MR案例:Reduce-Join
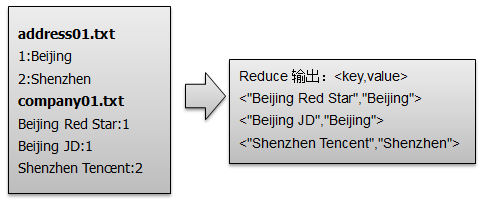
问题描述:两种类型输入文件:address(地址)和company(公司)进行一对多的关联查询,得到地址名(例如:Beijing)与公司名(例如:Beijing JD、Beijing Red Star)的关联信息。可参考MR案例:Map-Join
1.map阶段:对比之前的单表关联可知,reduce阶段的key必须为关联两表的key,即address.Id = company.Id。则两表经过map处理输出的key必须是Id。
Class Map<LongWritable, Text, LongWritable, Text>{
method map(){
// 获取文件的每一行数据,并以":"分割
String[] line = value.toString().split(":");
//split对应的文件名
String fileName = ((FileSplit) context.getInputSplit()).getPath().getName();
//处理company文件的value信息:"Beijing Red Star:1"
if (path.indexOf("company") >= 0){
//<key,value> --<"1","company:Beijing Red Star">
context.write(new LongWritable(line[1]), new Text("company" + ":" + line[0]));
}
//处理adress文件的value信息:"1:Beijing"
else if (path.indexOf("address") >= 0){
//<key,value> --<"1","address:Beijing">
context.write(new LongWritable(line[0]), new Text("address" + ":" + line[1]));
}
}
}
2.reduce阶段:首先对输入<key, values>即<”1”,[“company:Beijing Red Star”,”company:Beijing JD”,”address:Beijing”]>的values值进行遍历获取到单元信息value(例如”company:Beijing Red Star”),然后根据value中的标识符(company和address)将公司名和地址名分别存入到company集合和address集合,最后对company集合和address集合进行笛卡尔积运算得到company与address的关系,并进行输出。
Class Reducer<LongWritable, Text, Text, Text>{
method reduce(){
//用来存储 company 和 address 的集合
List<String> companys = new ArrayList<String>();
List<String> addresses = new ArrayList<String>();
for(Text text : v2s){
String[] result = text.toString().split(":");
//以 company 开头的value存储到 company 集合中
if(result[0].equals("company")){
companys.add(result[1]);
}
//以 address 开头的value存储到 address 集合中
else if(result[0].equals("address")){
addresses.add(result[1]);
}
}
/**
* 如果只判断左表addresses.size()!=0;则转化为 左外连接 --> LEFT OUTER JOIN
* 如果只判断右表companys.size()!=0;则转化为 右外连接 --> RIGHT OUTER JOIN
* 左右都不判断,则转化为 全外连接 --> FULL OUTER JOIN
*/
// 求笛卡尔积
if(0 != companys.size()&& 0 != addresses.size()){
for(int i=0;i<companys.size();i++){
for(int j=0;j<addresses.size();j++){
//<key,value>--<"Beijing JD","Beijing">
context.write(new Text(companys.get(i)), new Text(addresses.get(j)));
}
}
}
}
}
MR案例:Reduce-Join的更多相关文章
- Hadoop学习之路(二十一)MapReduce实现Reduce Join(多个文件联合查询)
MapReduce Join 对两份数据data1和data2进行关键词连接是一个很通用的问题,如果数据量比较小,可以在内存中完成连接. 如果数据量比较大,在内存进行连接操会发生OOM.mapredu ...
- MR案例:倒排索引
1.map阶段:将单词和URI组成Key值(如“MapReduce :1.txt”),将词频作为value. 利用MR框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过 ...
- MapReduce编程之Reduce Join多种应用场景与使用
在关系型数据库中 Join 是非常常见的操作,各种优化手段已经到了极致.在海量数据的环境下,不可避免的也会碰到这种类型的需求, 例如在数据分析时需要连接从不同的数据源中获取到数据.不同于传统的单机模式 ...
- MR案例:小文件处理方案
HDFS被设计来存储大文件,而有时候会有大量的小文件生成,造成NameNode资源的浪费,同时也影响MapReduce的处理效率.有哪些方案可以合并这些小文件,或者提高处理小文件的效率呢? 1). 所 ...
- MapReduce之Reduce Join
一 介绍 Reduce Join其主要思想如下: 在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag), 比如:t ...
- MR案例:CombineFileInputFormat
CombineFileInputFormat是一个抽象类.Hadoop提供了两个实现类CombineTextInputFormat和CombineSequenceFileInputFormat. 此案 ...
- MR案例:倒排索引 && MultipleInputs
本案例采用 MultipleInputs类 实现多路径输入的倒排索引.解读:MR多路径输入 package test0820; import java.io.IOException; import j ...
- MR案例:输出/输入SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File).在SequenceFile文件中,每一个key-value对被看做是一条记 ...
- MR案例:外连接代码实现
[外连接]是在[内连接]的基础上稍微修改即可.具体HQL语句详见Hive查询Join package join.map; import java.io.IOException; import java ...
随机推荐
- Android Handler 的使用
Android UI 操作是线程不安全的.我们只能在UI线程或者说主线程中修改UI.试想多个Thread操作同一个UI,可能引起不一致.UI 线程的主要工作是:UI界面更新显示,各个控件的交互等等.一 ...
- 服务端使用Zookeeper注册服务地址,客户端从Zookeeper获取可用的服务地址。
一个轻量级分布式RPC框架--NettyRpc - 阿凡卢 - 博客园 http://www.cnblogs.com/luxiaoxun/p/5272384.html 这个RPC框架使用的一些技术所解 ...
- Enables DNS lookups on client IP addresses
w虚拟域名访问,路由可以到达,但无输出. http://httpd.apache.org/docs/2.2/mod/core.html#hostnamelookups
- windbg遍历进程页表查看内存
2016-12-09 近期想查看下系统分配了的页的页表项的标志位,但是发现资料较少,所以还是记录下,希望可以对某些朋友有所帮助! 系统:win7 32位虚拟机 平台:KVM虚拟化平台 win7 32位 ...
- 【我的Android进阶之旅】推荐一款视频转换GIF图片格式的转换工具(Video to GIF)
一.背景 最近想把一些Android Demo的运行效果图获取下来,但是一直使用真机进行调试,在电脑上不好截取一段gif动画.而之前使用模拟器的时候可以使用 GifCam 工具进行屏幕动画截取.Gif ...
- Shiro-Base64加密解密,Md5加密
Shiro权限框架中自带的加密方式有Base64加密,MD5加密 在Maven项目的pom.xml中添加shiro的依赖: <dependency> <groupId>org. ...
- Hadoop 入门教程
Hadoop 入门教程 https://blog.csdn.net/kkkloveyou/article/details/52348883
- GC的性能指标和内存容量配置原则
一.GC性能指标吞吐量:应用花在非GC上的时间百分比GC负荷:与吞吐量相反,指应用花在GC上的时间百分比暂停时间:应用花在GC stop-the-world的时间GC频率反应速度:从一个对象变成垃圾到 ...
- django 登陆增加除了用户名之外的手机和邮箱登陆
在setting内增加 # Application definition AUTHENTICATION_BACKENDS = ( 'users.views.CustomBackend', ) 在vie ...
- 设置npm淘宝代理
来源:https://cnodejs.org/topic/4f9904f9407edba21468f31e 镜像使用方法(三种办法任意一种都能解决问题,建议使用第三种,将配置写死,下次用的时候配置还在 ...