自然语言处理--Word2vec(二)
前一篇,word2vec(一)主要讲了word2vec一些表层概念,以及主要介绍CBOW方法来求解词向量模型,这里主要讲论文 Distributed Representations of Words and Phrases and their Compositionality中的skip-gram model方法,这可以被视作为一种概率式方法。
前面有一篇讲过自然语言处理的词频处理方法即TF-IDF,这种方法往往只是可以找出一篇文章中比较关键的词语,即找出一些主题词汇。但无法给出词汇的语义,比如同义词漂亮和美丽意思差不多应该相近,巴黎之于法国等同于北京之于中国。对于一句话,如何根据上下文推断出中间的词语是什么,或者由某一个词推测出它的上下文一般是什么词语。这两种不同的思考方式正好对应两种Word2vec模型,即CBOW模型和Skip-gram模型。
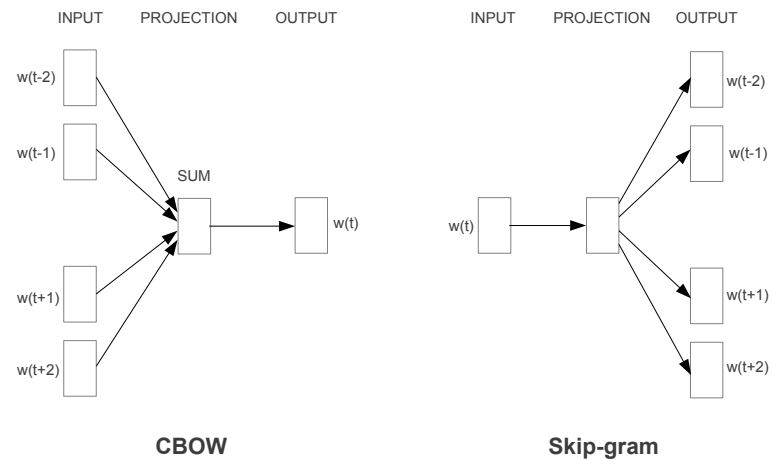
词向量即将字词从文字空间映射到向量空间,每一个字词都会有一个对应的代表其语义的向量。我们可以用传统的N-gram方法来得到向量,即统计方法,如
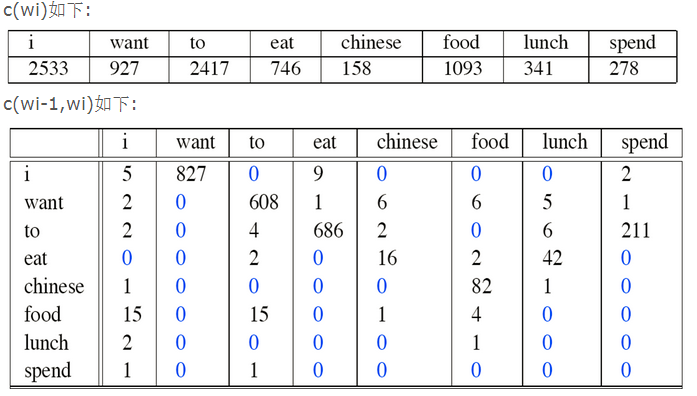
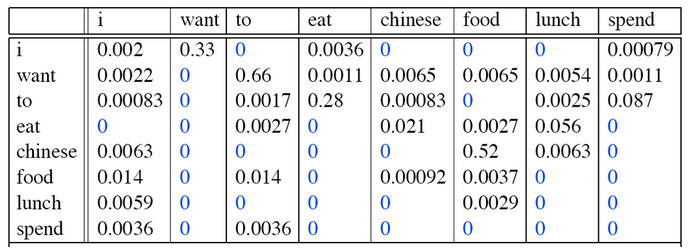
对于每一个单词,都可以根据词频来得出一个对应的向量,也是根据上下文得出,有一定的语义,但是这种方式的弊端是随着语料库中词语越多,模型参数越大,假设有N个词语,则得到的模型参数为N^2,如果N很大,则非常浪费内存,而且很多词语之间本身是不相关的,即很多位置都是0,如上图中所示。
接下来我们来看看Skip-gram方法。Skip-gram方法是一种深度学习方法,模型有输入层,中间层隐藏层和输出层神经网络组成。训练时,设定固定大小的窗口从头至尾滑动,由窗口中间单词可以预测出窗口两边的单词,通过不断的训练,可以得出模型的权重参数。对于一条语句,假设我们使用的滑动窗口为5(其他参数可以自己设定,如3、7、9等等),如下图所示。
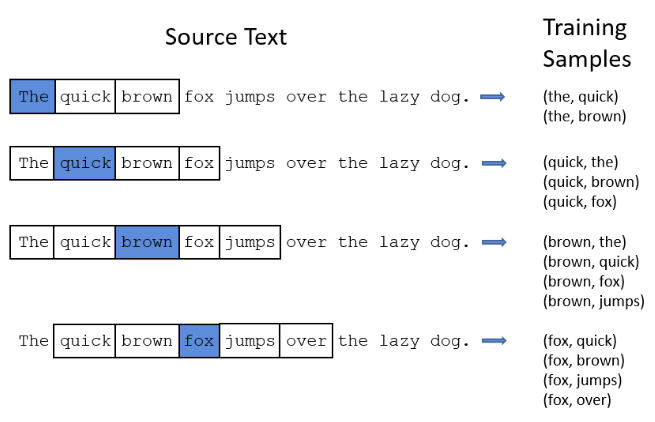
窗口滑动时由中间单词预测上下两个单词出现的概率。对于第一个windows位置,the后只有quick和brown有出现的可能,Skip-gram中每一个输入单词都用one-hot encoding表示,如下图,上图窗口在
第一个位置,input为[1,0,0,0,0,0,0,0,0], output为[0,1,1,0,0,0,0,0,0];
第二个位置,input为[0,1,0,0,0,0,0,0,0], output为[1,0,1,1,0,0,0,0,0];
......
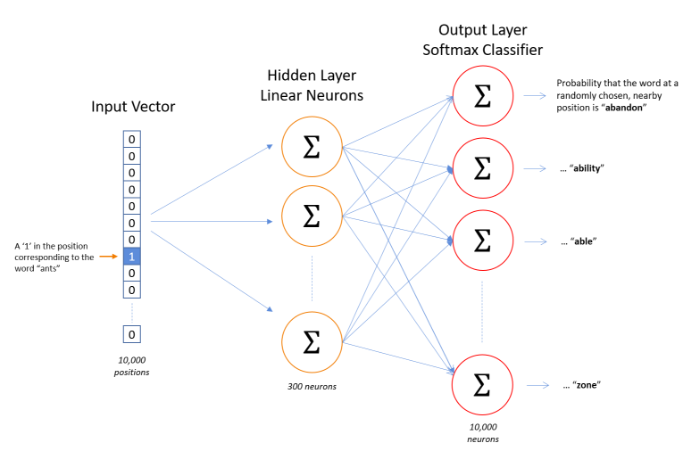
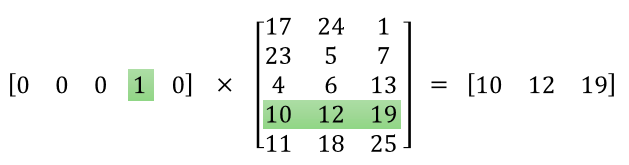
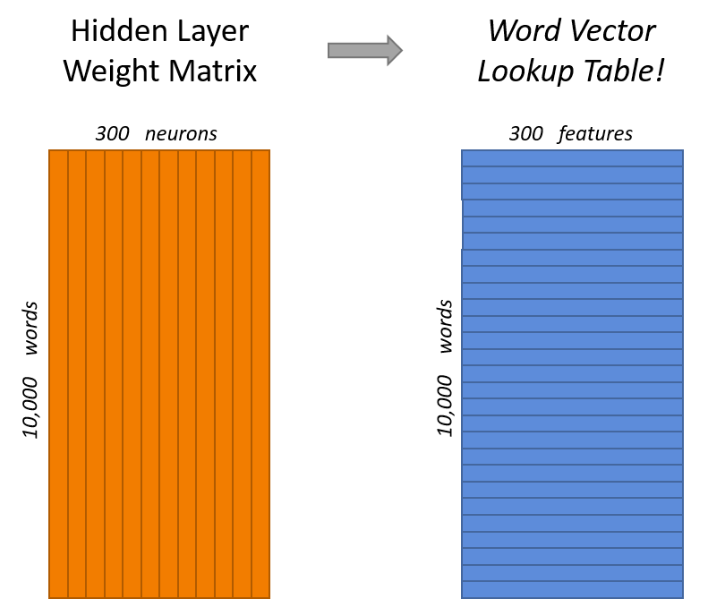
模型训练完后,在input层和Hidden layer之间可以等到一个权重矩阵W,对于上图中,input为10000维,hidden layer有300个神经元,则W为10000*300,由于对于每一个输入,都只有一个维度为1,而每一个1对应着一个单词,所以每个输入与权重矩阵W相乘后,只有一组向量输入到隐藏层,我们认为这就是该输入单词对应的Wordvector,所以第一个隐藏层权重矩阵W才是我们最终所要求的词向量映射表。
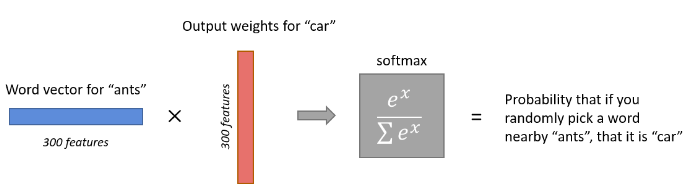
我们知道增加的样本数可以提高输出的准确率,可是如果样本数非常大,那么训练中经softmax,cross-entropy得到loss function,再BP回W,计算量将变得非常大。可见词汇量越大,update将变得越来越困难,越来越慢,那我们该怎样来进行优化呢。
1、Subsampling of Frequent Words
In very large corpora, the most frequent words can easily occur hundreds of millions of times (e.g.,“in”, “the”, and “a”). Such words usually provide less information value than the rare words. For example, while the Skip-gram model benefits from observing the co-occurrences of “France” and “Paris”, it benefits much less from observing the frequent co-occurrences of “France” and “the”, as nearly every word co-occurs frequently within a sentence with “the”. This idea can also be applied in the opposite direction; the vector representations of frequent words do not change significantly after training on several million examples。
这是论文中的说法,大致意思就是减少那些高频词的训练,比如 “in”, “the”, and “a”,这有点TF-IDF的味道,有些词出现的概率越高,保留的概率就越低。
单词保留的概率
P(wi) = [sqrt(Z(wi)/0.01) + 1] * (0.01/Z(wi)), 其中Z(wi)为单词Wi在全数据中出现的概率,0.01为给定参数。
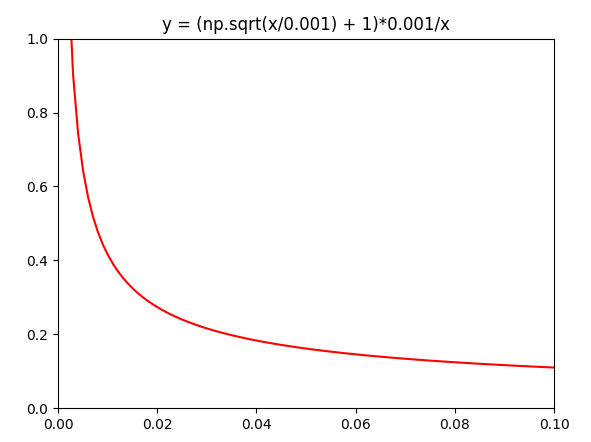
从图中可以看出,单词频率越高被保留的概率越小,在全数据中出现的概率越低,被保留的可能性越大。
2、Negative Sampling
在训练神经网络时,每当接受一个训练样本,然后调整所有神经单元权重参数,来使神经网络预测更加准确。换句话说,每个训练样本都将会调整所有神经网络中的参数。我们词汇表的大小决定了我们skip-gram 神经网络将会有一个非常大的权重参数,并且所有的权重参数会随着数十亿训练样本不断调整。negative sampling 每次让一个训练样本仅仅更新一小部分的权重参数,从而降低梯度下降过程中的计算量。如果 vocabulary 大小为1万时, 当输入样本 ( "fox", "quick") 到神经网络时, “ fox” 经过 one-hot 编码,在输出层我们期望对应 “quick” 单词的那个神经元结点输出 1,其余 9999 个都应该输出 0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们为 negative word. negative sampling 的想法也很直接 ,将随机选择一小部分的 negative words,比如选 10个 negative words 来更新对应的权重参数。在论文中作者指出指出对于小规模数据集,建议选择 5-20 个 negative words,对于大规模数据集选择 2-5个 negative words.如果使用了 negative sampling 仅仅去更新positive word- “quick” 和选择的其他 10 个negative words 的结点对应的权重,共计 11 个输出神经元,相当于每次只更新 300 x 11 = 3300 个权重参数。对于 3百万 的权重来说,相当于只计算了千分之一的权重,这样计算效率就大幅度提高。
使用 一元模型分布 (unigram distribution) 来选择 negative words,一个单词被选作 negative sample 的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words,经验公式为:
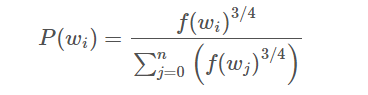
f(w) 代表 每个单词被赋予的一个权重,即 它单词出现的词频,分母 代表所有单词的权重和。公式中3/4完全是基于经验的,论文中提到这个公式的效果要比其它公式更加出色。
3、Hierarchical Softmax
这个方法没研究,有兴趣的可以自己去看论文。
参考论文:
Distributed Representations of Words and Phrases and their Compositionality
Efficient Estimation of Word Representations in Vector Space
参考博客:
Word2Vec Tutorial - The Skip-Gram Model
自然语言处理--Word2vec(二)的更多相关文章
- 自然语言处理--Word2vec(一)
一.自然语言处理与深度学习 自然语言处理应用 深度学习模型 为什么需要用深度学习来处理呢 二.语言模型 1.语言模型实例: 机器翻译 拼写纠错 ...
- python+NLTK 自然语言学习处理二:文本
在前面讲nltk安装的时候,我们下载了很多的文本.总共有9个文本.那么如何找到这些文本呢: text1: Moby Dick by Herman Melville 1851 text2: Sense ...
- python 自然语言处理(二)____获得文本语料和词汇资源
一, 获取文本语料库 一个文本语料库是一大段文本.它通常包含多个单独的文本,但为了处理方便,我们把他们头尾连接起来当做一个文本对待. 1. 古腾堡语料库 nltk包含古腾堡项目(Project Gut ...
- 自然语言处理(二)——PTB数据集的预处理
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中. #!/usr/bin/en ...
- word2vec 入门基础(一)
一.基本概念 word2vec是Google在2013年开源的一个工具,核心思想是将词表征映 射为对应的实数向量. 目前采用的模型有一下两种 CBOW(Continuous Bag-Of-Words, ...
- word2vec中关于霍夫曼树的
再谈word2vec 标签: word2vec自然语言处理NLP深度学习语言模型 2014-05-28 17:17 16937人阅读 评论(7) 收藏 举报 分类: Felven在职场(86) ...
- Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树
Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 目录 Alink漫谈(十六) :Word2Vec源码分析 之 建立霍夫曼树 0x00 摘要 0x01 背景概念 1.1 词向量基础 ...
- word2vec:主要概念和流程
1.单词的向量化表示 一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量. 所谓稀疏向量,又称为one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的 ...
- NLP学习(4)----word2vec模型
一. 原理 哈弗曼树推导: https://www.cnblogs.com/peghoty/p/3857839.html 负采样推导: http://www.hankcs.com/nlp/word2v ...
随机推荐
- VMware Workstation 12 OpenGL ES版本支持情况与设置
概述 开始学习Opengl时,发现VMware Workstation虚拟机无法运行Opengl ES2.0的程序.后来,经过查找最终得知,是因为VMware Workstation11及之前的版本对 ...
- linux下怎样用c语言调用shell命令
C程序调用shell脚本共同拥有三种法子 :system().popen().exec系列数call_exec1.c , system() 不用你自己去产生进程.它已经封装了,直接增加自己的命令 ex ...
- Example11(June 9,2015)
%--------------sort------------------------------- >> A=[ ; ; ] A = >> B=sort(A,)%A(:,)& ...
- eclipse/myeclipse介绍
eclipse更加纯净,比较简洁,需要某些插件的时候,需要自己去配置才可以,而myeclipse自带了很多的插件功能更为强大. 在eclipse于myeclipse创建的项目是有差异的,eclipse ...
- ArcGIS下图层范围不正确的两种处理方式
ArcGIS下图层范围不正确,偶尔能碰上这种情况,主要表现为“缩放至图层”时,其显示范围与该图层内所有要素的外包围盒范围不一致.针对这个问题,有两种解决办法. 方法一:导出数据.新创建含有要素的Sha ...
- Email feedback to product team about TFS and SharePoint Integration 2017.2.15
SharePoint与Team Foundation Server的集成,一直是许多研发团队所关注的问题. 通过这种集成,开发团队可以实现下面的几个功能: 1. 搭建一个与团队项目集成的门户网站,并 ...
- C# 委托和事件,简单示例说明问题
先看看示例效果 按照国际惯例,得先说说概念. 委托(C# 编程指南) 事件(C# 编程指南) 以上内容来自MSDN. 委托源码 [委托] 概念和代码都有了.剩下的就是应用了,要是只知道概念不会用,那还 ...
- 基于EasyUi的datagrid合并单元格JS写法
$('#dg').datagrid({ width: 'auto', height: 'auto', scrollbarSize: , queryParams: {}, url: 'kkkk', co ...
- FFMPEG的函数翻译文档
https://blog.csdn.net/explorer_day/article/category/6289310/2 https://www.cnblogs.com/tocy/p/ffmpeg- ...
- Android 美学设计基础 <3>
本期接着对Android的美学设计的分享. 1.3 Light and shadows 光学与阴影 1.3.1 Light 在素材设计的环境中,我们会用虚拟的光来照亮UI界面.主灯光会产生尖锐,有方向 ...