一个简单的HTML5 Web Worker 多线程与线程池应用
笔者最近对项目进行优化,顺带就改了些东西,先把请求方式优化了,使用到了web worker。发现目前还没有太多对web worker实际使用进行介绍使用的文章,大多是一些API类的讲解,除了涉及到一些WebGL的文章,所以总结了这个文章,给大家参考参考。以下内容以默认大家对web worker已经有了初步了解,不会讲解基础知识。
一、为什么要开子线程
笔者这个项目是一个存储系统的中后台管理GUI,一些数据需要通过CronJob定时地去获取,并且业务对数据的即时性要求高,大量的和持久的HTTP请求是不可避免的,并且该项目部署了HTTP/2,带宽和并发数可以极大,并且页面上有很多的可视化仪表大盘,HTTP请求的返回数据中存在有大量的仪表盘统计信息,这些信息从服务端返回来后,并不能直接使用,需要修正为我们页面需要的格式,并做时间格式化等其他工作,这个工作是有一定耗时的。而且我们的项目不需要兼容IE系列,哈哈哈,针对这些点于是决定优(瞎)化(弄)。
笔者一开始想到的就是使用HTML5的新特性web worker,然后将HTTP的请求工作从主线程放到子线程里面去做,工作完成后,返回子线程数据即可。这样可以降低主线程中的负荷,使主线程可以坐享其成。一旦子线程中发起的请求成功或错误后,子线程返回给主线程请求的response对象或者直接返回请求得到的数据或错误信息。最终的方案里,选择的是直接返回请求得到的数据,而不是response对象,这个在后面会详细说明为什么这样做。子线程对于处于复杂运算,特别是搭配wasm,对于处理WebGL帧等有极大的性能优势。以往的纯JS视频解码,笔者只看到过能够解码MPEG1(大概240P画面)的canvas库,因为要达到60帧的画面流畅度,就必须保证1帧的计算时间要小于16ms,如果要解码1080P的画面甚至4K,JS可能跑不过来了,而且长时间的计算会严重阻塞主线程,影响页面性能,如果能开启子线程把计算任务交给子线程做,并通过wasm加快计算速度,这将在前端领域创造极大的可能性。
二、为什么要设计线程池
如果只开一个线程,工作都在这一个子线程里做,不能保证它不阻塞。如果无止尽的开启而不进行控制,可能导致运行管理平台应用时,浏览器的内存消耗极高:一个web worker子线程的开销大概在5MB左右。
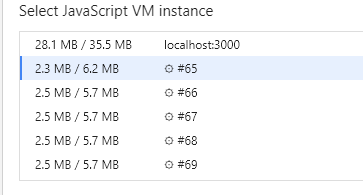
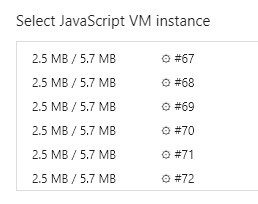
无论这5MB内存是否已被这个子线程完全使用,还是说仅仅是给这个子线程预规划的内存空间,但这个空间确实是被占用了。并且频繁地创建和终止线程,对性能的消耗也是极大的。所以我们需要通过线程池来根据浏览器所在计算机的硬件资源对子线程的工作进行规划和调度,以及对僵尸线程的清理、新线程的开辟等等。根据测试,在页面关闭以后,主线程结束,子线程的内存占用会被一并释放,这点不需要做额外的处理。
三、设计线程池
对于线程池,我们需要实现的功能有如下这些:
1. 初始化线程
通过 Navagitor 对象的 HardWareConcurrecy 属性可以获取浏览器所属计算机的CPU核心数量,如果CPU有超线程技术,这个值就是实际核心数量的两倍。当然这个属性存在兼容性问题,如果取不到,则默认为4个。我们默认有多少个CPU线程数就开多少个子线程。线程池最大线程数量就这么确定了,简单而粗暴:
class FetchThreadPool {
constructor (option = {}){
const {
inspectIntervalTime = 10 * 1000,
maximumWorkTime = 30 * 1000
} = option;
this.maximumThreadsNumber = window.navigator.hardwareConcurrency || 4;
this.threads = [];
this.inspectIntervalTime = inspectIntervalTime;
this.maximumWorkTime = maximumWorkTime;
this.init();
}
......
}
获取到最大线程数量后,我们就可以根据这个数量来初始化所有的子线程了,并给它们额外加上一个我们需要的属性:
init (){
for (let i = 0; i < this.maximumThreadsNumber; i ++){
this.createThread(i);
}
setInterval(() => this.inspectThreads(), this.inspectIntervalTime);
}
createThread (i){
// Initialize a webWorker and get its reference.
const thread = work(require.resolve('./fetch.worker.js'));
// Bind message event.
thread.addEventListener('message', event => {
this.messageHandler(event, thread);
});
// Stick the id tag into thread.
thread['id'] = i;
// To flag the thread working status, busy or idle.
thread['busy'] = false;
// Record all fetch tasks of this thread, currently it is aimed to record reqPromise.
thread['taskMap'] = {};
// The id tag mentioned above is the same with the index of this thread in threads array.
this.threads[i] = thread;
}
其中:
id为数字类型,表示这个线程的唯一标识,
busy为布尔类型,表示这个线程当前是否处于工作繁忙状态,
taskMap为对象类型,存有这个线程当前的所有工作任务的key/value对,key为任务的ID taskId,value为这个任务的promise的resolve和reject回调对象。
由上图还可以看出,在初始化每个子线程时我们还给这个子线程在主线程里绑定了接收它消息的事件回调。在这个回调里面我们可以针对子线程返回的消息,在主线程里做对应的处理:
messageHandler (event, thread){
let {channel, threadCode, threadData, threadMsg} = event.data;
// Thread message ok.
if (threadCode === 0){
switch (channel){
case 'fetch':
let {taskId, code, data, msg} = threadData;
let reqPromise = thread.taskMap[taskId];
if (reqPromise){
// Handle the upper fetch promise call;
if (code === 0){
reqPromise.resolve(data);
} else {
reqPromise.reject({code, msg});
}
// Remove this fetch task from taskMap of this thread.
thread.taskMap[taskId] = null;
}
// Set the thread status to idle.
thread.busy = false;
this.redirectRouter();
break;
case 'inspection':
// console.info(`Inspection info from thread, details: ${JSON.stringify(threadData)}`);
// Give some tips about abnormal worker thread.
let {isWorking, workTimeElapse} = threadData;
if (isWorking && (workTimeElapse > this.maximumWorkTime)){
console.warn(`Fetch worker thread ID: ${thread.id} is hanging up, details: ${JSON.stringify(threadData)}, it will be terminated.`);
fetchThreadPool.terminateZombieThread(thread);
}
break;
default:
break;
}
} else {
// Thread message come with error.
if (threadData){
let {taskId} = threadData;
// Set the thread status to idle.
thread.busy = false;
let reqPromise = thread.taskMap[taskId];
if (reqPromise){
reqPromise.reject({code: threadCode, msg: threadMsg});
}
}
}
}
这里处理的逻辑其实挺简单的:
1). 首先规定了子线程和主线程之间通信的数据格式:
{
threadCode: 0,
threadData: {taskId, data, code, msg},
threadMsg: 'xxxxx',
channel: 'fetch',
}
其中:
threadCode: 表示这个消息是否正确,也就是子线程在post这次message的时候,是否是因为报错而发过来,因为我们在子线程中会有这个设计机制,用来区分任务完成后的正常的消息和执行过程中因报错而发送的消息。如果为正常消息,我们约定为0,错误消息为1,暂定只有1。
threadData: 表示消息真正的数据载体对象,如果threadCode为1,只返回taskId,以帮助主线程销毁找到调用上层promise的reject回调函数。Fecth取到的数据放在data内部。
threadMsg: 表示消息错误的报错信息。非必须的。
channel: 表示数据频道,因为我们可能通过子线程做其他工作,在我们这个设计里至少有2个工作,一个是发起fetch请求,另外一个是响应主线程的检查(inspection)请求。所以需要一个额外的频道字段来确认不同工作。
这个数据格式在第4步的子线程的设计中,也会有对应的体现。
2). 如果是子线程回复的检查消息,那么根据子线程返回的状态决定这个子线程是否已经挂起了,如果是就把它当做一个僵尸线程杀掉。并重新创建一个子线程,替换它原来的位置。
3). 在任务结束后,这个子线程的busy被设置成了false,表示它重新处于闲置状态。
4). 在给子线程派发任务的时候,我们post了taskId,在子线程的回复信息中,我们可以拿到这个taskId,并通过它找到对应的promise的resolve或者reject回调函数,就可以响应上层业务中Fetch调用,返回从服务端获取的数据了。
2、执行主线程中Fetch调用的工作
首先,我们在主线程中封装了统一调用Fetch的收口,页面所有请求均走这个唯一入口,对外暴露Get和Post方法,里面的业务有关的部分代码可以忽略:
const initRequest = (url, options) => {
if (checkRequestUnInterception(url)){
return new Promise(async (resolve, reject) => {
options.credentials = 'same-origin';
options.withCredentials = true;
options.headers = {'Content-Type': 'application/json; charset=utf-8'};
fetchThreadPool.dispatchThread({url, options}, {resolve, reject});
});
}
};
const initSearchUrl = (url, param) => (param ? url + '?' + stringify(param) : url);
export const fetchGet = (url, param) => (initRequest(initSearchUrl(url, param), {method: 'GET'}));
export const fetchPost = (url, param) => (initRequest(url, {method: 'POST', body: JSON.stringify(param)}));
在线程池中,我们实现了对应的方法来执行Fetch请求:
dispatchThread ({url, options}, reqPromise){
// Firstly get the idle thread in pools.
let thread = this.threads.filter(thread => !thread.busy)[0];
// If there is no idle thread, fetch in main thread.
if (!thread){
thread = fetchInMainThread({url, options});
}
// Stick the reqPromise into taskMap of thread.
let taskId = Date.now();
thread.taskMap[taskId] = reqPromise;
// Dispatch fetch work to thread.
thread.postMessage({
channel: 'fetch',
data: {url, options, taskId}
});
thread.busy = true;
}
这里调度的逻辑是:
1). 首先遍历当前所有的子线程,过滤出闲置中的子线程,取第一个来下发任务。
2). 如果没有闲置的子线程,就直接在主线程发起请求。后面可以优化的地方:可以在当前子线程中随机找一个,来下发任务。这也是为什么每个子线程不直接使用task属性,而给它一个taskMap,就是因为一个子线程可能同时拥有两个及以上的任务。
3、定时轮训检查线程与终结僵尸线程
inspectThreads (){
if (this.threads.length > 0){
this.threads.forEach(thread => {
// console.info(`Inspection thread ${thread.id} starts.`);
thread.postMessage({
channel: 'inspection',
data: {id: thread.id}
});
});
}
}
terminateZombieThread (thread){
let id = thread.id;
this.threads.splice(id, 1, null);
thread.terminate();
thread = null;
this.createThread(id);
}
从第1步的代码中我们可以得知初始化定时检查 inspectThreads 是在整个线程池init的时候执行的。对于检查僵尸线程和执行 terminateZombieThread 也是在第1步中的处理子线程信息的回调函数中进行的。
4. 子线程的设计
子线程的设计,相对于线程池来说就比较简单了:
export default self => {
let isWorking = false;
let startWorkingTime = 0;
let tasks = [];
self.addEventListener('message', async event => {
const {channel, data} = event.data;
switch (channel){
case 'fetch':
isWorking = true;
startWorkingTime = Date.now();
let {url, options, taskId} = data;
tasks.push({url, options, taskId});
try {
// Consider to web worker thread post data to main thread uses data cloning
// not change the reference. So, here we don't post the response object directly,
// because it is un-cloneable. If we persist to post id, we should use Transferable
// Objects, such as ArrayBuffer, ImageBitMap, etc. And this way is just like to
// change the reference(the control power) of the object in memory.
let response = await fetch(self.origin + url, options);
if (response.ok){
let {code, data, msg} = await response.json();
self.postMessage({
threadCode: 0,
channel: 'fetch',
threadData: {taskId, code, data, msg},
});
} else {
const {status, statusText} = response;
self.postMessage({
threadCode: 0,
channel: 'fetch',
threadData: {taskId, code: status, msg: statusText || `http error, code: ${status}`},
});
console.info(`%c HTTP error, code: ${status}`, 'color: #CC0033');
}
} catch (e){
self.postMessage({
threadCode: 1,
threadData: {taskId},
threadMsg: `Fetch Web Worker Error: ${e}`
});
}
isWorking = false;
startWorkingTime = 0;
tasks = tasks.filter(task => task.taskId !== taskId);
break;
case 'inspection':
// console.info(`Receive inspection thread ${data.id}.`);
self.postMessage({
threadCode: 0,
channel: 'inspection',
threadData: {
isWorking,
startWorkingTime,
workTimeElapse: isWorking ? (Date.now() - startWorkingTime) : 0,
tasks
},
});
break;
default:
self.postMessage({
threadCode: 1,
threadMsg: `Fetch Web Worker Error: unknown message channel: ${channel}}.`
});
break;
}
});
};
首先,在每个子线程声明了 taksk 用来保存收到的任务,是为后期一个子线程同时做多个任务做准备的,当前并不需要,子线程一旦收到请求任务,在请求完后之前, isWorking 状态一直都为 true 。所有子线程有任务以后,会直接在主线程发起请求,不会随机派发给某个子线程。
然后,我们在正常的Fecth成功后的数据通信中,post的是对response处理以后的结构化数据,而不是直接post这个response对象,这个在第一章节中有提到,这里详细说一下:
Fetch请求的response对象并非单纯的Object对象。在子线程和主线程之间使用postMessage等方法进行数据传递,数据传递的方式是克隆一个新的对象来传递,而非直接传递引用,但response对象作为一个非普通的特殊对象是不可以被克隆的......。要传递response对象只有就需要用到HTML5里的一些新特性比如 Transferable object 的 ArrayBuffer 、 ImageBitmap 等等,通过它们可以直接传递对象的引用,这样做的话就不需要克隆对象了,进而避免因对response对象进行克隆而报错,以及克隆含有大量数据的对象带来的高额开销。这里我们选择传递一个普通的结构化Object对象来现实基本的功能。
对于子线程中每次给主线程post的message,也是严格按照第1步中说明的那样定义的。
还有一点需要说明:笔者的项目都是基于webpack的模块化开发,要直接使用一个web worker的js文件,笔者选了"webworkify-webpack"这个库来处理模块化的,这个库还执行在子线程中随意import其他模块,使用比较方便:
import work from 'webworkify-webpack';
所以,在第1步中才出现了这样的创建子线程的方式: const thread = work(require.resolve('./fetch.worker.js'));
该库把web worker的js文件通过 createObjectURL 方法把js文件内容转成了二进制格式,这里请求的是一个二进制数据的链接(引用),将会到内存中去找到这个数据,所以这里并不是一个js文件的链接:

如果你的项目形态和笔者不同,大可不必如此,按照常规的web worker教程中的指导方式走就行。
笔者这个项目在主线程和子线程之间只传递了很少量的数据,速度非常快,一旦你的项目需要去传递大量数据,比如说一个异常复杂的大对象,如果直接传递结构化对象,速度会很慢,可以先字符串化了以后再发送,避免了在post的过程中时间消耗过大。
笔者捕捉到的一个postMessage的消耗,如果数据量小的话,还算正常:

5. 通过子线程发起请求
// ...
@catchError
async getNodeList (){
let data = await fetchGet('/api/getnodelist');
!!data && store.dispatch(nodeAction.setNodeList(data));
},
// ...
fetchGet最终会在子线程中执行。
数据回来了:



从截图中可以看出,和直接在主线程中发起的Fetch请求不同的是,在子线程中发起的请求,在Name列里会增加一个齿轮在开头以区分。
需要注意的一点是:如果子线程被终结,无法查看返回信息等,因为这些数据的占用内存已经随子线程的终结而被回收了。
我们在子线程中写一个明显的错误,也会回调reject,并在控制台报错:

从开发者工具里可以检测到这8个子线程:

大概的设计就是如此,目前这个线程池只针对Fetch的任务,后续还需要在业务中进行优化和增强,已适配更多的任务。针对其他的任务,在这里架子其实已基本实现,需要增加对不同channel的处理。
四、Web Worker的兼容性
从caniuse给出的数据来看,兼容性异常的好,甚至连IE系列都在好几年前就已经支持:
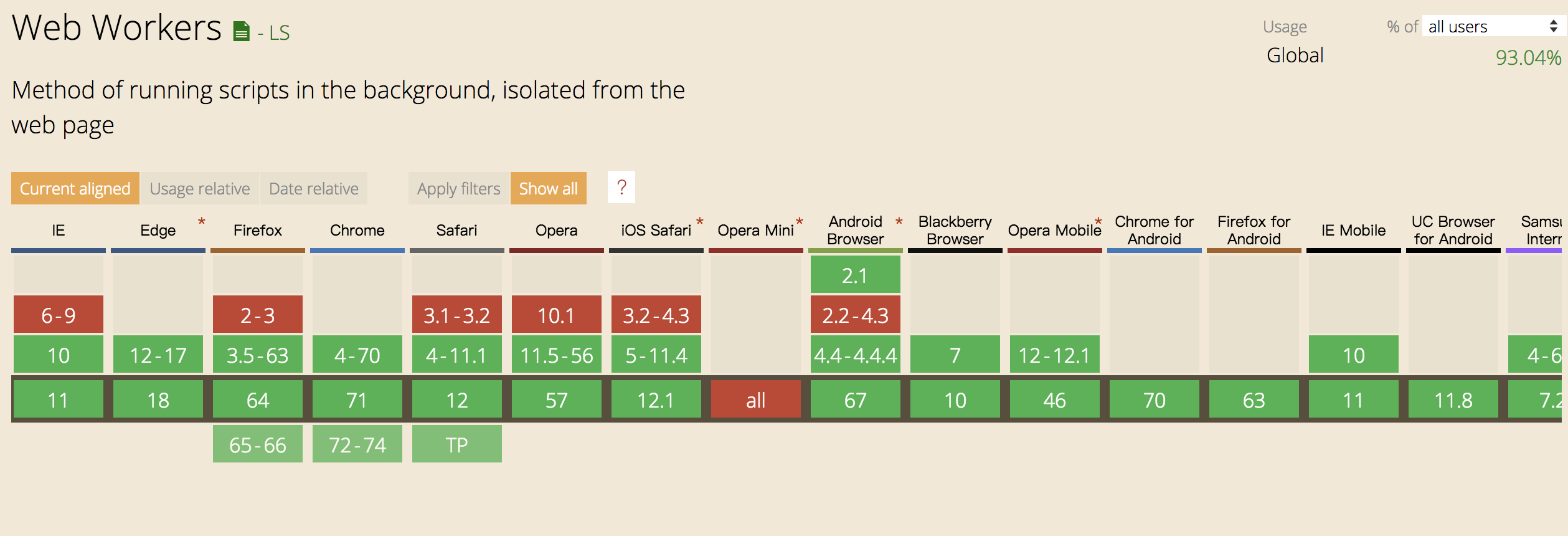
但是...,这个兼容性只能说明能否使用Web Woker,这里的兼容并不能表明能在其中做其他操作。比如标准规定,可以在子线程做做计算、发起XHR请求等,但不能操作DOM对象。笔者在项目中使用的Fetch,而非Ajax,然后Fecth在IE系列(包括Edge)浏览器中并不支持,会直接报错。在近新版本的Chrome、FireFox、Opera中均无任何问题。后来作者换成了Axios这种基于原生的XHR封装的库,在IE系列中还是要报错。后来又换成了纯原生的XmlHttpRequest,依旧报错。这就和标准有出入了......。同学们可以试试,不知到笔者的方法是否百分百正确。但欣慰的是前几天的新闻说微软未来在Edge浏览器开发中将使用Chromium内核。
至于Web Woker衍生出来的其他新特性,比如 Shared Web Woker等,或者在子线程中再开子线程,这些特性的使用在各个浏览器中并不统一,有些支持,有些不支持,或者部分支持,所以对于这些特性暂时就不要去考虑它们了。
五、展望
在前端开发这块(没用Web前端了,是笔者认为现在的前端开发已经不仅限于Web平台了,也不仅限于前端了),迄今为止活跃度是非常之高了。新技术、新标准、新协议、新框(轮)架(子)的出现是非常快速的。技术跌该更新频率极高,比如这个Web Worker,四年前就定稿了,笔者现在针对它写博客......。一个新技术的出现可能不能造成什么影响,但是多种新技术的出现和搭配使用将带来翻天覆地的变化。前端的发展越来越多地融入了曾经只在Client、Native端出现的技术。特别是近年来的WebGL、WebAssembly等新技术的推出,都是具有意义的。
一个简单的HTML5 Web Worker 多线程与线程池应用的更多相关文章
- 深入HTML5 Web Worker应用实践:多线程编程
HTML5 中工作线程(Web Worker)简介 至 2008 年 W3C 制定出第一个 HTML5 草案开始,HTML5 承载了越来越多崭新的特性和功能.它不但强化了 Web 系统或网页的表现性能 ...
- 深入 HTML5 Web Worker 应用实践:多线程编程
深入 HTML5 Web Worker 应用实践:多线程编程 HTML5 中工作线程(Web Worker)简介 至 2008 年 W3C 制定出第一个 HTML5 草案开始,HTML5 承载了越来越 ...
- html5 web worker学习笔记(记一)
(吐槽:浏览器js终于进入多线程时代!) 以前利用setTimeout.setInterval等方式的多线程,是伪多线程,本质上是一种在单线程中进行队列执行的方式.自从html5 web worker ...
- JavaScript多线程之HTML5 Web Worker
在博主的前些文章Promise的前世今生和妙用技巧和JavaScript单线程和浏览器事件循环简述中都曾提到了HTML5 Web Worker这一个概念.在JavaScript单线程和浏览器事件循环简 ...
- 一个简单的Java web服务器实现
前言 一个简单的Java web服务器实现,比较简单,基于java.net.Socket和java.net.ServerSocket实现: 程序执行步骤 创建一个ServerSocket对象: 调用S ...
- JBoss 系列七十:一个简单的 CDI Web 应用
概述 本文通过一个简单的 CDI Web 应用演示dependency injection, scope, qualifiers 以及EL整合.应用部署完成后我们可以通过http://localhos ...
- Golang学习-第二篇 搭建一个简单的Go Web服务器
序言 由于本人一直从事Web服务器端的程序开发,所以在学习Golang也想从Web这里开始学起,如果对Golang还不太清楚怎么搭建环境的朋友们可以参考我的上一篇文章 Golang的简单介绍及Wind ...
- SharePoint创建一个简单的Visio Web部件图
SharePoint创建一个简单的Visio Web部件图 Visio有很多强大的Mash-up混聚功能,使它能够轻松集成到SharePoint 2010中. 1. 打开Visio 2010,创建新的 ...
- 使用eclipse创建一个简单的Java Web应用程序
关于Java JDK/JRE.Tomcat的配置等等都没什么好说的,主要记录一下使用Eclipse创建web工程时的一些点以及说一说自己用IDEA的创建失败的过程(IDEA没运行成功...暂时不想弄了 ...
随机推荐
- Oracle的nvl
在Oracle中nvl(字段名,value)函数用于对没有值的字段做处理在MySql中ifnull(字段名,value)是一样的功能
- MySQL如何优化
对于全栈而言,数据库技能不可或缺,关系型数据库或者nosql,内存型数据库或者偏磁盘存储的数据库,对象存储的数据库或者图数据库--林林总总,但是第一必备技能还应该是MySQL.从LAMP的兴起,到Ma ...
- BZOJ_2882_工艺_后缀数组
BZOJ_2882_工艺_后缀数组 Description 小敏和小燕是一对好朋友. 他们正在玩一种神奇的游戏,叫Minecraft. 他们现在要做一个由方块构成的长条工艺品.但是方块现在是乱的,而且 ...
- 配置(迁移)Laravel的注意事项
1.如果Laravel是在Linux下运行,如果权限不足,会报错 2.如果是从git上clone下来的项目,需要安装composer,切到项目根目录下 composer install compose ...
- Spring mvc 上传进度条实现
以下的仅仅是学习而已,记录以下笔记 1 springmvc 进度条,要实现ProgressListener接口,实现方法update(long readLength, long contextLeng ...
- Python 实现文件复制、删除
Python 实现文件复制.删除 转载至:http://www.cnblogs.com/sld666666/archive/2011/01/05/1926282.html 用python实现了一个小 ...
- Error Code: 1044. Access denied for user 'root'@'%' to database
mysql> SELECT host,user,password,Grant_priv,Super_priv FROM mysql.user; +--------------+--------- ...
- MIP技术进展月报第3期:MIP小姐姐听说,你想改改MIP官网?
一. 官网文档全部开源 MIP 是一项永久的开源的项目,提供持续优化的解决方案,当然官网也不能例外.从现在开始,任何人都可以在 MIP 官网贡献文档啦! GitHub 上,我们已经上传了 <官网 ...
- 卷积神经网络之AlexNet
由于受到计算机性能的影响,虽然LeNet在图像分类中取得了较好的成绩,但是并没有引起很多的关注. 知道2012年,Alex等人提出的AlexNet网络在ImageNet大赛上以远超第二名的成绩夺冠,卷 ...
- java_stream流
Stream流的个人理解 整体来看,流式思想类似于工厂车间的“生产流水线”,通过一些列操作来获取我们需要的产品 在Java 8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream概念 ...