kafka入门(二)分区和group
topic
在kafka中消息是按照topic进行分类的;每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic
parition
一个topic可以配置几个parition,每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的,如下图:
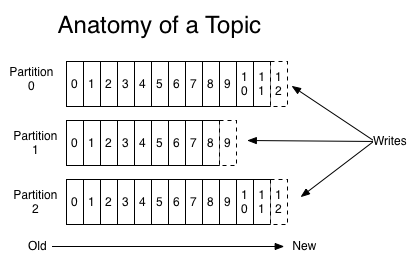
producer能指定将此消息发送到哪个parition(也可以采取随机、哈希、轮训等策略):
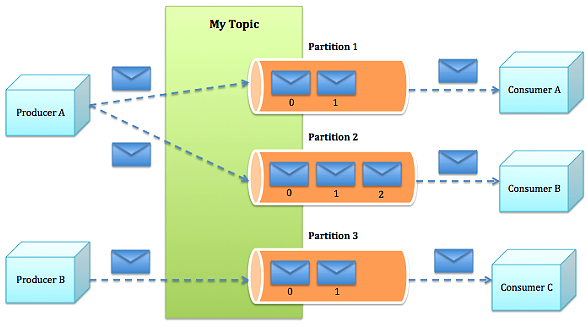
producer发送消息到broker时,会根据paritition机制选择将其存储到哪一个partition。如果partition机制设置合理,所有消息可以均匀分布到不同的partition里,这样就实现了负载均衡。如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而有了partition后,不同的消息可以并行写入不同broker的不同partition里,极大的提高了吞吐率。
consumer group
producer发送的消息分发到不同的parition中,consumer接受数据的时候是按照group来接受,kafka确保每个parition只能同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费
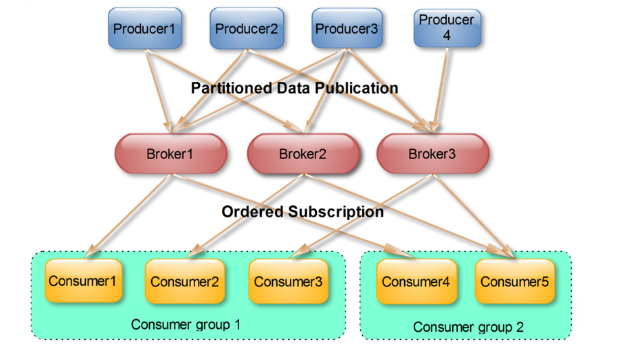
consumer group是kafka提供的可扩展且具有容错性的消费者机制。既然是一个组,那么组内必然可以有多个消费者或消费者实例(consumer instance),它们共享一个公共的ID,即group ID。组内的所有消费者协调在一起来消费订阅主题(subscribed topics)的所有分区(partition)。当然,每个分区只能由同一个消费组内的一个consumer来消费。
consumer group特性:
- consumer group下可以有一个或多个consumer instance
- group.id是一个字符串,唯一标识一个consumer group
- consumer group下订阅的topic下的每个分区只能分配给某个group下的一个consumer(当然该分区还可以被分配给其他group)
消费者位置(consumer position)
很多消息引擎都把这部分信息保存在服务器端(broker端)。这样做的好处当然是实现简单,但会有三个主要的问题:
- broker从此变成有状态的,会影响伸缩性;
- 需要引入应答机制(acknowledgement)来确认消费成功。
- 由于要保存很多consumer的offset信息,必然引入复杂的数据结构,造成资源浪费。
而Kafka选择了不同的方式:每个consumer group保存自己的位移信息,那么只需要简单的一个整数表示位置就够了;同时可以引入checkpoint机制定期持久化,简化了应答机制的实现。
老版本的位移是提交到zookeeper中的,目录结构是:/consumers/<group.id>/offsets/<topic>/<partitionId>,但是zookeeper其实并不适合进行大批量的读写操作,尤其是写操作。因此kafka提供了另一种解决方案:增加__consumeroffsets topic,将offset信息写入这个topic,摆脱对zookeeper的依赖(指保存offset这件事情)。__consumer_offsets中的消息保存了每个consumer group某一时刻提交的offset信息。
kafka入门(二)分区和group的更多相关文章
- kafka partition(分区)与 group
kafka partition(分区)与 group 一. 1.原理图 2.原理描述 一个topic 可以配置几个partition,produce发送的消息分发到不同的partition中,co ...
- Kafka 入门(二)--数据日志、副本机制和消费策略
一.Kafka 数据日志 1.主题 Topic Topic 是逻辑概念. 主题类似于分类,也可以理解为一个消息的集合.每一条发送到 Kafka 的消息都会带上一个主题信息,表明属于哪个主题. Kafk ...
- Kafka入门教程(二)
转自:https://blog.csdn.net/yuan_xw/article/details/79188061 Kafka集群环境安装 相关下载 JDK要求1.8版本以上. JDK安装教程:htt ...
- kafka入门:简介、使用场景、设计原理、主要配置及集群搭建(转)
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的原因是什么? 3.kafka集群consumer和producer状 ...
- [Hadoop大数据]--kafka入门
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行“随机读写”的原因是什么? 3.kafka集群consumer和producer状态信息是如何保存的? ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- kafka入门配置
问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行“随机读写”的原因是什么? 3.kafka集群consumer和producer状态信息是如何保存的? ...
- [转帖]kafka入门:简介、使用场景、设计原理、主要配置及集群搭建
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建 http://www.aboutyun.com/thread-9341-1-1.html 还没看完 感觉挺好的. 问题导读: 1.zook ...
- kafka 入门
李克华 云计算高级群: 292870151 195907286 交流:Hadoop.NoSQL.分布式.lucene.solr.nutch kafka入门:简介.使用场景.设计原理.主要配置及集群搭 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
随机推荐
- Plugin execution not covered by lifecycle configuration
Eclipse 环境 在工作空间 \.metadata\.plugins\org.eclipse.m2e.core\ 目录下 增加 lifecycle-mapping-metadata.xml 文件 ...
- python解决urllib2乱码问题
示例: #!/usr/bin/env python # -*- coding: utf-8 -*- import urllib import urllib2 def main(): url = &qu ...
- Layui 2.0.0 正式发布:潜心之作,开箱即用的前端UI框架(确实很多内容)
Hi,久违了.处暑逼近之际,潜水半年的 layui 是时候出来透透气了.我们带来的是全新的 2.0 版本,一次被我们定义为“破茧重生”的倾情之作.如果你已曾用过 layui,你将真正感受到一次因小而大 ...
- DataContext和ItemSource
一对多的关系DataContext为上下文,绑定数据源ItemSource取上下文中的某属性,会一级一级往上找属性 一般ItemSource的绑定,绑定到Grid/DataGrid一类容器上,底下的控 ...
- OnPropertyChanged的使用
#region INotifyPropertyChanged public event PropertyChangedEventHandler PropertyChanged; ...
- sql server 定时备份数据库
CREATE PROCEDURE [dbo].[SP_DBBackup_EveryNight_Local] @cycle INT, ---保存周期 @IsLocal INT, ---是否为本地 0表示 ...
- Redis实现Timeline
上回写了[使用Redis实现关注关系][1],这次说说使用Redis实现Timeline. Timeline的实现一般有推模式.拉模式.推拉结合这几种. 推模式:某人发布内容之后推送给所有粉丝,空间换 ...
- 青云QingCloud黄允松:最高效的研发管理就是没有管理
摘要: 对于底层技术创新而言,没有管理是最好的管理,小规模作战,快速试错,迅速转变方向,迭代周期一定要短. 钛媒体注:钛媒体.商业价值联合主办的第五届“MIIC移动互联网创新大会”如期举行.2015 ...
- coci2018 题解
plahte 给定一些矩形和一些有颜色的点,求每个矩形上有多少种颜色的点,保证矩形只有包含和不相交两种关系,规模 \(10^5\). 把每个矩形看成一个点,用扫描线建出森林,同时也顺便处理点. 然后做 ...
- sql 日志恢复
可能有不少朋友遇到过这样的问题: update或delete语句忘带了where子句,或where子句精度不够,执行之后造成了严重的后果,这种情况的数据恢复只能利用事务日志的备份来进行,所以如果你的S ...