Hadoop2.0环境搭建
需准备的前提条件:
1. 安装JDK(自行安装)
2. 关闭防火墙(centos):
systemctl stop firewalld.service
systemctl disable firewalld.service 编辑 vim /etc/selinux/config文件,修改为:
SELINUX=disabled
源码包下载:
http://archive.apache.org/dist/hadoop/common/
集群环境:
master 192.168.1.99
slave1 192.168.1.100
slave2 192.168.1.101
下载安装包:
# Mater
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz -C /usr/local/src
tar -zxvf hadoop-2.7.5.tar.gz
mv hadoop-2.7.5 /usr/local/hadoop
配置主机
1、编辑/etc/hostname文件
分别配置主机名为master slave1 slave2
2、编辑/etc/hosts,添加对应的域名和ip
cat /etc/hosts
192.168.1.99 master
192.168.1.100 slave1
192.168.1.101 slave2
3. 配置ssh(自行操作,我这边配置的用户是hadoop)
修改配置文件:
cd /usr/local/hadoop/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_91
vim yarn-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_91
slave1
slave2
vim core-site.xml
<configuration>
<property>
<!--指定namenode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.99:9000</value>
</property>
<property>
<!--用来指定使用hadoop时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<!--读写缓存size设定,默认为64M-->
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
vim hdfs-site.xml
<configuration>
<property>
<!--指定hdfs中namenode的存储位置-->
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<!--指定hdfs中datanode的存储位置-->
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<!--指定hdfs保存数据的副本数量-->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<!--为secondary指定访问ip:port-->
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.1.99:9001</value>
</property>
<property>
<!--设置为True就可以直接用namenode的ip:port进行访问,不需要指定端口-->
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
vim mapred-site.xml
<configuration>
<property>
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.99:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.99:19888</value>
</property>
</configuration>
vim yarn-site.xml
<configuration>
<property>
<!--nomenodeManager获取数据的方式是shuffle-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<!--客户端对ResourceManager主机通过 host:port 提交作业-->
<name>yarn.resourcemanager.address</name>
<value>192.168.1.99:8032</value>
</property>
<property>
<!--ApplicationMasters 通过ResourceManager主机访问host:port跟踪调度程序获资源-->
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.99:8030</value>
</property>
<property>
<!--NodeManagers通过ResourceManager主机访问host:port-->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.99:8035</value>
</property>
<property>
<!--管理命令通过ResourceManager主机访问host:port-->
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.99:8033</value>
</property>
<property>
<!--ResourceManager web页面host:port.-->
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.99:8088</value>
</property> <!--我们可以指定yarn的master为哪台机器,与namenode分布在不同的机器上面 -->
<!-- <property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.100</value>
</property>
-->
</configuration>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
#创建临时目录和文件目录
mkdir /usr/local/hadoop/tmp
mkdir -p /usr/local/hadoop/dfs/name
mkdir -p /usr/local/hadoop/dfs/data
配置环境变量:
#Master slave1 slave2
vim ~/.bashrc
HADOOP_HOME=/usr/local/hadoop
PATH=$PATH:$HADOOP_HOME/bin #刷新环境变量
source ~/.bashrc
修改启动脚本保存pid的路径
目的:因为存放pid的路径为/tmp,/tmp是临时目录,系统会定时清理该目录中的文件,所以我们需要修改存放pid的路径
mkdir /usr/local/hadoop/pid
cd /usr/local/hadoop/sbin
sed -i 's/tmp/usr\/local\/hadoop\/pid/g' hadoop-daemon.sh
sed -i 's/tmp/usr\/local\/hadoop\/pid/g' yarn-daemon.sh
拷贝安装包:
# 我用的hadoop用户,需先在从主机上面创建/usr/local/hadoop目录,设置权限chown -R hadoop:hadoop /usr/local/hadoop
rsync -av /usr/local/hadoop/ slave1:/usr/local/hadoop/
rsync -av /usr/local/hadoop/ slave2:/usr/local/hadoop/
启动集群(主机时间需同步):
#初始化Namenode
hadoop namenode -format
./sbin/start-all.sh
集群状态:
#Master

#Slave1
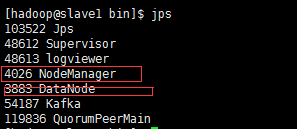
#Slave2

监控网页:
http://master:8088

关闭集群:
./sbin/hadoop stop-all.sh
Hadoop2.0环境搭建的更多相关文章
- ubantu16.04+mxnet +opencv+cuda8.0 环境搭建
ubantu16.04+mxnet +opencv+cuda8.0 环境搭建 建议:环境搭建完成之后,不要更新系统(内核) 转载请注明出处: 微微苏荷 一 我的安装环境 系统:ubuntu16.04 ...
- 菜鸟学自动化测试(八)----selenium 2.0环境搭建(基于maven)
菜鸟学自动化测试(八)----selenium 2.0环境搭建(基于maven) 2012-02-04 13:11 by 虫师, 11419 阅读, 5 评论, 收藏, 编辑 之前我就讲过一种方试来搭 ...
- XNA 4.0 环境搭建和 Hello World,Windows Phone 游戏开发
XNA 4.0 环境搭建和 Hello World,Windows Phone 游戏开发 使用 Scene 类在 XNA 中创建不同的场景(八) 摘要: 平方已经开发了一些 Windows Phone ...
- (win10 64位系统中)Visual Studio 2015+OpenCV 3.3.0环境搭建,100%成功
(win10 64位系统中)Visual Studio 2015+OpenCV 3.3.0环境搭建,100%成功 1.下载opencv 官网http://opencv.org/下载windows版Op ...
- [转]OPENCV3.3+CUDA9.0 环境搭建若干错误总结
编译OpenCV设计启用OpenGL三维可视化支持和启用GPU CUDA并行加速处理的基本知识: 1.从2.4.2版本开始,OpenCV在可视化窗口中支持OpenGL,这就意味着在OpenCV中可以轻 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- vs2012+qt5.2.0环境搭建/vs2013 + qt5.3.2 环境搭建
分类: Windows Qt2014-01-17 00:50 15434人阅读 评论(18) 收藏 举报 此文章已作废,请参考我的新文章: vs2013 + qt5.3.2 环境搭建 ( http:/ ...
- heritrix 3.2.0 -- 环境搭建
heritrix作为一个比较经典的开源爬虫,写这篇文章目的是因为,3.X之后的heritrix的介绍以及配置的文章比较少了. heritrix 3.x 以后使用maven 2配置jar包引用,但是总是 ...
- 云服务器下ASP.NET Core 1.0环境搭建(包含mono与coreclr)
最近.net core如火如荼,国内这方面环境搭建方面的文档也非常多,但是不少已经是过时的,就算按照那个流程走下去也避免不了一些地方早就不一样了.所以下面我将从头到尾的教大家搭建一次环境,并且成功运行 ...
随机推荐
- malloc free, new delete 的异同点
相同点: 都可以动态的申请并释放内存 不同点: 1. 用法不同 <1> malloc 函数为 void* malloc(size_t size), 用于申请一块长度为 size 字节的内存 ...
- ios开发之--UIWebView全属性
最近的项目当中需要用到html和ios的交互,所以就凑空整理一下,所有webView相关的方法和属性,如有不对的地方,请大家不吝指教! 代码如下: 1,创建webview并设置代理 UIWebView ...
- IOS实现打电话后回调
本文转载至 http://blog.csdn.net/cerastes/article/details/38340687 UIWebView *callWebview =[[UIWebView a ...
- GitHub Pages站点官方宣布开始使用HTTPS
导读 数百万人依靠GitHub Pages,将其作为他们的网站主机,除此之外,还有数百万人每天访问这些网站.为了更好地保护到GitHub Pages站点的通讯,也为了鼓励在因特网上更广泛地采用HTTP ...
- hdu1071(定积分求面积)
太弱了,写了一下午,高中基础太差的孩子伤不起... 记住抛物线是关于x轴对称的. 而且抛物线的方程可以是: y=k(x-h)+c //其中(h,c)为顶点坐标 The area Time Limit ...
- 关东升的iOS实战系列图书 《iOS实战:入门与提高卷(Swift版)》已经上市
承蒙广大读者的厚爱我的 <iOS实战:入门与提高卷(Swift版)>京东上市了,欢迎广大读者提出宝贵意见.http://item.jd.com/11766718.html ...
- 160308、java排序(形如1.1、1.2.1)
package com.rick.sample; import java.util.ArrayList; import java.util.Collections; import java.uti ...
- WingIDE6.0神秘代码
python2: import string import random import sha BASE16 = '0123456789ABCDEF' BASE30 = '123456789ABCDE ...
- Python全栈day14-15-16-17(函数)
一,数学定义的函数 函数的定义:给定一个数集A,对A施加对应法则f,记作f(A),得到另一数集B,也就是B=f(A).那么这个关系式就叫函数关系式,简称函数.函数概念含有三个要素:定义域A.值域C和对 ...
- Sass (Syntactically Awesome StyleSheets)
官网:https://www.sass.hk/docs/ Sass 是一款强化 CSS 的辅助工具,它在 CSS 语法的基础上增加了变量 (variables).嵌套 (nested rules).混 ...