【2】KNN:约会对象分类器
- 不喜欢的
- 有点魅力的
- 很有魅力的
- 每年获得的飞行常客里程数
- 玩网游所消耗的时间比
- 每年消耗的冰淇淋公升数
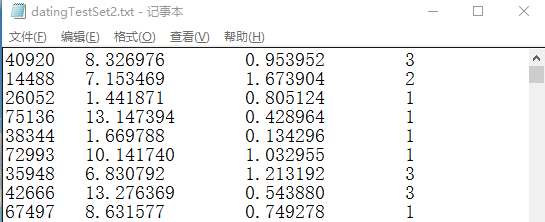
# ==========================# 读入文本记录,转换为NumPy,便于其他函数使用# 输入:文本记录的路径# ==========================def file2matrix(filename):fr = open(filename)arrayOLines = fr.readlines()numberOfLines = len(arrayOLines)returnMat = zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrayOLines:line = line.strip() # 删除字符串首尾的空白符(包括'\n', '\r', '\t', ' ')listFromLines = line.split("\t")returnMat[index, :] = listFromLines[0:3]classLabelVector.append(int(listFromLines[-1]))index += 1return returnMat, classLabelVector
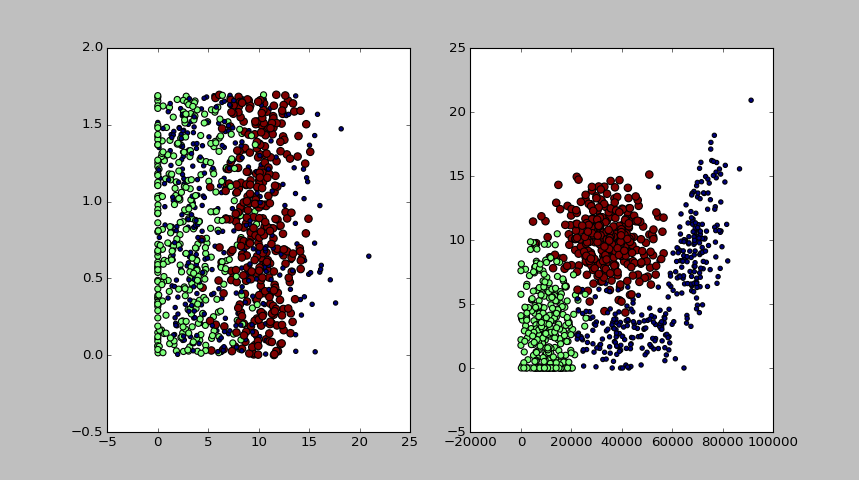
def plotSca(datingDataMat, datingLabels):import matplotlib.pyplot as pltfig = plt.figure()ax1 = fig.add_subplot(121)# 玩网游所消耗的时间比(横轴)与每年消耗的冰淇淋公升数(纵轴)的散点图ax1.scatter(datingDataMat[:,1], datingDataMat[:, 2], 15.0*array(datingLabels), 5.0*array(datingLabels))ax2 = fig.add_subplot(122)# 每年获得的飞行常客里程数(横轴)与 玩网游所消耗的时间比(纵轴)的散点图ax2.scatter(datingDataMat[:,0], datingDataMat[:, 1], 15.0*array(datingLabels), 5.0*array(datingLabels))plt.show()
# =====================================# 如果不同特征值量级相差太大,# 而他们在模型中占的权重又并不比其他特征大,# 这个时候就需要对特征值进行归一化,# 也就是将取值范围处理为0到1或者-1到1之间# 本函数就是对数据集归一化特征值# dataset: 输入数据集# =====================================def autoNorm(dataset):minVals = dataset.min(0)maxVals = dataset.max(0)ranges = maxVals - minValsnormDataset = zeros(shape(dataset))m = dataset.shape[0]normDataset = dataset - tile(minVals, (m, 1))normDataset = normDataset/tile(ranges, (m, 1)) # 矩阵中对应数值相除return normDataset, ranges, minVals
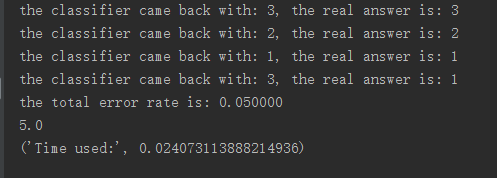
'''分类器针对约会网站的测试代码'''def datingClassTest():hoRatio = 0.10 # 数据集中用于测试的比例filePath = "E:\ml\machinelearninginaction\Ch02\datingTestSet2.txt"datingDataMat, datingLabels = file2matrix(filePath)# plotSca(datingDataMat, datingLabels)normMat, ranges, minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(hoRatio*m)errcounter = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i, :],normMat[numTestVecs:m, :],datingLabels[numTestVecs:m], 3)print "the classifier came back with: %d, the real answer is: %d" % \(classifierResult, datingLabels[i])if (classifierResult !=datingLabels[i]): errcounter +=1.0print "the total error rate is: %f" % (errcounter/float(numTestVecs))print errcounter
【2】KNN:约会对象分类器的更多相关文章
- 第二篇:基于K-近邻分类算法的约会对象智能匹配系统
前言 假如你想到某个在线约会网站寻找约会对象,那么你很可能将该约会网站的所有用户归为三类: 1. 不喜欢的 2. 有点魅力的 3. 很有魅力的 你如何决定某个用户属于上述的哪一类呢?想必你会分析用户的 ...
- 机器学习实战笔记——KNN约会网站
''' 机器学习实战——KNN约会网站优化 ''' import operator import numpy as np from numpy import * from matplotlib.fon ...
- kNN算法实例(约会对象喜好预测和手写识别)
import numpy as np import operator import random import os def file2matrix(filePath):#从文本中提取特征矩阵和标签 ...
- 第二节课-Data-driven approach:KNN和线性分类器分类图片
2017-08-12 1.图片分类是很多CV任务的基础: 2.图片分类要面临很多的问题,比如图片被遮挡,同一种动物有很多种颜色,形状等等,算法需要足够强壮: 3.所以很难直接写出程序来进行图片分类,常 ...
- kNN#约会网站预测数据
#约会网站预测数据 def classifyPersion(): resultList = ['not at all','in small doses','in large doses'] #inpu ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 海伦去约会——kNN算法
下午于屋中闲居,于是翻开<机器学习实战>一书看了看“k-邻近算法”的内容,并学习了一位很厉害的博主Jack Cui的代码,自己照着码了一遍.在此感谢博主Jack Cui的知识分享. 一.k ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
随机推荐
- (13)ASP.NET Core 中的选项模式(Options)
1.前言 选项(Options)模式是对配置(Configuration)的功能的延伸.在12章(ASP.NET Core中的配置二)Configuration中有介绍过该功能(绑定到实体类.绑定至对 ...
- Selenium+java - 借助autolt完成上传文件操作
写在前面: 上传文件是每个自动化测试同学会遇到,而且可以说是面试必考的问题,标准控件我们一般用sendkeys()就能完成上传,但是我们的测试网站的上传控件一般为自己封装的,用传统的上传已经不好用了, ...
- Hadoop 系列(七)—— HDFS Java API
一. 简介 想要使用 HDFS API,需要导入依赖 hadoop-client.如果是 CDH 版本的 Hadoop,还需要额外指明其仓库地址: <?xml version="1.0 ...
- Computing Jobs
docker&k8shadoopsparkhbasemesosrediskafkazookeeper SCSI.NVMe.PCIe devops
- Cocos经典游戏教程之仿皇室战争
版权声明: 本文原创发布于博客园"优梦创客"的博客空间(网址:http://www.cnblogs.com/raymondking123/)以及微信公众号"优梦创客&qu ...
- Mysql 局域网连接设置——Windows
在公司工作中,会遇到mysql数据库存储于某个人的电脑上,大家要想连接mysql服务,装有mysql服务的电脑就必须开启远程连接. 其实不仅仅是局域网,只要你有数据库所在服务器的公网IP地址都能连上. ...
- 初识JavaScript和面向对象
1.javascript基本数据类型: number: 数值类型 string: 字符串类型 boolean: 布尔类型 null: 空类型 undefault:未定义类型 object: 基本数据类 ...
- django报错信息解决方法
You have 17 unapplied migration(s). Your project may not work properly until you apply the migration ...
- 从原理层面掌握@ModelAttribute的使用(使用篇)【一起学Spring MVC】
每篇一句 每个人都应该想清楚这个问题:你是祖师爷赏饭吃的,还是靠老天爷赏饭吃的 前言 上篇文章 描绘了@ModelAttribute的核心原理,这篇聚焦在场景使用上,演示@ModelAttribute ...
- AutoCAD二次开发(.Net)之创建图层Layer
//https://blog.csdn.net/qq_21489689?t=1[CommandMethod("CREATELY")] public void CreateLayer ...