【2】KNN:约会对象分类器
- 不喜欢的
- 有点魅力的
- 很有魅力的
- 每年获得的飞行常客里程数
- 玩网游所消耗的时间比
- 每年消耗的冰淇淋公升数
# ==========================# 读入文本记录,转换为NumPy,便于其他函数使用# 输入:文本记录的路径# ==========================def file2matrix(filename):fr = open(filename)arrayOLines = fr.readlines()numberOfLines = len(arrayOLines)returnMat = zeros((numberOfLines, 3))classLabelVector = []index = 0for line in arrayOLines:line = line.strip() # 删除字符串首尾的空白符(包括'\n', '\r', '\t', ' ')listFromLines = line.split("\t")returnMat[index, :] = listFromLines[0:3]classLabelVector.append(int(listFromLines[-1]))index += 1return returnMat, classLabelVector
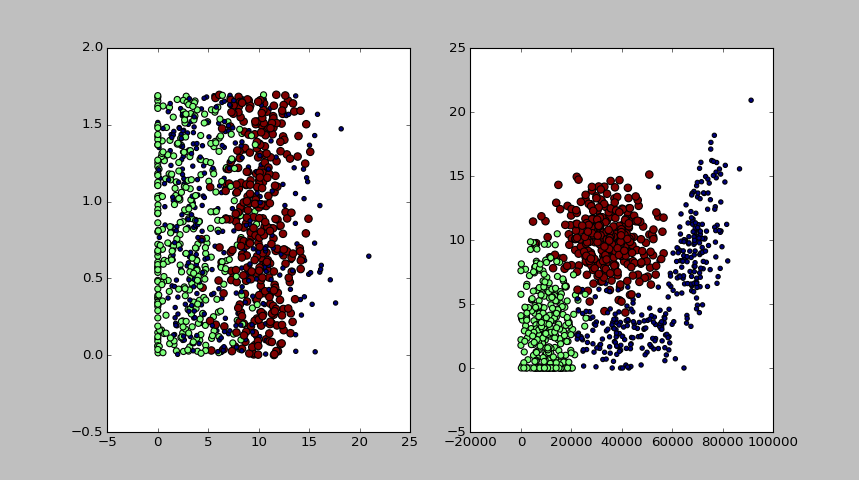
def plotSca(datingDataMat, datingLabels):import matplotlib.pyplot as pltfig = plt.figure()ax1 = fig.add_subplot(121)# 玩网游所消耗的时间比(横轴)与每年消耗的冰淇淋公升数(纵轴)的散点图ax1.scatter(datingDataMat[:,1], datingDataMat[:, 2], 15.0*array(datingLabels), 5.0*array(datingLabels))ax2 = fig.add_subplot(122)# 每年获得的飞行常客里程数(横轴)与 玩网游所消耗的时间比(纵轴)的散点图ax2.scatter(datingDataMat[:,0], datingDataMat[:, 1], 15.0*array(datingLabels), 5.0*array(datingLabels))plt.show()
# =====================================# 如果不同特征值量级相差太大,# 而他们在模型中占的权重又并不比其他特征大,# 这个时候就需要对特征值进行归一化,# 也就是将取值范围处理为0到1或者-1到1之间# 本函数就是对数据集归一化特征值# dataset: 输入数据集# =====================================def autoNorm(dataset):minVals = dataset.min(0)maxVals = dataset.max(0)ranges = maxVals - minValsnormDataset = zeros(shape(dataset))m = dataset.shape[0]normDataset = dataset - tile(minVals, (m, 1))normDataset = normDataset/tile(ranges, (m, 1)) # 矩阵中对应数值相除return normDataset, ranges, minVals
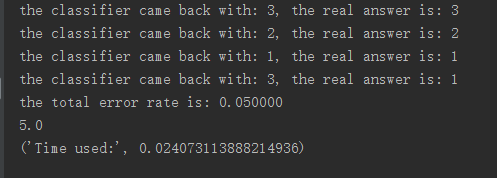
'''分类器针对约会网站的测试代码'''def datingClassTest():hoRatio = 0.10 # 数据集中用于测试的比例filePath = "E:\ml\machinelearninginaction\Ch02\datingTestSet2.txt"datingDataMat, datingLabels = file2matrix(filePath)# plotSca(datingDataMat, datingLabels)normMat, ranges, minVals = autoNorm(datingDataMat)m = normMat.shape[0]numTestVecs = int(hoRatio*m)errcounter = 0.0for i in range(numTestVecs):classifierResult = classify0(normMat[i, :],normMat[numTestVecs:m, :],datingLabels[numTestVecs:m], 3)print "the classifier came back with: %d, the real answer is: %d" % \(classifierResult, datingLabels[i])if (classifierResult !=datingLabels[i]): errcounter +=1.0print "the total error rate is: %f" % (errcounter/float(numTestVecs))print errcounter
【2】KNN:约会对象分类器的更多相关文章
- 第二篇:基于K-近邻分类算法的约会对象智能匹配系统
前言 假如你想到某个在线约会网站寻找约会对象,那么你很可能将该约会网站的所有用户归为三类: 1. 不喜欢的 2. 有点魅力的 3. 很有魅力的 你如何决定某个用户属于上述的哪一类呢?想必你会分析用户的 ...
- 机器学习实战笔记——KNN约会网站
''' 机器学习实战——KNN约会网站优化 ''' import operator import numpy as np from numpy import * from matplotlib.fon ...
- kNN算法实例(约会对象喜好预测和手写识别)
import numpy as np import operator import random import os def file2matrix(filePath):#从文本中提取特征矩阵和标签 ...
- 第二节课-Data-driven approach:KNN和线性分类器分类图片
2017-08-12 1.图片分类是很多CV任务的基础: 2.图片分类要面临很多的问题,比如图片被遮挡,同一种动物有很多种颜色,形状等等,算法需要足够强壮: 3.所以很难直接写出程序来进行图片分类,常 ...
- kNN#约会网站预测数据
#约会网站预测数据 def classifyPersion(): resultList = ['not at all','in small doses','in large doses'] #inpu ...
- k-近邻(KNN)算法改进约会网站的配对效果[Python]
使用Python实现k-近邻算法的一般流程为: 1.收集数据:提供文本文件 2.准备数据:使用Python解析文本文件,预处理 3.分析数据:可视化处理 4.训练算法:此步骤不适用与k——近邻算法 5 ...
- 海伦去约会——kNN算法
下午于屋中闲居,于是翻开<机器学习实战>一书看了看“k-邻近算法”的内容,并学习了一位很厉害的博主Jack Cui的代码,自己照着码了一遍.在此感谢博主Jack Cui的知识分享. 一.k ...
- kNN分类算法实例1:用kNN改进约会网站的配对效果
目录 实战内容 用sklearn自带库实现kNN算法分类 将内含非数值型的txt文件转化为csv文件 用sns.lmplot绘图反映几个特征之间的关系 参考资料 @ 实战内容 海伦女士一直使用在线约会 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
随机推荐
- c#链接数据库,查找数据信息
using System;using System.Collections.Generic;using System.Linq;using System.Text;using System.Threa ...
- 关于AJAX的跨域问题
最近过年的这几天在做毕业设计的时候遇到了一个关于AJAX的跨域问题,本来我是想要用一下聚合数据平台提供的天气预报的接口的,然后做一个当地的天气情况展示,但是在使用AJAX的时候,被告知出现错误了. 这 ...
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- 线性分类 Linear Classification
软分类:y 的取值只有正负两个离散值,例如 {0, 1} 硬分类:y 是正负两类区间中的连续值,例如 [0, 1] 一.感知机 主要思想:分错的样本数越少越好 用指示函数统计分错的样本数作为损失函数, ...
- Oracle中查看最近被修改过的表的方法
1.select uat.table_name from user_all_tables uat 该SQL可以获得所有用户表的名称 2.select object_name, created,last ...
- Spring入门(九):运行时值注入
Spring提供了2种方式在运行时注入值: 属性占位符(Property placeholder) Spring表达式语言(SpEL) 1. 属性占位符 1.1 注入外部的值 1.1.1 使用Envi ...
- Tomcat源码分析 (六)----- Tomcat 启动过程(一)
说到Tomcat的启动,我们都知道,我们每次需要运行tomcat/bin/startup.sh这个脚本,而这个脚本的内容到底是什么呢?我们来看看. 启动脚本 startup.sh 脚本 #!/bin/ ...
- Java 调用http接口(基于OkHttp的Http工具类方法示例)
目录 Java 调用http接口(基于OkHttp的Http工具类方法示例) OkHttp3 MAVEN依赖 Http get操作示例 Http Post操作示例 Http 超时控制 工具类示例 Ja ...
- Go调度器介绍和容易忽视的问题
本文记录了本人对Golang调度器的理解和跟踪调度器的方法,特别是一个容易忽略的goroutine执行顺序问题,看了很多篇Golang调度器的文章都没提到这个点,分享出来一起学习,欢迎交流指正. 什么 ...
- Python机器学习之数据探索可视化库yellowbrick-tutorial
背景介绍 从学sklearn时,除了算法的坎要过,还得学习matplotlib可视化,对我的实践应用而言,可视化更重要一些,然而matplotlib的易用性和美观性确实不敢恭维.陆续使用过plotly ...