HBase总结 LSM理解
转载的文章,觉得写的比较好
讲LSM树之前,需要提下三种基本的存储引擎,这样才能清楚LSM树的由来:
- 哈希存储引擎 是哈希表的持久化实现,支持增、删、改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统。对于key-value的插入以及查询,哈希表的复杂度都是O(1),明显比树的操作O(n)快,如果不需要有序的遍历数据,哈希表就是your Mr.Right
- B树存储引擎是B树(关于B树的由来,数据结构以及应用场景可以看之前一篇博文)的持久化实现,不仅支持单条记录的增、删、读、改操作,还支持顺序扫描(B+树的叶子节点之间的指针),对应的存储系统就是关系数据库(Mysql等)。
- LSM树(Log-Structured Merge Tree)存储引擎和B树存储引擎一样,同样支持增、删、读、改、顺序扫描操作。而且通过批量存储技术规避磁盘随机写入问题。当然凡事有利有弊,LSM树和B+树相比,LSM树牺牲了部分读性能,用来大幅提高写性能。
通过以上的分析,应该知道LSM树的由来了,LSM树的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。极端的说,基于LSM树实现的HBase的写性能比Mysql高了一个数量级,读性能低了一个数量级。
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能
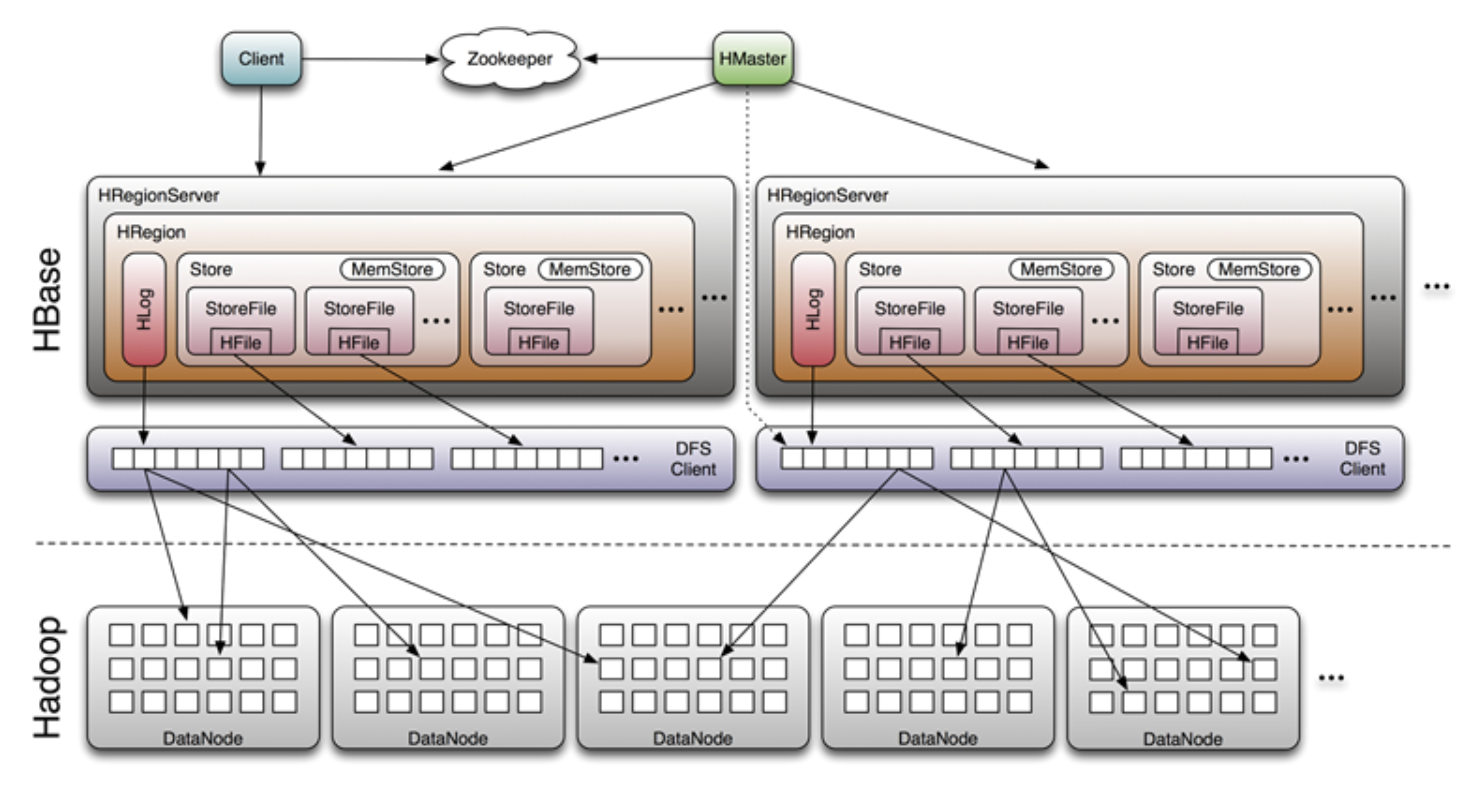
以上这些大概就是HBase存储的设计主要思想,这里分别对应说明下:
- 因为小树先写到内存中,为了防止内存数据丢失,写内存的同时需要暂时持久化到磁盘,对应了HBase的MemStore和HLog
- MemStore上的树达到一定大小之后,需要flush到HRegion磁盘中(一般是Hadoop DataNode),这样MemStore就变成了DataNode上的磁盘文件StoreFile,定期HRegionServer对DataNode的数据做merge操作,彻底删除无效空间,多棵小树在这个时机合并成大树,来增强读性能。
关于LSM Tree,对于最简单的二层LSM Tree而言,内存中的数据和磁盘你中的数据merge操作,如下图
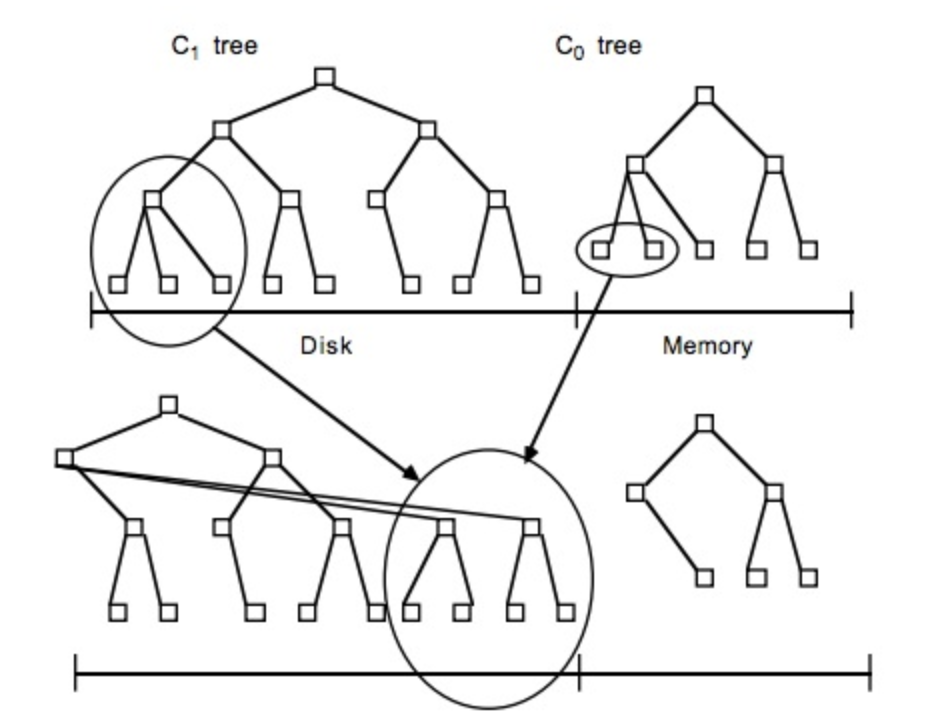
lsm tree,理论上,可以是内存中树的一部分和磁盘中第一层树做merge,对于磁盘中的树直接做update操作有可能会破坏物理block的连续性,但是实际应用中,一般lsm有多层,当磁盘中的小树合并成一个大树的时候,可以重新排好顺序,使得block连续,优化读性能。
hbase在实现中,是把整个内存在一定阈值后,flush到disk中,形成一个file,这个file的存储也就是一个小的B+树,因为hbase一般是部署在hdfs上,hdfs不支持对文件的update操作,所以hbase这么整体内存flush,而不是和磁盘中的小树merge update,这个设计也就能讲通了。内存flush到磁盘上的小树,定期也会合并成一个大树。整体上hbase就是用了lsm tree的思路。
HBase总结 LSM理解的更多相关文章
- sstable, bigtable,leveldb,cassandra,hbase的lsm基础
先看懂文献1和2 1. 先了解sstable.SSTable: Sorted String Table [2] [10] WiscKey: 类似myisam, key value分离, 根据ssd优 ...
- <HBase><读写><LSM>
Overview HBase中的一个big table,首先会按行划分成一些region(这些region之间是有序的,由startkey保证),每个region分配到不同的节点进行存储.因此,reg ...
- 快速理解 Phoenix : SQL on HBASE
转自:http://blog.csdn.net/colorant/article/details/8645081 ==是什么 == 目标Scope EasyStandard SQL access on ...
- hbase概念
1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有的HBase中的理念,都可 ...
- HBase概念及表格设计
HBase概念及表格设计 1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有 ...
- HBase写请求分析
HBase作为分布式NoSQL数据库系统,不单支持宽列表.而且对于随机读写来说也具有较高的性能.在高性能的随机读写事务的同一时候.HBase也能保持事务的一致性. 眼下HBase仅仅支持行级别的事务一 ...
- [Spark] 04 - HBase
BHase基本知识 基本概念 自我介绍 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”. ...
- 【转帖】LSM树 和 TSM存储引擎 简介
LSM树 和 TSM存储引擎 简介 2019-03-08 11:45:23 长烟慢慢 阅读数 461 收藏 更多 分类专栏: 时序数据库 版权声明:本文为博主原创文章,遵循CC 4.0 BY-S ...
- HBase原理 – 分布式系统中snapshot是怎么玩的?(转载)
snapshot(快照)基础原理 snapshot是很多存储系统和数据库系统都支持的功能.一个snapshot是一个全部文件系统.或者某个目录在某一时刻的镜像.实现数据文件镜像最简单粗暴的方式是加锁拷 ...
随机推荐
- [BZOJ 2480] [SPOJ 3105] Mod
Description 已知数 \(a,p,b\),求满足 \(a^x\equiv b\pmod p\) 的最小自然数 \(x\). Input 每个测试文件中最多包含 \(100\) 组测试数据. ...
- Vivado寄存器初始值问题
前言 本复位只针对Vivado中的寄存器复位. 什么时候需要复位?到底要不要复位?怎么复位?复位有什么卵用? 该复位的寄存器需要复位,复位使得寄存器恢复初始值,有的寄存器并不需要复位(数据流路径上). ...
- beego框架返回json数据
一.routers路由 package routers import ( "mybeego/controllers" "github.com/astaxie/beego& ...
- (二分查找 拓展) leetcode 34. Find First and Last Position of Element in Sorted Array && lintcode 61. Search for a Range
Given an array of integers nums sorted in ascending order, find the starting and ending position of ...
- 第四届CCCC团体程序设计天梯赛 后记
一不小心又翻车了,第二次痛失200分 1.开局7分钟A了L2-3,一看榜已经有七个大兄弟排在前面了,翻车 * 1 2.把L1-3 A了18分,留了两分准备抢顽强拼搏奖,最后五秒钟把题过了,万万没想到还 ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- SpringCloud笔记一:扫盲
目录 前言 什么是微服务? 微服务的优缺点是什么? 微服务之间是如何通讯的? SpringCloud和Dubbo有哪些区别? SpringCloud和SpringBoot的关系? 什么是服务熔断?什么 ...
- [译]Ocelot - Big Picture
原文 目录 Big Picture Getting Started Configuration Routing Request Aggregation Service Discovery Authen ...
- 9、el表达式的使用
一.EL表达式的作用: 1).使用变量访问web域中存储的对象 ${user } 2).访问javabean的属性 ${user.address.city } 3).执行基本的逻辑运算(el表达式 ...
- windows 下 bat 计划任务删除保留时间内文件
date windows 打印时间戳 年:echo %date:~,% 月:echo %date:~,% 日:echo %date:~,% 星期:echo %date:~,% 小时:echo %t ...