Linux中安装配置hadoop集群
一. 简介
参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功。下面就把详细的安装步骤叙述一下。我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本。(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明)
二. 准备工作
2.1 创建用户
创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好。
sudo adduser hadoop
sudo vim /etc/sudoers
# 修改内容如下:
root ALL = (ALL)ALL
hadoop ALL = (ALL)ALL
给hadoop用户创建目录,并添加到sudo用户组中,命令如下:
sudo chown hadoop /home/hadoop
# 添加到sudo用户组
sudo adduser hadoop sudo
最后注销当前用户,使用新创建的hadoop用户登陆。
2.2 安装ssh服务
ubuntu中默认是没有装ssh server的(只有ssh client),所以先运行以下命令安装openssh-server。安装过程轻松加愉快~
sudo apt-get install ssh openssh-server
2.3 配置ssh无密码登陆
直接上代码:执行完下边的代码就可以直接登陆了(可以运行ssh localhost进行验证)
cd ~/.ssh # 如果找不到这个文件夹,先执行一下 "ssh localhost"
ssh-keygen -t rsa
cp id_rsa.pub authorized_keys
注意:
这里实现的是无密登陆自己,只适用与hadoop单机环境。如果配置Hadoop集群设置Master与Slave的SSH无密登陆可以参考我的另一篇博文:http://www.cnblogs.com/lijingchn/p/5580263.html
三. 安装过程
3.1 下载hadoop安装包
有两种下载方式:
1. 直接去官网下载:
http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
2. 使用wget命令下载:
wget http://mirrors.hust.edu.cn/apache/hadoop/core/stable/hadoop-2.7.1.tar.gz
3.2 配置hadoop
1. 解压下载的hadoop安装包,并修改配置文件。我的解压目录是(/home/hadoop/hadoop-2.7.1),即进入/home/hadoop/文件夹下执行下面的解压缩命令。
tar -zxvf hadoop-2.7..tar.gz
2. 修改配置文件:(hadoop2.7.1/etc/hadoop/)目录下,hadoop-env.sh,core-site.xml,mapred-site.xml.template,hdfs-site.xml。
(1). core-site.xml 配置:其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
(2). mapred-site.xml.template配置:
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
(3). hdfs-site.xml配置: 其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
注意:如果运行Hadoop的时候发现找不到jdk,可以直接将jdk的路径放置在hadoop-env.sh里面,具体如下:
export JAVA_HOME="/opt/java_file/jdk1.7.0_79",即安装java时的路径。
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> </configuration>
配置完成后运行hadoop。
四. 运行hadoop
4.1 初始化HDFS系统
在hadop2.7.1目录下执行命令:
bin/hdfs namenode -format
出现如下结果说明初始化成功。

4.2 开启 NameNode 和 DataNode 守护进程
在hadop2.7.1目录下执行命令:
sbin/start-dfs.sh
成功的截图如下:

4.3 使用jps命令查看进程信息:

若出现如图所示结果,则说明DataNode和NameNode都已经开启。
4.4 查看web界面
在浏览器中输入 http://localhost:50070 ,即可查看相关信息,截图如下
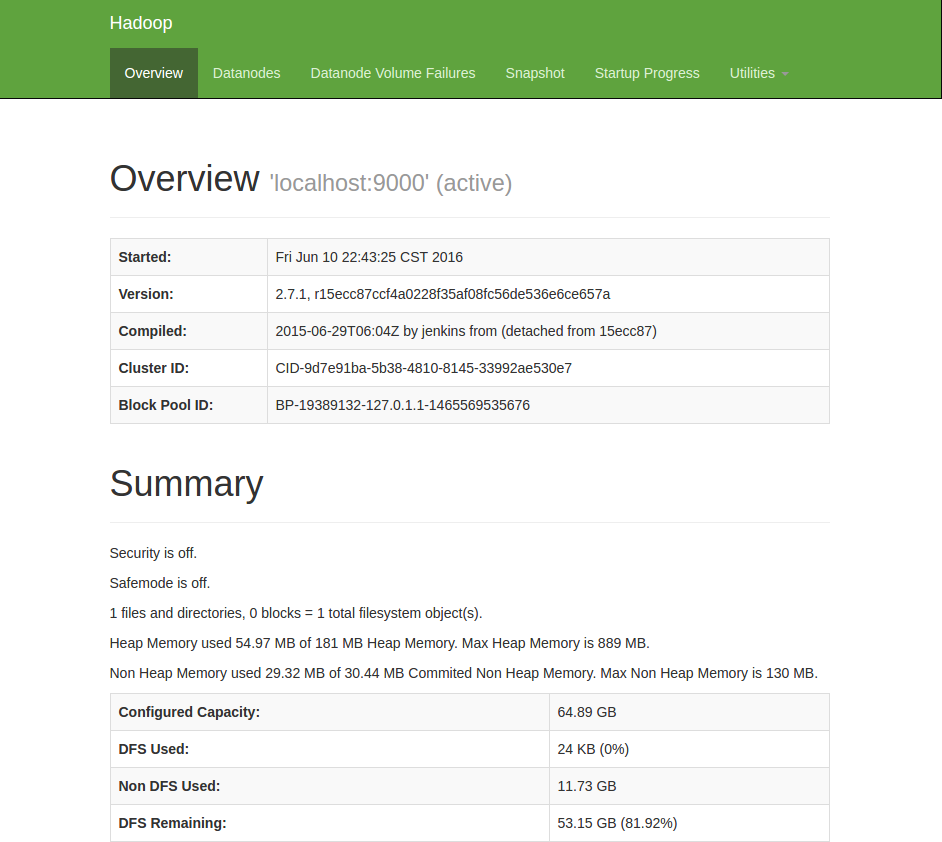
至此,hadoop的环境就已经搭建好了。
五. 运行wordcount demo
1. 在本地新建一个文件,里面内容随便填:例如我在home/hadoop目录下新建了一个haha.txt文件,里面的内容为" hello world! "。
2. 然后在分布式文件系统(hdfs)中新建一个test文件夹,用于上传我们的测试文件haha.txt。在hadoop-2.7.1目录下运行命令:
# 在hdfs的根目录下建立了一个test目录
bin/hdfs dfs -mkdir /test # 查看HDFS根目录下的目录结构
bin/hdfs dfs -ls /
结果如下:

3. 将本地haha.txt文件上传到test目录中;
# 上传
bin/hdfs dfs -put /home/hadoop/haha.txt /test/
# 查看
bin/hdfs dfs -ls /test/
结果如下:

4. 运行wordcount demo;
# 将运行结果保存在/test/out目录下
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7..jar wordcount /test/haha.txt /test/out
# 查看/test/out目录下的文件
bin/hdfs dfs -ls /test/out
结果如下:

运行结果表示:运行成功,结果保存在part-r-00000中。
5. 查看运行结果;
# 查看part-r-00000中的运行结果
bin/hadoop fs -cat /test/out/part-r-
结果如下:

至此,wordcount demo 运行结束。
六. 总结
配置过程遇到了很多问题,最后都一一解决,收获很多,特此把这次配置的经验分享出来,方便想要配置hadoop环境的各位朋友~
(Hadoop集群安装配置过程基本和单机版是一样的,主要是在配置文件方面有所区别,以及ssh无密登陆要求master和slave能够互相无密登陆。具体的配置可以参考:http://www.linuxidc.com/Linux/2015-02/113486.htm)
参考:
http://www.tuicool.com/articles/bmeUneM
Linux中安装配置hadoop集群的更多相关文章
- Linux中安装配置spark集群
一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoop MapReduce所 ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- linux(centos8):安装配置consul集群(consul 1.8.4 | centos 8.2.2004)
一,什么是consul? 1,Consul 是 HashiCorp 公司推出的开源软件,用于实现分布式系统的服务发现与配置. Consul 是分布式的.高可用的. 可横向扩展的 2,官方网站: h ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
- 详解在Linux中安装配置MongoDB
最近在整理自己私人服务器上的各种阿猫阿狗,正好就顺手详细记录一下清理之后重装的步骤,今天先写点数据库的内容,关于在Linux中安装配置MongoDB 说实话为什么会装MongoDB呢,因为之前因为公司 ...
- 详解在Linux中安装配置MySQL
最近在整理自己私人服务器上的各种阿猫阿狗,正好就顺手详细记录一下清理之后重装的步骤,今天先写点数据库的内容,关于在Linux中安装配置MySQL 安装环境 CentOS7 + MySQL5.7 下载安 ...
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
http://blog.csdn.net/whaoxysh/article/details/17755555 虚拟机安装 我安装的虚拟机版本是VMware Workstation 8.04,自己电脑上 ...
- 在 Linux 服务器上搭建和配置 Hadoop 集群
实验条件:3台centos服务器,jdk版本1.8.0,Hadoop 版本2.8.0 注:hadoop安装和搭建过程中都是在用户lb的home目录下,master的主机名为host98,slave的主 ...
- 安装和配置hadoop集群步骤
hadoop集群的安装步骤和配置 hadoop是由java语言编写的,首先我们肯定要在电脑中安装jdk,配置好jdk的环境,接下来就是安装hadoop集群的步骤了,在安装之前需要创建hadoop用户组 ...
随机推荐
- 在Flex (Flash)中嵌入HTML 代码或页面—Flex IFrame
在flex组件中嵌入html代码,可以利用flex iframe.这个在很多时候会用到的,有时候flex必须得这样做,如果你不这样做还真不行…… flex而且可以和html进行JavaScript交互 ...
- windows下安装msysgit 及ruby
一:安装msysgit git是目前最流行的软件版本控制软件,在window下通常使用msysgit 下载:http://msysgit.github.io/ 安装:基本上一路默认下一步就行 安装之后 ...
- (队列的应用5.3.3)POJ 3125 Printer Queue(优先队列的使用)
/* * POJ_3125.cpp * * Created on: 2013年10月31日 * Author: Administrator */ #include <iostream> # ...
- UNIX网络编程读书笔记:基本UDP套接口编程
概述 使用UDP编写的一些流行的应用程序有:DNS(域名系统).NFS(网络文件系统)和SNMP(简单网络管理协议). 如下图所示,给出了典型的UDP客户/服务器程序的函数调用: 客户不与服务器建立连 ...
- Python 整数和浮点数运算
和数学运算不同的地方是,Python的整数运算结果仍然是整数,浮点数运算结果仍然是浮点数:1 + 2 # ==> 整数 31.0 + 2.0 # ==> 浮点数 3.0 整数和浮点数混合运 ...
- SpriteKit改变Node锚点其物理对象位置不对的解决
在创建Node的物理对象后,默认情况下物理对象和Node的实际边界相应的非常好,由于此时Node的默认锚点是当中心位置即(0.5,0.5),只是假设我们改变了Node的锚点,就会发现其物理边界还是保持 ...
- 【centos6.5】安装LNMP(linux公社)
1:查看环境: 1 2 [root@10-4-14-168 html]# cat /etc/redhat-release CentOS release 6.5 (Final) 2:关掉防火墙 1 [r ...
- 本地ubuntu下pycharm 如何利用远程开发环境时显示图片
最近使用pycharm远程开发tensorflow,每次在想显示图像时,苦于不知怎么操作,就通过保存后再看结果,使得调试很不方便.今天打算解决这个问题,收获也是很多啊. 我首先参考了这两篇博客: ht ...
- HTTP长连接?短连接?长轮询?短轮询?
错觉与突然的察觉 大多数人都知道HTTP1.0不支持长连接,知道HTTP1.1支持长连接. 这是业界的一个常识. 然而这样的描述导致了一些不做网络底层开发的开发者都下意识的认为HTTP1.1是一个可以 ...
- 使用jvisualvm进行远程监控
1. 描述 jvisualvm是JDK自带的监控工具,位于JDK bin目录下面. 默认jvisualvm不能监控远程的JVM进程,需要进行一些配置. 2. 单独在应用上配置JVM启动参数 在Java ...