python3 爬取百合网的女人们和男人们
学Python也有段时间了,目前学到了Python的类。个人感觉Python的类不应称之为类,而应称之为数据类型,只是数据类型而已!只是数据类型而已!只是数据类型而已!重要的事情说三篇。
据书上说一个.py(常量、全局变量、函数、数据类型)文件为一个模块,那么就有了一种感觉:常量、全局变量、函数、数据类型是同一“级别的”。在此不多说了,收回自己的心思来看爬虫吧!
1、进百合网官网,单击“搜索”、单击“基本搜索”,这时会跳向另一个页面,该页面为登录页面(如图):
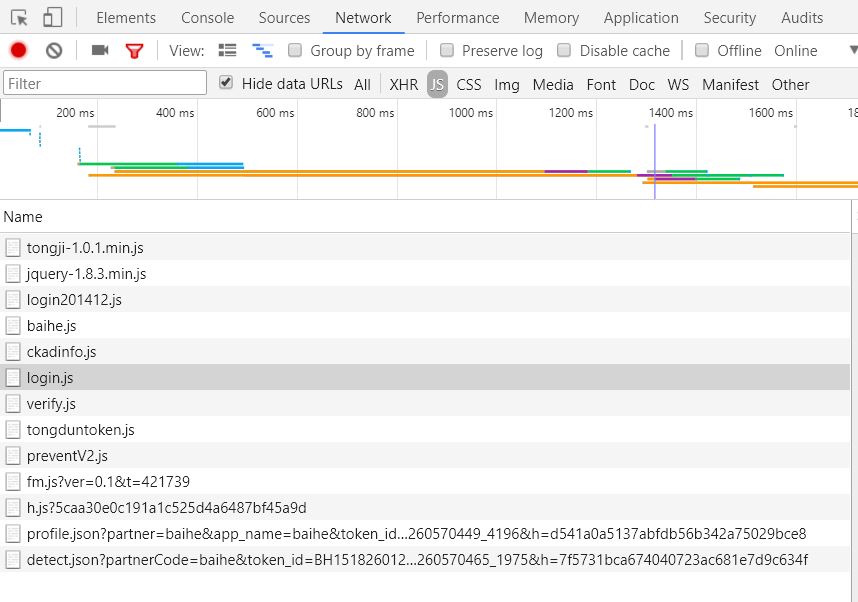
2、找到login.js,具体步骤:F12、F5、network、js(如图):
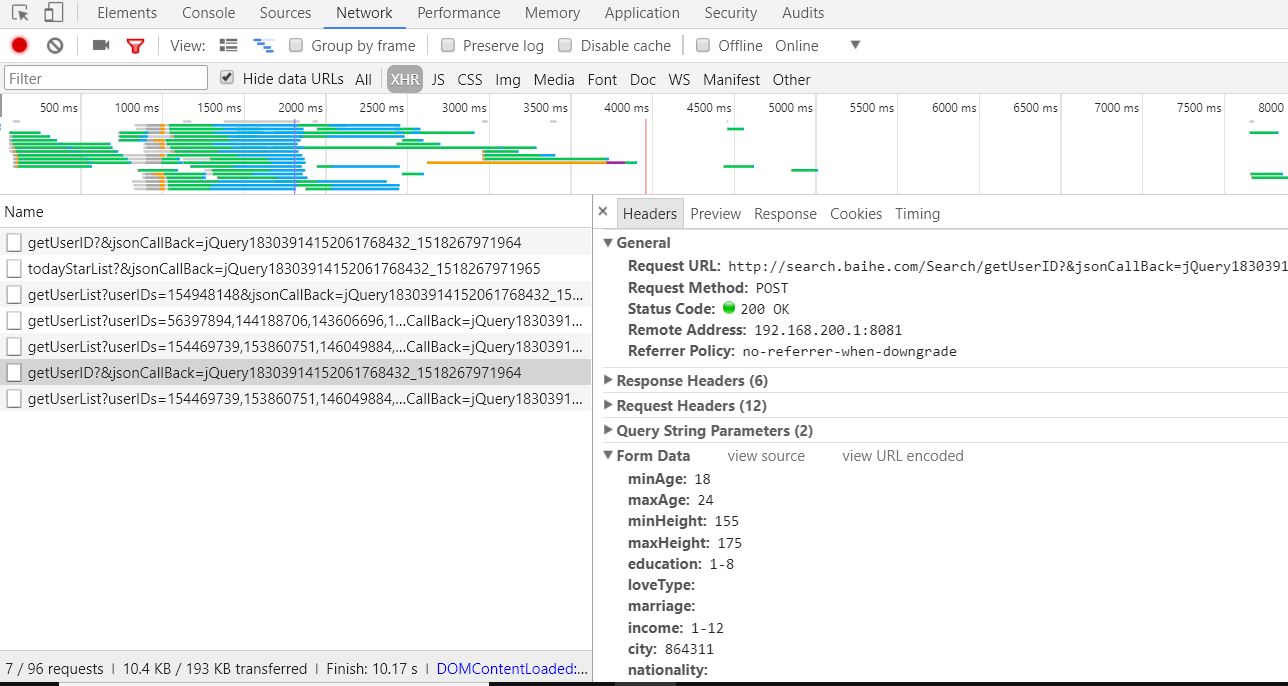
3、找登录时的异步请求,该请求在login.js中(如图):

4、单击“基本搜索”,会得到两个异步请求
1:获取160个id (如图):
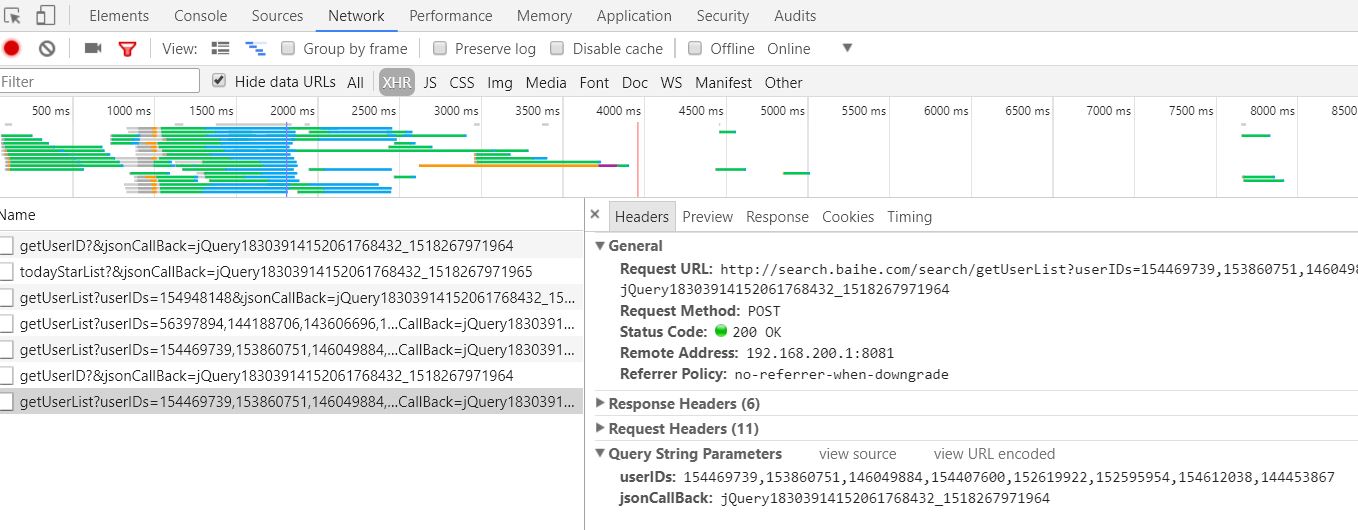
2:根据id得到用户详细信息,为json数据(如图):
说了这么多,该上代码了(总共261行):
baihe.py:
#__author: "YuWei"
#__date: 2018/2/4
import requests
import time
import pymssql
import os # 8个人为一组,该常量用于判断列表的长度是否与网站一致
FING_INDEX = 8
# 请求头,伪装成浏览器
HEADERS = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0'}
# 代理ip,防止被百合网封ip
HTTP_IP_PROXIES_1 = 'http://211.151.58.5:80'
HTTP_IP_PROXIES_2 = 'http://192.168.200.1:8081' def baihe_db(personal):
"""
数据库相关的操作 :param personal: 为字典类型,封装着个人具体信息
:return: 无
"""
# 数据连接
conn = pymssql.connect(host='localhost', user='YUANWEI', password='123456c', database='Baihe',charset='utf8')
cur = conn.cursor() # 游标
sql = """insert into users values({},'{}',{},'{}','{}','{}',{},'{}','{}','{}','{}');""" \
.format(personal['userID'], personal['nickname'], personal['age'], '男' if personal['gender'] == "" else '女',
personal['cityChn'], personal['educationChn'], personal['height'],
'没房' if personal['housing'] == 0 else '有房', '没车' if personal['car'] == 0 else '有车',
personal['incomeChn'],personal['marriageChn'])
print('sql: ', sql)
try:
cur.execute(sql) # 执行sql语句
save_photo(personal, get_miss_photo_binary(personal['headPhotoUrl'])) # 保存头像
print('成功获取该用户',personal['userID'])
except pymssql.IntegrityError:
print('该用户已存在 ',personal['userID'])
except SystemError as sy: # 向err.txt导入错误日志
with open('err.txt','a',encoding='utf8') as file:
file.write(personal['nickname'] + ' ' + str(personal['userID']) + ' 错误信息:' + str(sy) + '\n') # 写
except pymssql.ProgrammingError as pp:
with open('err.txt','a',encoding='utf8') as file:
file.write(personal['nickname'] + ' ' + str(personal['userID']) + ' 错误信息:' + str(pp) + '\n')
conn.commit() # 提交
time.sleep(1)
cur.close()
conn.close() def personal_data(lists):
"""
获取一组的详细信息,最多为8个 :param lists: 列表类型,封装着一组信息
:return: 无
"""
for personal_data_dict in lists: # 遍历一组信息
baihe_db(personal_data_dict) def get_miss_photo_binary(photo_url):
"""
获取照片的二进制数据 :param photo_url: 个人头像的url
:return: 二进制数据
"""
binary = ''
try:
# 向服务器发送get请求,下载图片的二进制数据
binary = requests.get(photo_url, headers=HEADERS,proxies={"http": HTTP_IP_PROXIES_2}).content
except requests.exceptions.MissingSchema as rem:
print(rem)
except requests.exceptions.ProxyError: # 代理网络连接慢或无网络
time.sleep(5)
# 递归调用get_miss_photo_binary()
get_miss_photo_binary(photo_url)
return binary def save_photo(personal,binary):
"""
以'E:/Baihe/1/'为文件目录路径 或 以'E:/Baihe/0/'为文件目录路径
以 name + id + .jpg 或 以 id + .jpg 为文件名
有可能无相片 :param personal: 字典类型,封装着个人具体信息
:param binary: 二进制数据
:return: 无
"""
if binary != '':
file_path = 'E:/Baihe/1/' if personal['gender'] == "" else 'E:/Baihe/0/' #
if not os.path.exists(file_path): # 如果该路径不存在
os.makedirs(file_path) # 创建该路径
try:
# 向file_path路径保存图片
with open(file_path + personal['nickname'] + str(personal['userID']) + '.jpg','wb') as file:
file.write(binary)
except OSError:
with open(file_path + str(personal['userID']) + '.jpg','wb') as file:
file.write(binary) def no_exact_division(miss_id_list):
"""
当包含用户id的列表长度不能被8整除且列表长度小于8时调用该方法 :param miss_id_list: 为列表类型,封装着用户id
:return: 无
"""
miss_info_lists = ba.get_miss_info(miss_id_list) # 获取列表的个人信息
personal_data(miss_info_lists) # 遍历一组的信息 class Baihe(object): def __init__(self,account,password):
"""
初始化
:param account: 账号
:param password: 密码
"""
self.is_begin = True # 开始爬取数据
self.index = 0 # 控制self.info长度为8个
self.info = [] # 临时保存用户id
self.page = 61 # 页码
self.account = account # 账号
self.password = password # 密码
self.req = requests.session() # 会话,保证Cookie一致 def login(self):
"""
登录 :return: 无
"""
# 登录的url
url_login = 'http://my.baihe.com/Getinterlogin/gotoLogin?event=3&spmp=4.20.87.225.1049&' \
'txtLoginEMail={}&txtLoginPwd={}'.format(self.account,self.password)
login_dict = {}
try:
# 向服务器发送get请求
login_dict = self.req.get(url_login,headers=HEADERS,proxies={"http": HTTP_IP_PROXIES_1},timeout=500).json()
except requests.exceptions.ProxyError: # 代理网络连接慢或无网络
time.sleep(5)
# 递归调用self.login()
self.login()
time.sleep(3)
print('login: ',login_dict)
self.req.keep_alive = False # 关闭会话多余的连接
if login_dict['data'] == 1:
print('登录成功')
else:
print('登录失败, 30分钟以后自动登录。。。。。。。。')
time.sleep(1800)
# 递归调用self.login()
self.login()
print('login is cookie ', requests.utils.dict_from_cookiejar(self.req.cookies)) # 查看登录后的会话cookie def filtrate_miss(self,pages):
"""
根据条件筛选数据,不提供条件参数 :param pages: 页码。该网站只提供62页的数据
:return: 包含160个用户的id的列表
"""
time.sleep(2)
# 获取用户id的url
url_miss = 'http://search.baihe.com/Search/getUserID'
# from表单数据
params_miss = {"minAge": 18, "maxAge": 85, "minHeight": 144, "maxHeight": 210, "education": '1-8',
"income": '1-12', "city": -1, "hasPhoto": 1, "page": pages, "sorterField": 1}
miss_dict = {}
try:
# 发送post请求
miss_dict = self.req.post(url_miss,data=params_miss,headers=HEADERS,proxies={'http':HTTP_IP_PROXIES_2}).json()
except requests.exceptions.ProxyError: # 代理网络连接慢或无网络
time.sleep(5)
# 递归调用self.filtrate_miss()
self.filtrate_miss(pages)
time.sleep(2)
print('miss is cookies ', requests.utils.dict_from_cookiejar(self.req.cookies)) # 查看筛选后的会话cookie
print('miss dict: ',miss_dict)
print(len(miss_dict['data']),'个')
return miss_dict['data'] def get_miss_info(self,infos):
"""
获取用户详细信息 :param infos: 列表类型,封装着个人id,可能为一组(8),或小于8个
:return: 包含一组的详细信息
"""
if len(infos) == FING_INDEX: # infos列表长度等于8时
url_info = 'http://search.baihe.com/search/getUserList?userIDs={},{},{},{},{},{},{},{}'\
.format(infos[0],infos[1],infos[2],infos[3],infos[4],infos[5],infos[6],infos[7])
else: # infos列表长度小于8时
bracket = '' # 参数userIDs的值
for lens in range(len(infos)):
bracket += (str(infos[lens]) + ',') # 构造该表示:"{},{},{},{},{},{},{},{},"
# 获取用户详细信息的url bracket[:len(bracket)-1]: 分片,干掉最后一个“,”
url_info = 'http://search.baihe.com/search/getUserList?userIDs=' + bracket[:len(bracket)-1]
miss_info = {}
try:
# 发送post请求
miss_info = self.req.post(url_info,headers=HEADERS,proxies={'http':HTTP_IP_PROXIES_2}).json()
except requests.exceptions.ProxyError: # 代理网络连接慢或无网络
time.sleep(5)
# 递归调用self.get_miss_info()
self.get_miss_info(infos)
time.sleep(2)
try:
return miss_info['data']
except KeyError:
time.sleep(2)
self.get_miss_info(infos) def exact_division(self,miss_id_list):
"""
当包含用户id的列表长度能被8整除或包含用户id的列表长度不能被8整除且包含用户id的列表长度大于8 :param miss_id_list: id信息列表(160)
:return: 无
"""
for user_id in miss_id_list:
self.index += 1
self.info.append(user_id)
if ba.index == FING_INDEX:
print('user id: ', self.info)
miss_info_list = ba.get_miss_info(self.info) #
if None != miss_info_list:
# 使self.index,self.info为初值,以便8人一组
self.index = 0
self.info = []
print('miss info list: ', miss_info_list)
personal_data(miss_info_list) # 遍历一组(8)的信息
else:
print('miss info list is null')
continue def main(self):
"""
具体实施 :return: 无
"""
self.login() # 登录
while self.is_begin: # 开始
print('正在获取',self.page,'页.......')
miss_id_list = self.filtrate_miss(self.page) # 获取用户id列表
if len(miss_id_list) != 0: # 列表有id
num = len(miss_id_list) % FING_INDEX # 模运算
if num == 0: # 被8整除
self.exact_division(miss_id_list)
else: # 没有被8整除 , 虽然该分支没有执行,但还是要加上。因为该网站总是提供160个id
print('余数: ',num)
if len(miss_id_list) > FING_INDEX: # id列表的长度大于8
copy_miss_id_list = miss_id_list[:len(miss_id_list) - num] # 分片 取8个一组
self.exact_division(copy_miss_id_list)
no_exact_division(miss_id_list[len(miss_id_list) - num:]) # 余下的个人信息
else:
no_exact_division(miss_id_list) # 小于8个人的个人的信息
else:
print('数据已爬完。。。。。')
self.is_begin = False
self.page += 1
time.sleep(10)
# 运行
if __name__ == '__main__':
ba = Baihe('xxxxxxx', 'xxxxxxxxxx')
ba.main()
温馨提示:想爬女的,就找个性别为男的账号。想爬男的,就找个性别为女的账号。
如果要简单的分析一下所爬的数据,建议用男的账号,女的账号反复爬那么3-5次,这样数据才有有效性。
python3 爬取百合网的女人们和男人们的更多相关文章
- Python爬虫 爬取百合网的女人们和男人们
学Python也有段时间了,目前学到了Python的类.个人感觉Python的类不应称之为类,而应称之为数据类型,只是数据类型而已!只是数据类型而已!只是数据类型而已!重要的事情说三篇. 据书上说一个 ...
- 基于爬取百合网的数据,用matplotlib生成图表
爬取百合网的数据链接:http://www.cnblogs.com/YuWeiXiF/p/8439552.html 总共爬了22779条数据.第一次接触matplotlib库,以下代码参考了matpl ...
- Python3爬取豆瓣网电影信息
# -*- coding:utf-8 -*- """ 一个简单的Python爬虫, 用于抓取豆瓣电影Top前250的电影的名称 Language: Python3.6 ...
- Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码
题记: 11月14日早晨8点,人人网发布公告,宣布人人公司将人人网社交平台业务相关资产以2000万美元的现金加4000万美元的股票对价出售予北京多牛传媒,自此,人人公司将专注于境内的二手车业务和在美国 ...
- python3爬取网页
爬虫 python3爬取网页资源方式(1.最简单: import'http://www.baidu.com/'print2.通过request import'http://www.baidu.com' ...
- 网络爬虫之定向爬虫:爬取当当网2015年图书销售排行榜信息(Crawler)
做了个爬虫,爬取当当网--2015年图书销售排行榜 TOP500 爬取的基本思想是:通过浏览网页,列出你所想要获取的信息,然后通过浏览网页的源码和检查(这里用的是chrome)来获相关信息的节点,最后 ...
- 使用python爬取东方财富网机构调研数据
最近有一个需求,需要爬取东方财富网的机构调研数据.数据所在的网页地址为: 机构调研 网页如下所示: 可见数据共有8464页,此处不能直接使用scrapy爬虫进行爬取,因为点击下一页时,浏览器只是发起了 ...
- Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行 这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
随机推荐
- PL/SQL游标详解
刚打开游标的时候,是位于一个空行,要用fetch into 才能到第一行. 只是要注意用更新游标的时候,不能在游标期间commit. 否则会报ORA-01002: fetch out of seque ...
- HDU 2544 最短路(模板题——Floyd算法)
题目: 在每年的校赛里,所有进入决赛的同学都会获得一件很漂亮的t-shirt.但是每当我们的工作人员把上百件的衣服从商店运回到赛场的时候,却是非常累的!所以现在他们想要寻找最短的从商店到赛场的路线,你 ...
- IO代码记忆
FileWriter fw = new FileWriter("hello.txt"); String s = "hello world"; fw.write( ...
- 学而精计算机公共基础学习之路TEST1
算法 一:算法基本概念 算法是个什么概念学了这么久的程序尽然没有听说过,其实算法就是为了解决问题那么怎么准确完整的解决这个问题就是算法.所以我们所写的程序就可以说为对算法的描述,但是程序编制是不能有于 ...
- dede织梦怎么修改description的字数
织梦在调用描述的时候都会使用description来调用描述,想要更改字数也可以控制调用的字数,但是就算是这样更改也是有字数限制的,描述的字数是不能没有限制. 在模板中调用描述的标签一般有四种: 1: ...
- 《并行程序设计导论》——OpenMP
OpenMP看着很好,实际上坑很多. 如果真的要求性能和利用率,还是专门写代码吧.而且MS的VS里只有2.X的版本.
- Assembly oth
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- ScrollView(RecyclerView等)为什么会自动滚动原理分析,还有阻止自动滑动的解决方案
引言,有一天我在调试一个界面,xml布局里面包含Scroll View,里面嵌套了recyclerView的时候,界面一进去,就自动滚动到了recyclerView的那部分,百思不得其解,上网查了好多 ...
- JavaScript Math(数学对象)
Math(数学对象) Math 算术函数和常量 Math.abs( ) 计算绝对值 Math.acos( ) 计算反余弦值 Math.asin( ) 计算反正弦值 Math.atan( ) 计算反正切 ...
- python_7_列表
什么是列表? --一种数据类型 -- 形式:[值1,值2,[值a,值b],值3] --可以嵌套 #!/usr/bin/python3 list_a = [1, 2, [3, 'a']] 对于 ...