kafka---broker 保存消息
1 、存储方式
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件),如下:
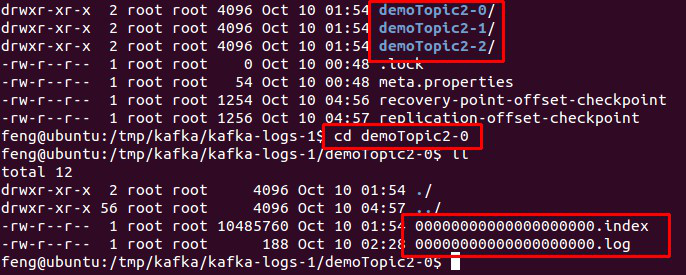
图.4
2 、存储策略
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
1. 基于时间:log.retention.hours=168
2. 基于大小:log.retention.bytes=1073741824
需要注意的是,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高 Kafka 性能无关。
3、 topic 创建与删除
3.1 创建 topic
创建 topic 的序列图如下所示:
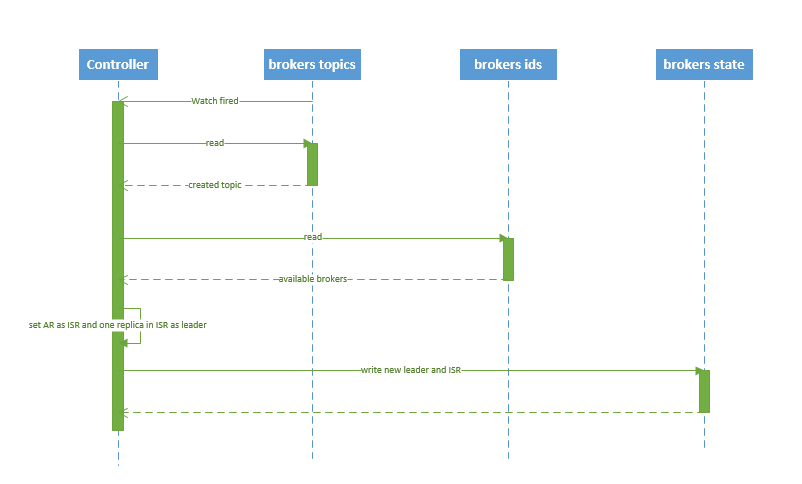
图.5
流程说明:
1. controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
2. controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition:
2.1 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR
2.2 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state
3. controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest。
3.2 删除 topic
删除 topic 的序列图如下所示:
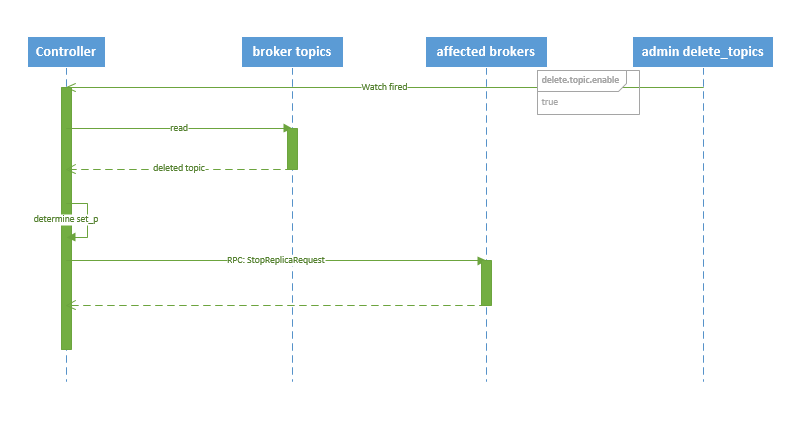
图.6
流程说明:
1. controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
2. 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。
kafka---broker 保存消息的更多相关文章
- Kafka介绍与消息队列
消息队列的好处: 消息队列(Message Queue) 消息: 网络中的两台计算机或者两个通讯设备之间传递的数据.例如说:文本.音乐.视频等内容. 队列:一种特殊的线性表(数据元素首尾相接),特殊之 ...
- spark streaming 接收kafka消息之三 -- kafka broker 如何处理 fetch 请求
首先看一下 KafkaServer 这个类的声明: Represents the lifecycle of a single Kafka broker. Handles all functionali ...
- 【原创】Kafka 0.11消息设计
Kafka 0.11版本增加了很多新功能,包括支持事务.精确一次处理语义和幂等producer等,而实现这些新功能的前提就是要提供支持这些功能的新版本消息格式,同时也要维护与老版本的兼容性.本文将详细 ...
- Kafka如何保证消息不丢失不重复
首先需要思考下边几个问题: 消息丢失是什么造成的,从生产端和消费端两个角度来考虑 消息重复是什么造成的,从生产端和消费端两个角度来考虑 如何保证消息有序 如果保证消息不重不漏,损失的是什么 大概总结下 ...
- Kafka设计解析(十六)Kafka 0.11消息设计
转载自 huxihx,原文链接 [原创]Kafka 0.11消息设计 目录 一.Kafka消息层次设计 1. v1格式 2. v2格式 二.v1消息格式 三.v2消息格式 四.测试对比 Kafka 0 ...
- kafka broker
在server.properties文件中配置: 1.broker.id kafka集群是由多个节点组成的,每个节点称为一个broker,中文翻译是代理.每个broker都有一个不同的brokerId ...
- kafka实现无消息丢失与精确一次语义(exactly once)处理
在很多的流处理框架的介绍中,都会说kafka是一个可靠的数据源,并且推荐使用Kafka当作数据源来进行使用.这是因为与其他消息引擎系统相比,kafka提供了可靠的数据保存及备份机制.并且通过消费者位移 ...
- Kafka作为分布式消息系统的系统解析
Kafka概述 Apache Kafka由Scala和Java编写,基于生产者和消费者模型作为开源的分布式发布订阅消息系统.它提供了类似于JMS的特性,但设计上又有很大区别,它不是JMS规范的实现,如 ...
- RabbitMQ,RocketMQ,Kafka 事务性,消息丢失和消息重复发送的处理策略
消息队列常见问题处理 分布式事务 什么是分布式事务 常见的分布式事务解决方案 基于 MQ 实现的分布式事务 本地消息表-最终一致性 MQ事务-最终一致性 RocketMQ中如何处理事务 Kafka中如 ...
随机推荐
- Problem : 1012 ( u Calculate e )
/*tips:本题只有输入,没有输出,在线测试只检测结果,所以将前面几个结果罗列出来就OK了.为了格式输出问题纠结了半天,最后答案竟然还是错的....所以啊,做题还是得灵活变通.*/ #include ...
- java函数回调
Class A实现接口CallBack callback--背景1 class A中包含一个class B的引用b --背景2 class B有一个参数为callback的方法f(CallBack c ...
- Java爬虫爬取网站电影下载链接
之前有看过一段时间爬虫,了解了爬虫的原理,以及一些实现的方法,本项目完成于半年前,一直放在那里,现在和大家分享出来. 网络爬虫简单的原理就是把程序想象成为一个小虫子,一旦进去了一个大门,这个小虫子就像 ...
- 面试题中遇到的算法与js技巧
近一周在忙着面试,本月第一次更博,甚是想念. 基本上大公司都会要求一些算法或者数据结构类的东西,这方面自己还不是很精通,只能一步一个脚印来积累了. 1.查询字符串获取对象数据,可自行根据需求选择格式, ...
- 如何在IOS上调试Hybrid应用
最近在找关于在xcode上调试Hybrid应用的方法,比如我想进行断点调试.日志打印.屏幕适配等等,刻意去搜了下方法,虽然之前已经大致知道了,这里系统归纳一下,原文在https://developer ...
- php正则相关知识点
关于正则,其实简单就是搜索和匹配.php,java,python等都是支持正则的,php正则兼容perl.好多同学觉得正则比较难,比较抽象,其实正则是非常简单的,主要是一个熟悉和反复练习的结果,还有一 ...
- JavaOOP-集合框架
1.Java集合框架包含的内容 Java集合框架为我们提供了一套性能优良,使用方便的接口和类,它们都位于在java.util包中. Collection 接口存储一组不唯一,无序的对象. List 接 ...
- php中require、require_once、include、include_once类库重复引入效率问题详解
首先我详细说下这四个引入函数 include() 与require() 的功能相同 唯一不同:require()不管是否被执行,只要存在,php在执行前都会预引入,include()则是执行到该语句时 ...
- 四则运算程序(java基于控制台)
四则运算题目生成程序(基于控制台) 一.题目描述: 1. 使用 -n 参数控制生成题目的个数,例如 Myapp.exe -n 10 -o Exercise.txt 将生成10个题目. 2. 使用 -r ...
- 20162308 实验二《Java面向对象程序设计》实验报告
20162308 实验二<Java面向对象程序设计>实验报告 实验内容 初步掌握单元测试和TDD 理解并掌握面向对象三要素:封装.继承.多态 初步掌握UML建模 熟悉S.O.L.I.D原则 ...