在hive中遇到的错误
1:如果在将文件导入到hive表时,查询结果为null(下图)
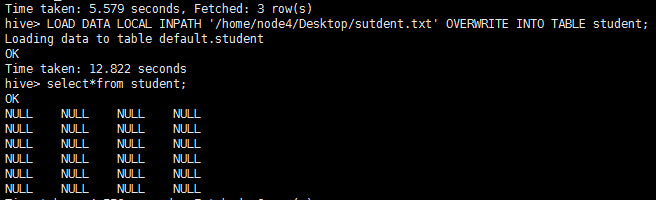


hive> LOAD DATA LOCAL INPATH '/home/node4/Desktop/sutdent.txt' OVERWRITE INTO TABLE student_3;
FAILED: SemanticException Unable to load data to destination table. Error: The file that you are trying to load does not match the file format of the destination table.
FAILED: SemanticException Line 1:17 Invalid path ''hdfs://Master:9000/user/test/qar_test'': No files matching path hdfs://Master:9000/user/test/qar_test
查询hive下的DBS表DB_LOCATION_URI列:select DB_LOCATION_URI from DBS; +----------------------------------------+
| DB_LOCATION_URI |
+----------------------------------------+
| hdfs://10.1.51.200:9000/hive/warehouse |
+----------------------------------------+
Caused by: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): Unauthorized connection for super-user: root from IP 192.168.177.124
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
在hive中遇到的错误的更多相关文章
- 使用sqoop1.4.4从oracle导入数据到hive中错误记录及解决方案
在使用命令导数据过程中,出现如下错误 sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.29.16:1521/testdb ...
- Hive中导入Oracle数据错误:Listener refused the connection with the following error: ORA-12505
问题: 今天往Hive中导入Oracle数据的时候碰到了如下错误:Listener refused the connection with the following error: ORA-12505 ...
- SparkSQL读取Hive中的数据
由于我Spark采用的是Cloudera公司的CDH,并且安装的时候是在线自动安装和部署的集群.最近在学习SparkSQL,看到SparkSQL on HIVE.下面主要是介绍一下如何通过SparkS ...
- 使用Sqoop,最终导入到hive中的数据和原数据库中数据不一致解决办法
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL , ...
- hive 中 union all
hive 中的union all是不能在sql语句的第一层使用的,否则会报 Top level UNION is not supported currently 错误: 例如如下的方式: select ...
- hive中简单介绍分区表
所介绍内容基本上是翻译官方文档,比较肤浅,如有错误,请指正! hive中创建分区表没有什么复杂的分区类型(范围分区.列表分区.hash分区.混合分区等).分区列也不是表中的一个实际的字段,而是一个或者 ...
- kettle连接Hive中数据导入导出(6)
1.hive往外写数据 http://wiki.pentaho.com/display/BAD/Extracting+Data+from+Hive+to+Load+an+RDBMS 连接hive
- Hive中知识点
hive的最新学习资料:http://www.cnblogs.com/qingyunzong/p/8707885.html hive的参数设置大全:https://cwiki.apache.org/c ...
- Hive中数据的导入与导出
最近在做一个小任务,将一个CDH平台中Hive的部分数据同步到另一个平台中.毕竟我也刚开始工作,在正式开始做之前,首先进行了一段时间的练习,下面的内容就是练习时写的文档中的内容.如果哪里有错误或者疏漏 ...
随机推荐
- easyui 汇总
1. easyui datagrid 表格组件列属性 formatter columns:{ { field:' product', title:'商品', align:'center', width ...
- linux red hat 给普通用户开启root权限
环境:虚拟机:red hat 6.5:root角色用户:普通用户:宏基笔记本:win7: 操作过程: 1.登录普通用户,进入图形界面(可以设置为启动登录进入命令行界面): 2.按Crl+ALT+F2进 ...
- oracle 修改密码
[oracle@t-ecif03-v-szzb ~]$ sqlplus / as sysdba SQL*Plus: Release 11.2.0.3.0 Production on Mon Nov 1 ...
- IE浏览器不能访问网页,google可以访问
现象:google浏览器可以进行网络访问,ie不能访问 原因:代理服务修改了局域网配置脚本 解决: Internet选项---连接---局域网设置: 去除勾选 “使用自动配置脚本”
- pthread_cond_signal惊群现象
1.如下代码所示: #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include < ...
- centos6 install mcrypt
Download the latest epel-release rpm from http://dl.fedoraproject.org/pub/epel/6/x86_64/ Install epe ...
- 10月28日下午MySQL数据库的增加、删除、查询(匹配数据库登录和可以增、删、查的显示数据库内容的页面))
一.匹配数据库登录 步骤: 1.做一个普通的登录界面,注意提交方式为post. <!--登录界面--> <form action="chuli.php" meth ...
- mate标签
<meta charset='utf-8'> <!-- 优先使用 IE 最新版本和 Chrome --> <meta http-equiv="X-UA-C ...
- ubuntu一些基本软件安装方法
ubuntu一些基本软件安装方法 首先说明一下 ubuntu 的软件安装大概有几种方式:1. deb 包的安装方式deb 是 debian 系 Linux 的包管理方式, ubuntu 是属于 deb ...
- mysql配置远程连接方法之一(改表法)
1.问题:如果在远程连接报错:1130-host ... is not allowed to connect to this MySql server,可能是你的帐号不允许从远程登陆,只能在local ...