【Redis深度历险】那些年Redis的数据结构
Redis端口号6379的来源
Redis的端口号是6379,但这个端口号并不是随机选择的,源于"MERZ",这个单词在手机当中的对应数字就是6379。"MERZ"在Redis作者Antirez的好友圈当中代表愚蠢的意思。
数据结构
Redis的key只能是字符串,value可以是String,Hash,List,Sorted Set(Zset)。
String
Redis的字符串是动态字符串(SDS Simple Dynamic String ),内部结构有点儿类似于java的ArrayList,都是采取预分配来减少内存的频繁扩容。如图len是实际字符串的长度,capacity是预分配的空间(数组容量)。创建字符串时,len和capacity一样长,使用字节数组存放内容。
struct SDS<T> {
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标识位
byte[] content; // 数组内容
}
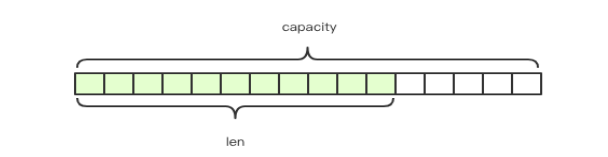
- 如果在1M以内,都是加倍扩充容量
- 如果超过1M则,每次扩容1M
- 字符串的最大容量是512M

String的一些基础操作
- 普通get set
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> get name
"amber"
127.0.0.1:6379> exists name
(integer) 1
127.0.0.1:6379> del name
(integer) 1
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 批量mset,mget
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> set name2 nick
OK
127.0.0.1:6379> mget name name2
1) "amber"
2) "nick"
127.0.0.1:6379> mset name3 wade name4 hellen
OK
127.0.0.1:6379> mget name name2 name3 name4
1) "amber"
2) "nick"
3) "wade"
4) "hellen"
127.0.0.1:6379>
- 设置过期时间
- 第一种 expire
127.0.0.1:6379> set name amber
OK
127.0.0.1:6379> expire name 5
(integer) 1
127.0.0.1:6379> get name
"amber"
//等待5s
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 利用setex
setex name 时间 value
127.0.0.1:6379> setex name 5 amber
OK
127.0.0.1:6379> get name
"amber"
127.0.0.1:6379> get name
(nil)
127.0.0.1:6379>
- 自增自减
127.0.0.1:6379> set age 18
OK
127.0.0.1:6379> incr age
(integer) 19
127.0.0.1:6379> incrby age 5
(integer) 24
127.0.0.1:6379> incrby age -5
(integer) 19
127.0.0.1:6379> decr age
(integer) 18
127.0.0.1:6379>
List
Redis的list结构有点像Java中的LinkedList,但实际上地产不仅仅是简单的linkedlist,底层是quicklist(太深入了等待作者以后学习...)
特点
list的插入删除效率很高,时间复杂度为O(1),但是索引的定位就很慢,即O(n)
操作
- 左进右出(队列)
127.0.0.1:6379> lpush names amber nick wade
(integer) 3
127.0.0.1:6379> rpop names
"amber"
127.0.0.1:6379> rpop names
"nick"
127.0.0.1:6379> rpop names
"wade"
127.0.0.1:6379> rpop names
(nil)
127.0.0.1:6379>
当然你也可以左近左出(栈),可以自己实验一下。
- 索引操作
- lindex相当于java的get(int index)根据索引取值,但是因为要遍历链表,如果数据很大,导致开销增大
- ltrim key index1 index2 保留index1和index2之间的数据
127.0.0.1:6379> lpush names amber nick wade
(integer) 3
127.0.0.1:6379> lindex names 0
"wade"
127.0.0.1:6379> lindex names 1
"nick"
127.0.0.1:6379> lindex names 2
"amber"
127.0.0.1:6379> ltrim names 0 1
127.0.0.1:6379> lindex names 0
"wade"
127.0.0.1:6379> lindex names 1
"nick"
127.0.0.1:6379> lindex names 2
(nil)
127.0.0.1:6379>
hash(散列)
Redis的hash类似java中的HashMap
特点
Redis中的Hash进行rehash时区别于java中的HashMap。
在redis进行rehash时会同时保留新旧两个结构,并在后续的定时任务当中慢慢把旧的数据移动到新数据。
操作
127.0.0.1:6379> hmset person name amber age 18
OK
127.0.0.1:6379> hgetall person
1) "name"
2) "amber"
3) "age"
4) "18"
127.0.0.1:6379> hget person name
"amber"
127.0.0.1:6379> hset person gender 1
(integer) 1
127.0.0.1:6379> hgetall person
1) "name"
2) "amber"
3) "age"
4) "18"
5) "gender"
6) "1"
set
Redis中的set相当于java中的HashSet,内部相当于实现了一个字典
特点
value唯一
操作
127.0.0.1:6379> sadd names amber
(integer) 1
127.0.0.1:6379> sadd names amber
(integer) 0
127.0.0.1:6379> sadd names nick wade
(integer) 2
127.0.0.1:6379> smembers names
1) "amber"
2) "wade"
3) "nick"
zset(sorted set)
Redis中的zset相当于java中sorted set和HashMap的结合。在set的基础上还可以给value赋予score(排序的权重)
特点
zset因为有score需要排序,但是采用普通的链表查找销量过低。因此zst采用层级制度。有点类似于国家->省级->市->xxx。最底层的乡镇肯帝就是我们的L0层级了,所有的元素都串联在一起,每个几个元素就选出市位于L2,同样的道理每隔几个L2层级的元素就选出省位于L3层级。当我们插入新的节点的时候,只需要从最顶层开始进行查找定位到相应位置就行了。是不是有点儿像数组的二分查找。
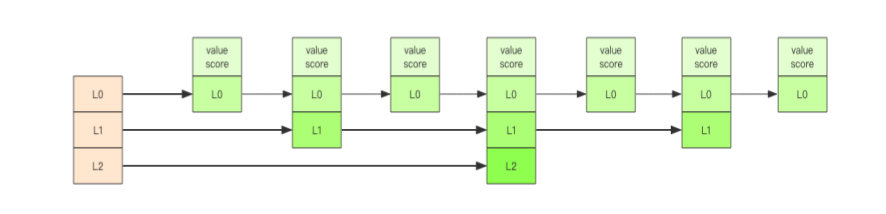
操作
其实还有一些操作,不过这里就不展示了
127.0.0.1:6379> zadd names 2 amber
(integer) 1
127.0.0.1:6379> zadd names 3 wade
(integer) 1
127.0.0.1:6379> zadd names 1 nick
(integer) 1
127.0.0.1:6379> zrange names 0 2
1) "nick"
2) "amber"
3) "wade"
127.0.0.1:6379>
数据结构知识点拓展
- redis的所有数据结构都可以设置时间
1. 设置时间
expire key 时间
2. 查看时间
ttl key

【Redis深度历险】那些年Redis的数据结构的更多相关文章
- 分布式Redis深度历险-Cluster
本文为分布式Redis深度历险系列的第三篇,主要内容为Redis的Cluster,也就是Redis集群功能. Redis集群是Redis官方提供的分布式方案,整个集群通过将所有数据分成16384个槽来 ...
- 分布式Redis深度历险-复制
Redis深度历险分为两个部分,单机Redis和分布式Redis. 本文为分布式Redis深度历险系列的第一篇,主要内容为Redis的复制功能. Redis的复制功能的作用和大多数分布式存储系统一样, ...
- Redis深度历险——核心原理与应用实践
高可用架构」的各位老铁们,你们好!你是否还记得上个月发布的文章中,有两篇深入讲解Redis的文章,分别是和,广大粉丝读者们对这两篇文章整体评价颇高.而我就是这两篇文章的原创作者「老钱」(钱文品),我是 ...
- Redis深度历险,全面解析Redis14个核心知识点
本人免费整理了Java高级资料,涵盖了Java.Redis.MongoDB.MySQL.Zookeeper.Spring Cloud.Dubbo高并发分布式等教程,一共30G,需要自己领取. 传送门: ...
- 《Redis深度历险:核心原理和应用实践》学习笔记一
1.redis五种数据结构 1.1 String字符串类型,对应java字符串类型 用户信息序列化后,可以用string类型存入redis中批量读写string类型,见效网络消耗数字类型的string ...
- 分布式Redis深度历险-Sentinel
上一篇介绍了Redis的主从服务器之间是如何同步数据的.试想下,在一主一从或一主多从的结构下,如果主服务器挂了,整个集群就不可用了,单点问题并没有解决.Redis使用Sentinel解决该问题,保障集 ...
- Redis 深度历险
学习资料 https://juejin.im/book/5afc2e5f6fb9a07a9b362527 包括下面几方面的内容 基础 应用 原理 集群 拓展 源码 to be done
- redis深度历险:核心原理与应用实践--笔记
- 《Redis深度历险:核心原理和应用实践》千帆竞发——分布式锁
随机推荐
- 微项目:一步一步带你使用SpringBoot入门(二)
今天我们来使用JPA做分页项目并且做讲解 如果是新来的朋友请回上一篇 上一篇:微项目(一) maven整合 在pom文件的dependencies依赖中导入以下依赖 <dependency> ...
- POJ 3069——Saruman's Army(贪心)
链接:http://poj.org/problem?id=3069 题解 #include<iostream> #include<algorithm> using namesp ...
- vue-cli 脚手架安装
1.安装node;选择适合自己系统的文件,下载一路next , a安装成功后,打开运行输入cmd 进入命令行: 在命令行工具中输入 npm -v 检查版本号 如果出现 则安装成功:(npm为node ...
- MongoDB 学习笔记之 分片和副本集混合运用
分片和副本集混合运用: 基本架构图: 搭建详细配置: 3个shard + 3个replicat set + 3个configserver + 3个Mongos shardrsname Primary ...
- 利用双重检查锁定和CAS算法:解决并发下数据库的一致性问题
背景 最近有一个场景遇到了数据库的并发问题.现在先由我来抽象一下,去掉不必要的繁杂业务. 数据库表book存储着每本书的阅读量,一开始数据库是空的,不存在任何的数据.当用户访问接口的时候,判断 ...
- 关于MySQL的经典例题50道
--1.学生表Student(S,Sname,Sage,Ssex) --S 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别--2.课程表 Course(C,Cname,T) - ...
- 网页布局——table布局
table 的特性决定了它非常适合用来做布局,并且表格中的内容可以自动居中,这是之前用的特别多的一种布局方式 而且也加入了 display:table;dispaly:table-cell 来支持 t ...
- Airport Express UVA - 11374
In a small city called Iokh, a train service, Airport-Express, takes residents to the airport more q ...
- 九、Executor框架
Executor框架 我们知道线程池就是线程的集合,线程池集中管理线程,以实现线程的重用,降低资源消耗,提高响应速度等.线程用于执行异步任务,单个的线程既是工作单元也是执行机制,从JDK1.5开始 ...
- 利用Echarts实现全国各个省份数据占比,图形为中国地图
最近项目需求,需要一个对于全国各个省份的数据分析,图形最好是地图的样子,这样子更为直观. 最先想到的图表插件是Echarts,他的文档相对于阿里的G2,G6更加清晰一些.在Echarts 里找到的个 ...