Storm一致性事物
Storm是一个分布式的流处理系统,利用anchor和ack机制保证所有的tuple都被处理成功。如果tuple出错,则可以被重传,但是如何保证出错的tuple只被处理一次呢?换句话说Storm如何保证事物性呢?本节从简单的事物实现入手,最后引出事物型Topology的原理。
一.一致性事物设计
1.简单设计一,强顺序流
保证tuple只被处理一次,最简单的方式是将tuple刘变成强顺序的,并且每次只处理一个tuple。从1开始,给给个tuple都加上一个顺序id。在处理tuple的时候,把处理成功的tupleID和计算结果都存储到数据库中。下一个tuple到来的时候,将他和数据库中的id做比较。如果相同说明tuple已经被成功处理,可以忽略,如果不同,根据强顺序性,说明这个tuple没有被处理过,将它的id和计算结果存储到数据库。这种当时的缺点就是每次智能处理一个tuple,没办法实现分布式。
2.简单设计二,强顺序batch流
为了实现分布式,我们可以一次处理一批tuple,称为一个batch。一个batch中的每个tuple可以被并行处理。
为了保证每个batch只被处理一次,实现方式和上面的一样,只不过数据库中存储的是batch id。batch的中间计算结果先存在局部变量中,当一个batch中所有的tuple都被处理完之后,判断batch id,如果和数据库中的结果不同,则将中间结果更新到数据库。
如何保证bath中的每个tuple都被处理完呢?可以利用Storm提供的CoordinatedBolt,如下图:
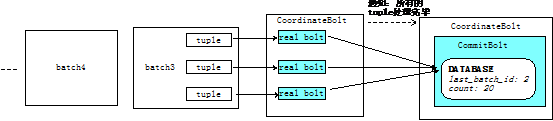
但是强顺序batch流也有局限,每次只能处理一个batch,batch之间无法并行。要想实现真正的分布式事务处理,可以使用storm提供的Transactional Topology。在此之前,我们先详细介绍一下CoordinateBolt的原理。
3.CoordinateBolt原理
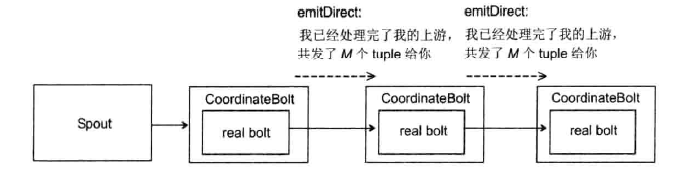
CoordinateBolt的具体原理如下:
a.真正执行计算的Bolt外面封装了一个CoordinateBolt。我们将真正执行任务的Bolt称为Real Bolt。
b.每个CoordinateBolt记录两个值,有哪些Task给我们发送了tuple,以及我们要给那些Task发送信息
c.Real Bolt发出一个tuple后,其外层的CoordinateBolt会记录下这些tuple发送给了那些Task
d.等所有的tuple都发送完之后,CoordinateBolt通过另外一个特殊的Stream以emitDirect的方式告诉所有它发送过tuple的Task,它发送了多少tuple给这些task。下游这些task会将这个数字和自己已经接收到的tuple数量对比。如果相等,则说明处理完了所有的tuple。
e.下游的task会重复上面的步骤,通知其下游
整个过程如下图所示:
CoordinateBolt主要用于一下场景。1:DRPC,2:Transactional Topology。
CoordinateBolt对于业务是有入侵的,要使用CoordinateBolt提供的功能,你必须包保证你的每个Bolt发送的每个tuple的第一个field是request-id,所谓我已经处理完我的上游的意思是说当前这个Bolt对于当前这个request-id所需要做的工作做完了。这个request-id在DRPC里面代表一个请求,在Transactional Topology里面代表一个batch。
4.Transactional Topology
Storm的Transactional Topology将batch的计算分为两个阶段:process阶段和commit阶段。process阶段可以同时处理多个batch,不用保证顺序性,commit阶段保证batch的强顺序性,并且在commit阶段每次只能处理一个batch。
下面以storm自带的例子TransactionalGlobalCount,来说明。
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH);
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, );
builder.setBolt("partial-count", new BatchCount(), ).noneGrouping("spout");
builder.setBolt("sum", new UpdateGlobalCount()).globalGrouping("partial-count");
LocalCluster cluster = new LocalCluster();
Config config = new Config();
config.setDebug(true);
config.setMaxSpoutPending();
cluster.submitTopology("global-count-topology", config, builder.buildTopology());
Thread.sleep();
cluster.shutdown();
TransactionalTopologyBuilder共接收了如下的四个参数:
1.这个Transactional Topology的id,用来在zookeeper中保存当前topology的进度,如果这个topology重启,可以接着之前的进度执行
2.Spout在这个Topology中的id
3.一个Transactional Spout。一个Transactional Topology只能有一个Transactional Spout,本例中使用的是MemoryTransactionalSpout,从内存变量DATA中读取数据。
4.Transactional Spout的并行度(可选)
下面是BatchCount的定义:
public static class BatchCount extends BaseBatchBolt {
Object _id;
BatchOutputCollector _collector;
int _count = ;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_count++;
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "count"));
}
}
BatchCount的prepare方法最后一个参数是batchid,在Transactional Topology里面这个id是一个TransactionAttempt对象,Transactional Topology里面发送的tuple,读必须以TransactionAttempt作为第一个field,Storm根据这个field爱判断tuple属于哪个batch。
TransactionAttempt里面包含两个值,一个是txid,两外一个是attemptid,txid就是上面我们介绍的对于每一个batch里的tuple是唯一的。attemptid是每个batch唯一的一个ID,但是对每一个batch,它reply之后的attemptid和reply之前的attemptid是不一样的,我们可以吧attemptid理解为reply-times,Storm利用这个ID来区别一个batch发射的tuple的版本。
execute方法会为batch中的每一个tuple执行一次,你应该把这个batch里面的计算状态保持在一个本地变量里面。对于这个例子来说,它在execute方法里面递增tuple的个数。
最后,当这个Bolt接收到每个batch的所有的tuple之后,finishBatch方法会被执行。
UpdateGlobalCount的定义如下:
public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter {
TransactionAttempt _attempt;
BatchOutputCollector _collector;
int _sum = ;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt attempt) {
_collector = collector;
_attempt = attempt;
}
@Override
public void execute(Tuple tuple) {
_sum += tuple.getInteger();
}
@Override
public void finishBatch() {
Value val = DATABASE.get(GLOBAL_COUNT_KEY);
Value newval;
if (val == null || !val.txid.equals(_attempt.getTransactionId())) {
newval = new Value();
newval.txid = _attempt.getTransactionId();
if (val == null) {
newval.count = _sum;
}
else {
newval.count = _sum + val.count;
}
DATABASE.put(GLOBAL_COUNT_KEY, newval);
}
else {
newval = val;
}
_collector.emit(new Values(_attempt, newval.count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "sum"));
}
}
UpdateGlobalCount实现了ICommitter接口,所以Storm会在commit阶段调用finishBatch方法,儿execute方法可以在任何阶段完成。
在UpdateGlobalCount的finishBatch方法中将当前的txid与数据库中的id作比较。如果相同,则忽略这个batch,如果不同则吧这个batch的计算结果合并到总的结果中,并更新数据库。
Transactional Topology的运行示意图如下:
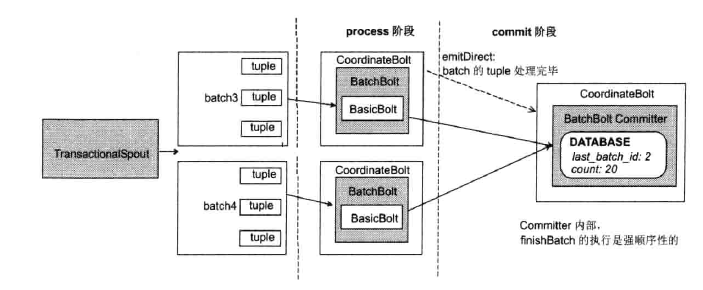
Transactional Topology的一些特性:
1.Transactional Topology将事物机制封装好,其内部使用CoordinateBOlt保证一个batch中的tuple被处理完
2.TransactionalSpout只有一个,它将所有的tuple分组为一个一个的batch,而且保证同一个batch的txid始终一样
3.BatchBolt处理一个batch中的每一个tuple,对每一个tuple调用execute方法,并在所有的tuple都处理完后调用finishBatch方法
4.如果batchBolt实现了ICommitter接口,则只能在commit阶段调用finishBatch。
Storm一致性事物的更多相关文章
- 集成Spring事物管理
什么是事物 事物是访问数据库的一个操作序列,数据库应用系统通过事物集来完成对数据库的存取.事物的正确执行使得数据库从一种状态转换为另一种状态. 事物必须服从ISO/IEC所制定的ACID原则.ACID ...
- Java事物基础总结
1.什么是事物? 事物是逻辑上的的一种操作,这个操作过程中的每一个元素要么全部成功,要么全部失败.例如,银行转账过程视为一个事物,转出过程和转入过程要求全部成功或全部失败,通过提交事物或者回滚事物实现 ...
- day42 事物,数据库锁
事物是把一些sql语句作为一个原子性操作,就是说我会写好几条sql语句,然后我想把这好几条的sql语句作为一个整体,然后让这个整体一起去运行,不可以拆分开,就像我们用面粉做一个馒头一样,我需要把这些面 ...
- day41 python【事物 】【数据库锁】
MySQL[五] [事物 ][数据库锁] 1.数据库事物 1. 什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性 ...
- MySQL 事物和数据库锁
1.数据库事物 1. 什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一 ...
- Python全栈 MySQL 数据库 (引擎、事物、pymysql模块、orm)
ParisGabriel 每天坚持手写 一天一篇 决定坚持几年 为了梦想为了信仰 开局一张图 存储引擎(处理表的处理器) 基本操作: ...
- python【事物 】【数据库锁】
1.数据库事物 1. 什么是事务 事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消.也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一 ...
- spring5 源码深度解析----- @Transactional注解的声明式事物介绍(100%理解事务)
面的几个章节已经分析了spring基于@AspectJ的源码,那么接下来我们分析一下Aop的另一个重要功能,事物管理. 事务的介绍 1.数据库事物特性 原子性多个数据库操作是不可分割的,只有所有的操作 ...
- Sql Server数据库设计高级查询
-------------------------------------第一章 数据库的设计------------------------------------- 软件开发周期: (1 ...
随机推荐
- UI小白如何快速提升自己
作为一名经历过UI学习的过来人,这些观点是自己在整个学习的过程中总结的. 希望可以对大家有所帮助,可以让刚开始接触UI的人少走弯路吧,话不多说. 快速进入主题. 那么UI小白到底如何快速提成自己呢 ...
- sci-hub 下载地址更新
# 2017-12-14 可用 http://www.sci-hub.tw/ 文献共享平台
- Python中的编码和解码问题
关于Python中遇到的中文字符串的读取和输入时总是遇到一堆问题,到现在还不是特别明白,只是有了一个大概率的理解,就是:字符串是用什么编码格式编码的,就用什么编码格式来解码. encode()对字符串 ...
- springcloud-eureka简单实现
请参考 spring+cloud为服务实战 第三章 一.创建Eureka服务 1.使用Idea创建一个项目 结构如下: 2.pom.xml配置: <?xml version="1.0& ...
- java 解析txt/html文件
package util.read; import java.io.BufferedReader;import java.io.FileReader; public class ReadFromFil ...
- 状态机中的RAM注意的问题--减少扇出的办法
可能我不会抓紧时间,所以做事老是很慢.最近在整维特比译码过程深感自己有这样的毛病. 每天会有一点进展,但是却是一天的时间,感觉别人都做起事情来很快.可能这个东西有点难,做 不做得出来都不要紧,但我的想 ...
- 用Execute操作数据库
1.原型是:_ConnectionPtr Execute( _bstr_t CommandText, VARIANT * RecordsAffected, long Options ); 参数 1. ...
- git 删除追踪状态
当不小心添加一个不想被git记录等文件时,这个时候就算将该文件记录在了.gitignore里也是没有用的,因为那个文件已经被git记录过了,只有那些从来没有被git记录过的文件(即:自添加进项目后,从 ...
- windows7,windows8 64位系统 IIS7.0配置.net网站时报错:未能加载文件或程序集“XXX”或它的某一个依赖项。试图加载格式不正确的程序。
背景: 在64位的操作系统中, IIS7.0配置.net网站时报错:未能加载文件或程序集“XXX”或它的某一个依赖项.试图加载格式不正确的程序. 解决办法: 把iis 对应的应用程序池 --高级设置- ...
- 【WinRT】让控件飞,WinRT 中实现 web 中的 dragable 效果
由于在 xaml 体系中,控件没有传统 WebForm 中的 Left.Top.Right.Bottom 这些属性,取而代之的是按比例(像 Grid)等等的响应布局.但是,传统的这些设置 Left.T ...