Multi-Dimensional Recurrent Neural Networks
Multi-Dimensional Recurrent Neural Networks
The basic idea of MDRNNs is to replace the single recurrent connection found in standard RNNs with as many recurrent connections as there are dimensions in the data. During the forward pass, at each point in the data sequence, the hidden layer of the network receives both an external input and its own activations from one step back along all dimensions.
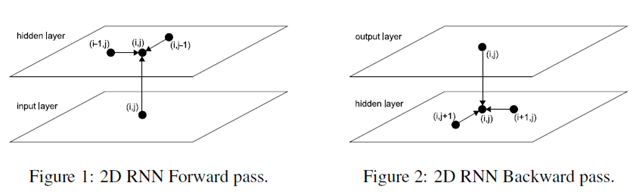
Clearly, the data must be processed in such a way that when the network reaches a poin in an n-dimensional sequence, it has already passed through all the points from which it will rechive its previous activations.
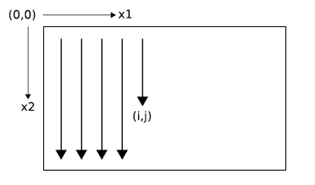
2D sequence ordering. The MDRNN forword pass starts at the origin and follows the direction of the arrows. The point(I,j) is never reached before both (i-1,j) and (i,j-1)
The forward pass of an MDRNN can then be carried out by feeding forward the input and the n previous hidden layer activations at each point in the ordered input sequence, and storing the resulting hidden layer activations at each point in the ordered input sequence, and storing the resulting hidden layer activations. Care must be taken at the sequence boundaries not to feed forward activations from points outside the sequence.
Note that each 'point' in the input sequence will in general be a multivalued vector. For example, in a two dimensional color image, the inputs could be single pixels represented by RGB triples, or blocks of pixels, or the outputs of a preprocessing method such as a discrete cosine transform.
The error gradient of an MDRNN(that is, the derivative of some objective function with respect to the network weights) can be calculated with an n-dimensional extension of the backpropagation through time(BPTT) algorithm. As with one dimensional BPTT, the sequence is processed in the reverse order of the forward pass. At each timestep, the hidden layer receives both the output error derivatives and its own n 'future' derivatives. Figure 2 illustrates the BPTT backword pass for two dimensions. Again, care must be taken at the sequence boundaries.
At a point in an n-dimensional sequence, define and respectively as the activations of the input unit and the hidden unit. Define as the weight of the connection going from unit j to unit k. Then for an n-dimensional MDRNN whose hidden layer consists of summation units with the tanh activation function, the forward pass for a sequence with dimensions can be sumarised as follows:

Defining and respectively as the derivatives of the objective function with respect to the activations of the output unit and the hidden unit at point x, the backward pass is:
Since the forward and backward pass require one pass each through the data sequence, the overall complexity of MDRNN training is linear in the number of data points and the unmber of network weights.

Multi-directional MDRNNs
For one dimensional RNNs, the problem of multi-directional context was solved in 1997 by the introduction of bidirectional recurrent neural networks (BRNNs). BRNNs contain two separate hidden layers that process the input sequence in the forward and reverse directions. The two hidden layers are connected to a single output layer, thereby providing the network with access to both past and future context.
BRNNs can be extended to n-dimensional data by using separate hidden layers, each of which processes the sequence using the ordering defined above, but with a different choice of axes.
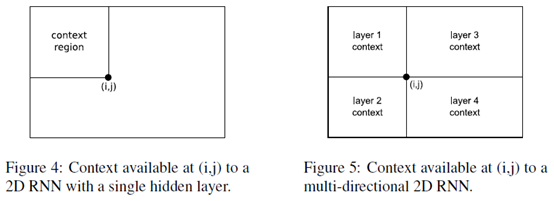
More specifically, the axes are chosen so that their origins lie on the the vertices of the sequence. The 2 dimensional case is illustrated in Figure 6.

As before, the hidden layers are connected to a single output layer, which now has access to all surrounding context.
If the size of the hidden layers is held constan, multi-direcitonal MDRNNs scales as O() for n-dimensional data. In practive however, we have found that using small layers gives better results than 1 large layer with the same overall number of weights, presumably because the data processing is shared between the hidden layers. This also holds in one dimension, as previous experiments have demonstrated. In any case the complexity of the algorithm remains linear in the number of data points and the number of parameters, and the number of parameters is independent of the data dimensionality.
For a multi-directional MDRNN, the forward and backward passes through an n-dimensional sequence can be summarized as follows:


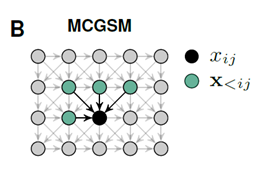
MCGSM
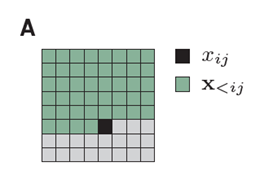
We factorize the distribution of images such that the prediction of a pixel(black) may depend on any pixel in the upper-left green region.
A graphical model representation of an MCGSM with a causal neighborhood limited to a small region.
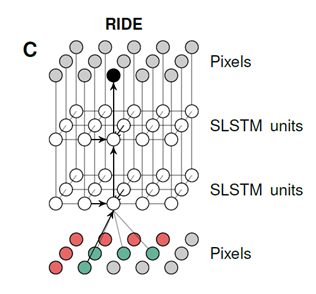
A visualization of our recurrent iamge model with two layers of spatial LSTMs. The pixels of the image are represented twice and some arrows are omitted for clarity. Through feedforward connections, the prediction of a pixel depends directly on its neighborhood(gre-e),but through recurrent connections it hs access to the information in a much larger region(r-ed).

Multi-Dimensional Recurrent Neural Networks的更多相关文章
- The Unreasonable Effectiveness of Recurrent Neural Networks (RNN)
http://karpathy.github.io/2015/05/21/rnn-effectiveness/ There’s something magical about Recurrent Ne ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- Attention and Augmented Recurrent Neural Networks
Attention and Augmented Recurrent Neural Networks CHRIS OLAHGoogle Brain SHAN CARTERGoogle Brain Sep ...
- cs231n spring 2017 lecture10 Recurrent Neural Networks 听课笔记
(没太听明白,下次重新听一遍) 1. Recurrent Neural Networks
- 第十四章——循环神经网络(Recurrent Neural Networks)(第一部分)
由于本章过长,分为两个部分,这是第一部分. 这几年提到RNN,一般指Recurrent Neural Networks,至于翻译成循环神经网络还是递归神经网络都可以.wiki上面把Recurrent ...
- 第十四章——循环神经网络(Recurrent Neural Networks)(第二部分)
本章共两部分,这是第二部分: 第十四章--循环神经网络(Recurrent Neural Networks)(第一部分) 第十四章--循环神经网络(Recurrent Neural Networks) ...
- Pixel Recurrent Neural Networks翻译
Pixel Recurrent Neural Networks 目前主要在用的文档存放: https://www.yuque.com/lart/papers/prnn github存档: https: ...
- 循环神经网络(Recurrent Neural Networks, RNN)介绍
目录 1 什么是RNNs 2 RNNs能干什么 2.1 语言模型与文本生成Language Modeling and Generating Text 2.2 机器翻译Machine Translati ...
- 《转》循环神经网络(RNN, Recurrent Neural Networks)学习笔记:基础理论
转自 http://blog.csdn.net/xingzhedai/article/details/53144126 更多参考:http://blog.csdn.net/mafeiyu80/arti ...
随机推荐
- Junit-@Annotation-动态代理-类加载器
一.测试单元 概述:用于测试JAVA代码的工具类,已内置在Eclipse中; 格式: 1.在方法的上面添加@Test; 2.对被测试的方法的要求:权限- ...
- MySQL连表Update修改数据
设想两张表,如下 table A field id field name table B field id filed my_name 现在希望将表B中的my_name中的内容“拷贝”到表A中对应的n ...
- [LoadRunner]录制启动时报“The JVM could not be started……”错误解决方案
在LR准备点击录制java over http协议时,程序报如下错误: 报错提示是设置的JVM值设置问题,导致不能启动. 解决方案一 点击F4快捷按钮,会弹出以下界面,在选中的位置选择对应的java路 ...
- Jquery ajax中表单提交被拦截的问题处理方法
在实际开发项目中,由于要做支付宝的批量退款处理,需要用到ajax中去提交表单数据,项目截图如下: 由于在第二张截图“确认退款”那里需要异步ajax提交数据到服务器处理信息,处理成功后将返回的数据装载到 ...
- 事务回滚 DEMO
因为有些事物回滚 查询的时候 可能查出来空值 我们肯定不愿意把空值添加数据库里面 一般基本的是这么写 if (object_id('add_T_Disclose_DiscloseList', 'P' ...
- Problem C: 查找最大元素
Problem C: 查找最大元素 Time Limit: 1 Sec Memory Limit: 64 MBSubmit: 786 Solved: 377[Submit][Status][Web ...
- 2018.4.9 Ubuntu install kreogist-mu
先下载kreogist m文件 然后在下载哪里右键点击打开终端 输入sudo dpkg -i + 文件名 输入密码 下一步会显示 未安装未安装软件包 libmpv1. jiexialai要处理 sud ...
- 厌食?暴食?试试这个 VR 新疗法
今日导读 “我知道我要吃饭,但我真的什么都吃不下.” “我脑子里想的只有吃东西,吃吃吃!” ....... 作为一个正常人,我们完全无法想象患厌食症或贪食症人群所受的痛苦.长期的厌食,会使一个人瘦的只 ...
- redis基础知识学习
数据结构:1.String 添加: set key value get key getset key value (先get再set) incr key (key对应value原子性递增1) decr ...
- 自行实现一个简易RPC框架
10分钟写一个RPC框架 1.RpcFramework package com.alibaba.study.rpc.framework; import java.io.ObjectInputStrea ...