LRU算法与增强
概要
本文的想法来自于本人学习MySQL时的一个知识点:MySQL Innodb引擎中对缓冲区的处理。虽然没有仔细研究其源码实现,但其设计仍然启发了我。
本文针对LRU存在的问题,思考一种增强算法来避免或降低缓存污染,主要办法是对原始LRU空间划分出young与old两段区域 ,通过命中数(或block时间)来控制,并用一个0.37的百分比系数规定old的大小。
内容分以下几小节,实现代码为Java:
1.LRU基本概念
2.LRU存在问题与LRUG设计
3.LRUG详细说明
4.完整示例代码
1.LRU基本概念
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据。常用于一些缓冲区置换,页面置换等处理。
一个典型的双向链表+HashMap的LRU如下:
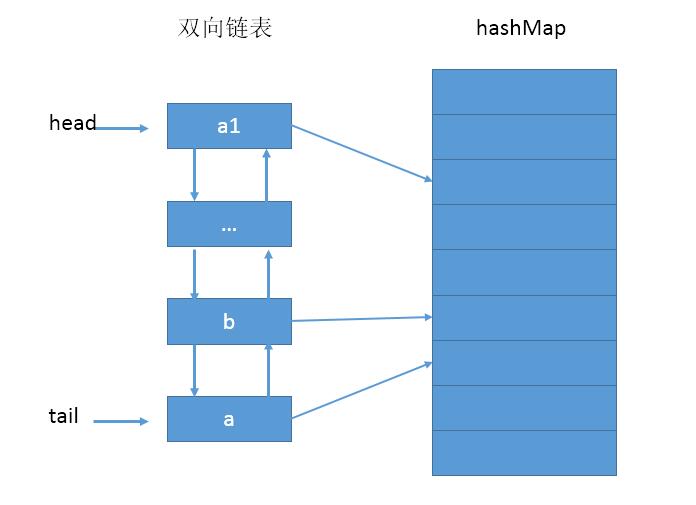
2.LRU存在问题与LRUG设计
LRU的问题是无法回避突发性的热噪数据,造成缓存数据的污染。对此有些LRU的变种,如LRU-K、2Q、MQ等,通过维护两个或多个队列来控制缓存数据的更新淘汰。我把本文讨论的算法叫LRUG,仅是我写代码时随便想的一个名字。
LRUG使用HashMap和双向链表,没有其他的维护队列,而是在双向链表上划分young,old区域,young段在old段之前,有新数据时不会马上插入到young段,而是先放入old段,若该数据持续命中,次数超过一定数量(也可以是锁定一段时间)后再进行插入首部的动作。两段以37%为界,即满载后old段的大小最多占总容量的37%。(图1)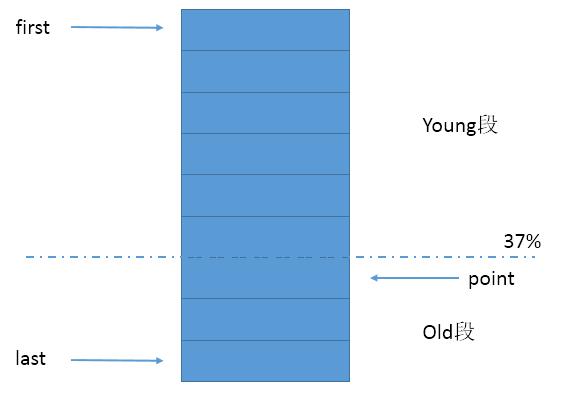
(图1)
3.LRUG详细说明
3.1首先给出双向链表的节点结构,其中hitNum是命中次数:
private static class Node<K,V>{
int hitNum;
K key;
V value;
Node<K,V> prev;
Node<K,V> next;
Node(K key,V value){
this.key=key;
this.value=value;
hitNum=0;
}
}
3.2在加载阶段,数据以先后顺序加入链表,半满载时,young段已满,新数据以插入方式加入到old段,如图2所示。注意半满载时,也可能有madeYoung操作,把old区的数据提到young头。
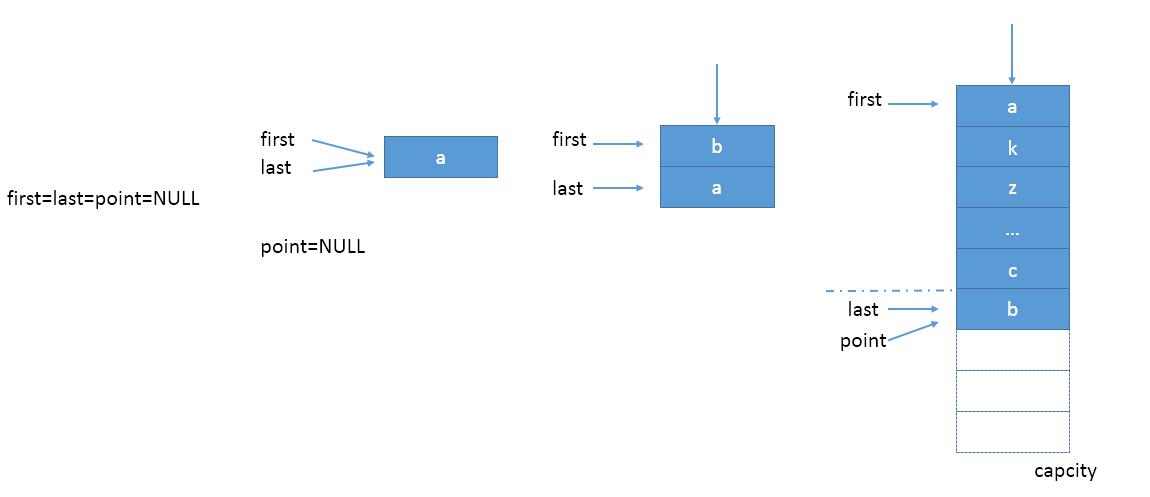
(图2)
public void put(K key,V value){
Node<K,V> node=caches.get(key);
if(node==null){
if(caches.size()>=capcity){
caches.remove(last.key);
removeLast();
}
node=new Node(key,value);
if(caches.size()>=pointBorder){
madeOld(node);
}else{
madeYoung(node);
}
}else {
node.value=value;
if(++node.hitNum>BLOCK_HIT_NUM){
madeYoung(node);
}
}
caches.put(key,node);
}
3.3当数据命中时,如果位于young区,命中数+1后进行常规的madeYoung操作,把该项提到链表首部。如图3
(图3)
如果命中项位于old区,对命中数+1后与BLOCK_HIT_NUM设置的值做判断,超过设定值说明该项数据可能不是突发数据,进行madeYoung操作提到链表首部,否则不做处理。
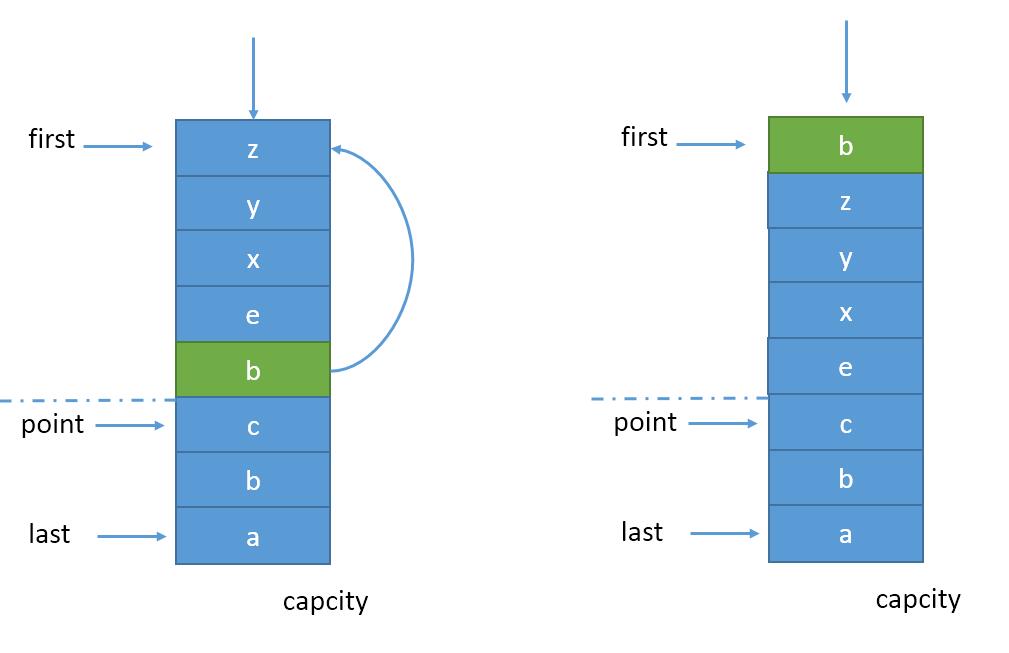
特别的,如果命中项正好是point,则point应该往后退一项,指向原point的下一项,此时young区膨胀了一项,而old区缩小了一项。极端情况下,ponit项持续被命中并进行madeYoung,point不断后退直到尾巴,此时young区占有100%容量,而old区为0,设置point指向last,意味着新数据项加入时,淘汰掉young区的末尾,而新数据项放在末尾成为old区。如图4
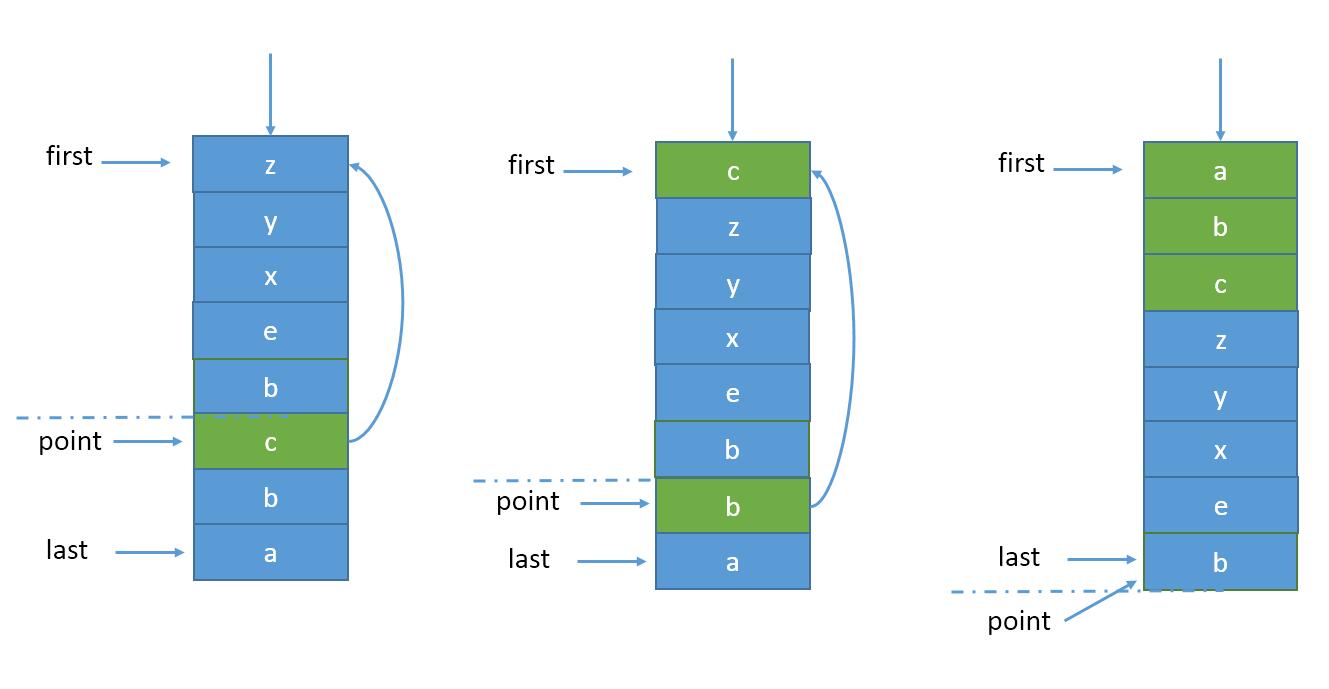
(图4)
public void madeYoung(Node node){
if(first==node){
return;
}
if(node==point){
point=node.next;
if(point==null) {
point=last;
}
}
if(node.next!=null){
node.next.prev=node.prev;
}
if(node.prev!=null){
node.prev.next=node.next;
}
if(node==last){
last=node.prev;
}
if(first==null||last==null){
first=last=node;
point=null;
return;
}
node.next=first;
first.prev=node;
first=node;
}
public void madeOld(Node node){
if(point.prev!=null){
point.prev.next=node;
node.prev=point.prev;
}
if(point.next!=null){
node.next=point.next;
point.next.prev=node;
}
point=node;
}
3.4需要一个清理的方法。也可以设置一些监测方法,如一段时间内的命中数(监测命中率)等,这与本篇主要内容无关就不写在这了。
public void removeLast(){
if(last!=null){
if(last==point) {
point=null;
}
last=last.prev;
if(last==null) {
first=null;
}else{
last.next=null;
}
}
}
4.示例代码
主要代码如下,时间仓促,可能一些地方会考虑不周,读者如发现,欢迎指出。
package com.company;
import java.util.HashMap; public class LRUNum<K,V> {
private HashMap<K,Node> caches;
private Node first;
private Node last;
private Node point;
private int size;
private int capcity;
private static final int BLOCK_HIT_NUM=2;
private static final float MID_POINT=0.37f;
private int pointBorder; public LRUNum(int capcity){
this.size=0;
this.capcity=capcity;
this.caches=new HashMap<K,Node>(capcity); this.pointBorder=this.capcity-(int)(this.capcity*this.MID_POINT);
} public void put(K key,V value){
Node<K,V> node=caches.get(key); if(node==null){
if(caches.size()>=capcity){
caches.remove(last.key);
removeLast();
}
node=new Node(key,value); if(caches.size()>=pointBorder){
madeOld(node);
}else{
madeYoung(node);
}
}else {
node.value=value;
if(++node.hitNum>BLOCK_HIT_NUM){
madeYoung(node);
}
}
caches.put(key,node);
} public V get(K key){
Node<K,V> node =caches.get(key);
if(node==null){
return null;
}
if(++node.hitNum>BLOCK_HIT_NUM){
madeYoung(node);
}
return node.value;
} public Object remove(K key){
Node<K,V> node =caches.get(key); if(node!=null){
if(node.prev!=null){
node.prev.next=node.next;
}
if(node.next!=null){
node.next.prev=node.prev;
}
if(node==first){
first=node.next;
}
if(node==last){
last=node.prev;
}
}
return caches.remove(key);
} public void removeLast(){
if(last!=null){
if(last==point) {
point=null;
} last=last.prev;
if(last==null) {
first=null;
}else{
last.next=null;
}
}
} public void clear(){
first=null;
last=null;
point=null;
caches.clear();
} public void madeYoung(Node node){
if(first==node){
return;
}
if(node==point){
point=node.next;
if(point==null) {
point=last;
}
}
if(node.next!=null){
node.next.prev=node.prev;
}
if(node.prev!=null){
node.prev.next=node.next;
}
if(node==last){
last=node.prev;
}
if(first==null||last==null){
first=last=node;
point=null;
return;
} node.next=first;
first.prev=node;
first=node;
} public void madeOld(Node node){
if(point.prev!=null){
point.prev.next=node;
node.prev=point.prev;
}
if(point.next!=null){
node.next=point.next;
point.next.prev=node;
}
point=node;
} private static class Node<K,V>{
int hitNum;
K key;
V value;
Node<K,V> prev;
Node<K,V> next; Node(K key,V value){
this.key=key;
this.value=value;
hitNum=0;
}
} }
LRU算法与增强的更多相关文章
- Android图片缓存之Lru算法
前言: 上篇我们总结了Bitmap的处理,同时对比了各种处理的效率以及对内存占用大小.我们得知一个应用如果使用大量图片就会导致OOM(out of memory),那该如何处理才能近可能的降低oom发 ...
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
- 借助LinkedHashMap实现基于LRU算法缓存
一.LRU算法介绍 LRU(Least Recently Used)最近最少使用算法,是用在操作系统中的页面置换算法,因为内存空间是有限的,不可能把所有东西都放进来,所以就必须要有所取舍,我们应该把什 ...
- LinkedHashMap实现LRU算法
LinkedHashMap特别有意思,它不仅仅是在HashMap上增加Entry的双向链接,它更能借助此特性实现保证Iterator迭代按照插入顺序(以insert模式创建LinkedHashMap) ...
- LinkedHashMap 和 LRU算法实现
个人觉得LinkedHashMap 存在的意义就是为了实现 LRU 算法. public class LinkedHashMap<K,V> extends HashMap<K,V&g ...
- 简单LRU算法实现缓存
最简单的LRU算法实现,就是利用jdk的LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可,如下所示: java 代码 import java.ut ...
- memached 服务器lru算法
1.LRU是Least Recently Used的缩写,即最近最少使用页面置换算法,是为虚拟页式存储管理服务的.LRU算法的提出,是基于这样一个事实:在前面几条指令中使用频繁的页面很可能在后面的几条 ...
- 用LinkedHashMap实现LRU算法
(在学习操作系统时,要做一份有关LRU和clock算法的实验报告,很多同学都应该是通过数组去实现LRU,可能是对堆栈的使用和链表的使用不是很熟悉吧,在网上查资料时看到了LinkedHashMap,于是 ...
- 近期最久未使用页面淘汰算法———LRU算法(java实现)
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. LRU算法,即Last Recently Used ---选择最后一次訪问时间距离当前时间最长的一页并淘汰之--即淘汰最长时间没有使用的页 依照 ...
随机推荐
- nyoj 38-布线问题(prim, sort)
38-布线问题 内存限制:64MB 时间限制:1000ms Special Judge: No accepted:5 submit:11 题目描述: 南阳理工学院要进行用电线路改造,现在校长要求设计师 ...
- 【Leetcode 做题学算法周刊】第四期
首发于微信公众号<前端成长记>,写于 2019.11.21 背景 本文记录刷题过程中的整个思考过程,以供参考.主要内容涵盖: 题目分析设想 编写代码验证 查阅他人解法 思考总结 目录 67 ...
- 队列+BFS(附vector初试)
优先队列的使用: include<queue>//关联头文件 struct node{ int x,y; friend bool operator < (node d1,node d ...
- bash6——循环
for fruit in apple orange pear #写死 do each ${fruit}s done fruits="apple orange pear" #输入变量 ...
- eNSP仿真软件之配置Trunk口
实验原理 在以太网中,通过划分VLAN来隔离广播域和增强网络通信的安全性.以太网通常由多台交换机组成,为了使VLAN的数据帧跨越多台交换机传递,交换机之间互连的链路需要配置为干道链路(Trunk Li ...
- 报错:尝试加载 Oracle 客户端库时引发 BadImageFormatException。如果在安装 32 位 Oracle 客户端组件的情况下以 64 位模式运行,将出现此问题。
问题: 在写windows服务时,发布后日志报错:尝试加载 Oracle 客户端库时引发 BadImageFormatException.如果在安装 32 位 Oracle 客户端组件的情况下以 64 ...
- 2019-10-24:渗透测试,sqli-labe,less18,19关
less19基于错误_POST_Referer_请求头注入 查看关键源码,跟18关不一样的只是,回显的是Referer不是User-Agent,判断INSERT语句结构:INSERT INTO tab ...
- 部署 kube-controller-manager 高可用集群
目录 前言 创建kube-controller-manager证书和私钥 生成证书和私钥 将生成的证书和私钥分发到所有master节点 创建和分发kubeconfig文件 分发kubeconfig到所 ...
- Eclipse官方下载步骤
今天整理Eclipse项目时,发现自己的IDE不能用了,不兼容自己的JDK,于是决定去官网下载一个适合的IDE,由于官网全部都是英文,所以不是太容易找到,于是就想着出一篇博客帮助以后的人更好的更快的下 ...
- nginx项目部署
1.概念 1.Django项目(Web应用) 2.web服务 1.nginx 2.Apache LNMP -> Linux Ngin ...