
- Spring Cloud Stream消费失败后的处理策略(二):自定义错误处理逻辑
应用场景 上一篇<Spring Cloud Stream消费失败后的处理策略(一):自动重试>介绍了默认就会生效的消息重试功能.对于一些因环境原因.网络抖动等不稳定因素引发的问题可以起到比 ...
- Spring Cloud Stream消费失败后的处理策略(一):自动重试
之前写了几篇关于Spring Cloud Stream使用中的常见问题,比如: 如何处理消息重复消费 如何消费自己生产的消息 下面几天就集中来详细聊聊,当消息消费失败之后该如何处理的几种方式.不过不论 ...
随机推荐
- 《鸟哥的Linux私房菜--基础篇》学习
第四章 显示日期与时间的指令:date 输入: (base) liyihuadeMacBook-Pro:~ liyihua$ date 输出: Thu Jun 6 08:44:02 CST 2019 ...
- Java中打印日志,这4点很重要!
目录 一.预先判断日志级别 二.避免无效日志打印 三.区别对待错误日志 四.保证记录完整内容 打印日志,要注意下面4点. 一.预先判断日志级别 对DEBUG.INFO级别的日志,必须使用条件输出或者使 ...
- BigInt 的使用!
今天学长讲的卡特兰数真的是卡的一批,整个全是高精的题,这时我就使用重载运算符,然后一下午就过去了 首先来看一波水题(也就卡了2小时) . A. 网格 内存限制:512 MiB 时间限制:1000 ms ...
- PTA刷题记录(3)
团队天梯赛-------(3)分值:15 给定一个 k 位整数 N=dk−110k−1+⋯+d1101+d0 (0≤di≤9, i=0,⋯,k−1, dk−1 ...
- Go 基础学习笔记 (5)| 数据类型说明与使用
在 Go 编程语言中,数据类型用于声明函数和变量. 数据类型的出现是为了把数据分成所需内存大小不同的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以充分利用内存. Go 语言按类别有以下几种 ...
- css3-3D特效
2D页面即是在浏览器中开发的页面, 3D可以比喻浏览器为窗口,透过浏览器看到3D物体 一.设置3D场景 perspective:800[3D世界中的物体距3D场景的距离800px] perspecti ...
- docker——数据卷volume:文件共享
volume——如何让容器中的一个目录与宿主机的一个目录进行绑定,实现容器与宿主机之间的文件共享? 数据卷volume功能特性 数据卷:是一个可供一个或多个容器使用的特殊目录,实现让容器中的一个目录和 ...
- tornado的使用-数据库篇
tornado的使用-数据库篇
- nyoj 111-分数加减法 (gcd, switch, 模拟,数学)
111-分数加减法 内存限制:64MB 时间限制:1000ms 特判: No 通过数:20 提交数:54 难度:2 题目描述: 编写一个C程序,实现两个分数的加减法 输入描述: 输入包含多行数据 每行 ...
- Blob字段
在oracle中有一个特殊的字段类型Blob,Blob是指二进制大对象也就是英文Binary Large Object的缩写: 通过sql取出后,需要进行特殊处理.而我是这样玩的: 1.通过sql查询 ...