R之data.table -melt/dcast(数据合并和拆分)
p.p1 { margin: 0.0px 0.0px 0.0px 0.0px; font: 30.0px "Helvetica Neue"; color: #323333 }
p.p2 { margin: 0.0px 0.0px 0.0px 0.0px; font: 24.0px "Helvetica Neue"; color: #323333 }
p.p3 { margin: 0.0px 0.0px 0.0px 0.0px; font: 12.0px "Helvetica Neue"; color: #323333 }
p.p4 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Courier; color: #323333; background-color: #f5f5f5 }
p.p5 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Courier; color: #323333; background-color: #f5f5f5 }
p.p6 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Courier; color: #323333 }
p.p7 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Courier; color: #999988; background-color: #f5f5f5 }
p.p8 { margin: 0.0px 0.0px 0.0px 0.0px; font: 13.0px Courier; color: #dd2244; background-color: #f5f5f5 }
span.s1 { }
span.s2 { color: #991200 }
span.s3 { color: #687687 }
span.s4 { }
span.s5 { color: #991c73 }
span.s6 { color: #009999 }
span.s7 { }
span.s8 { color: #323333 }
span.s9 { color: #323333 }
span.s10 { color: #dd2244 }
span.s11 { color: #999988 }
R之data.table -melt/dcast(数据拆分和合并)
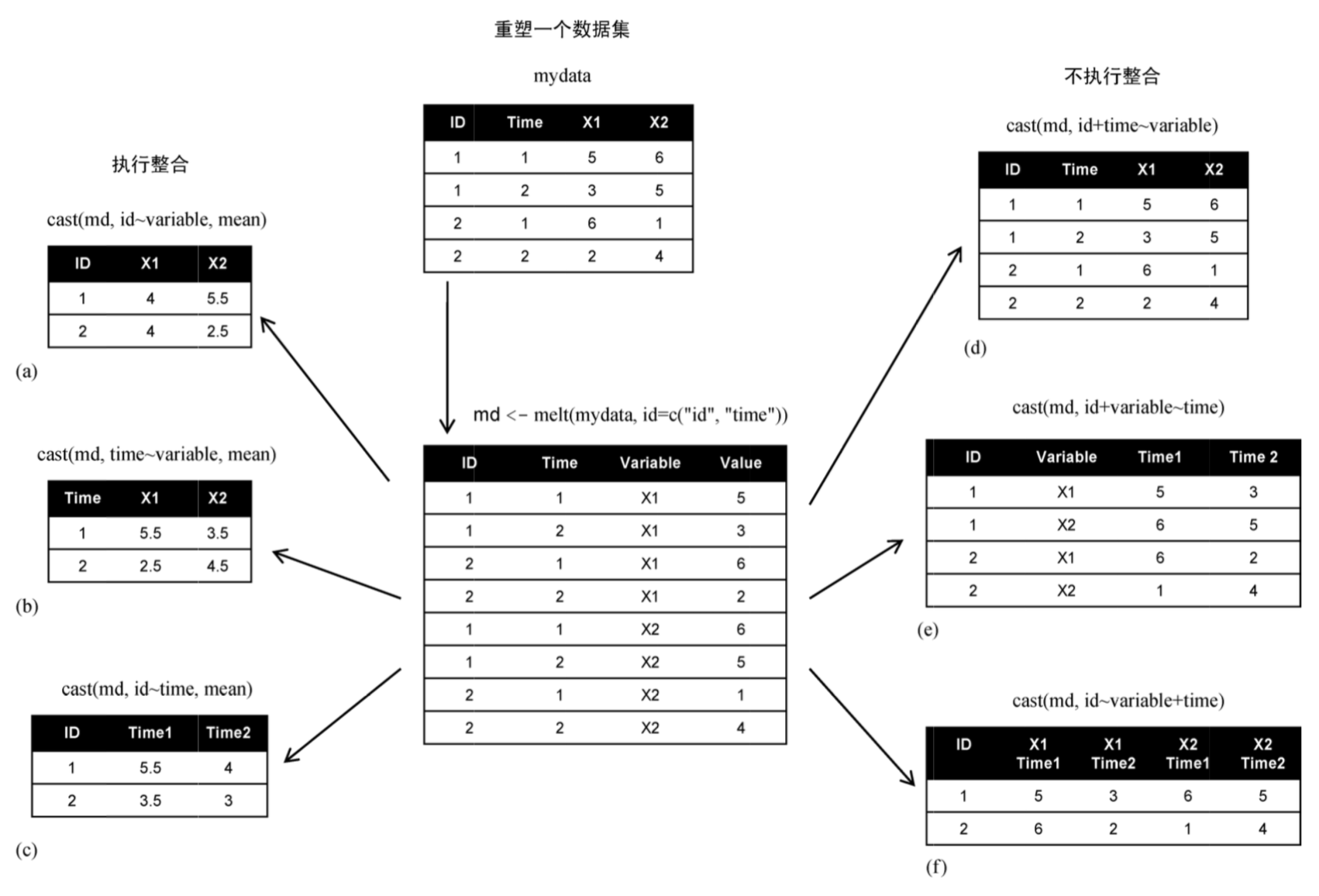
写在前面:数据整形的过程确实和揉面团有些类似,先将数据通过melt()函数将数据揉开,然后再通过dcast()函数将数据重塑成想要的形状
reshape2包:
melt-把宽格式数据转化成长格式。
cast-把长格式数据转化成宽格式。(dcast-输出时返回一个数据框。acast-输出时返回一个向量/矩阵/数组。)
注:melt是数据融合的意思,它做的工作其实就是把数据由“宽”转“长”。
cast 函数的作用除了还原数据外,还可以对数据进行整合。
dcast 输出数据框。公式的左边每个变量都会作为结果中的一列,而右边的变量被当成因子类型,每个水平都会在结果中产生一列。
tidyr包:
gather-把宽度较大的数据转换成一个更长的形式,它类比于从reshape2包中融合函数的功能
spread-把长的数据转换成一个更宽的形式,它类比于从reshape2包中铸造函数的功能。
data.table包:
data.table的函数melt 和dcast 是增强包reshape2里同名函数的扩展
library(data.table)
ID <- c(NA,1,2,2)
Time <- c(1,2,NA,1)
X1 <- c(5,3,NA,2)
X2 <- c(NA,5,1,4)
mydata <- data.table(ID,Time,X1,X2)
mydata
## ID Time X1 X2
## 1: NA 1 5 NA
## 2: 1 2 3 5
## 3: 2 NA NA 1
## 4: 2 1 2 4
md <- melt(mydata, id=c("ID","Time")) #or md <- melt(mydata, id=1:2)
#melt以使每一行都是一个唯一的标识符-变量组合
md #将第一列作为id列,其他列全部融合就可以了
## ID Time variable value
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 NA X1 NA
## 4: 2 1 X1 2
## 5: NA 1 X2 NA
## 6: 1 2 X2 5
## 7: 2 NA X2 1
## 8: 2 1 X2 4
将变量"variable",和"value"揉合在一起,结果产生了新的两列,一列是变量variable,指代是哪个揉合变量,另外一列是取值value,即变量对应的值。我们也称这样逐行排列的方式称为长数据格式
melt:数据集的融合是将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这个测量所需的标识符变量。
str(mydata)
## Classes 'data.table' and 'data.frame': 4 obs. of 4 variables:
## $ ID : num NA 1 2 2
## $ Time: num 1 2 NA 1
## $ X1 : num 5 3 NA 2
## $ X2 : num NA 5 1 4
## - attr(*, ".internal.selfref")=<externalptr>
str(md)
## Classes 'data.table' and 'data.frame': 8 obs. of 4 variables:
## $ ID : num NA 1 2 2 NA 1 2 2
## $ Time : num 1 2 NA 1 1 2 NA 1
## $ variable: Factor w/ 2 levels "X1","X2": 1 1 1 1 2 2 2 2
## $ value : num 5 3 NA 2 NA 5 1 4
## - attr(*, ".internal.selfref")=<externalptr>
setcolorder(md,c("ID","variable","Time","value")) ##setcolorder()可以用来修改列的顺序。
md
## ID variable Time value
## 1: NA X1 1 5
## 2: 1 X1 2 3
## 3: 2 X1 NA NA
## 4: 2 X1 1 2
## 5: NA X2 1 NA
## 6: 1 X2 2 5
## 7: 2 X2 NA 1
## 8: 2 X2 1 4
mdr <- melt(mydata, id=c("ID","Time"),variable.name="Xzl",value.name="Vzl",na.rm = TRUE) #variable.name定义变量名
mdr
## ID Time Xzl Vzl
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 1 X1 2
## 4: 1 2 X2 5
## 5: 2 NA X2 1
## 6: 2 1 X2 4
mdr1 <- melt(mydata, id=c("ID","Time"),variable.name="Xzl",value.name="Vzl",measure.vars=c("X1"),na.rm = TRUE) #measure.vars筛选
mdr1
## ID Time Xzl Vzl
## 1: NA 1 X1 5
## 2: 1 2 X1 3
## 3: 2 1 X1 2
md[Time==1]
## ID variable Time value
## 1: NA X1 1 5
## 2: 2 X1 1 2
## 3: NA X2 1 NA
## 4: 2 X2 1 4
md[Time==2]
## ID variable Time value
## 1: 1 X1 2 3
## 2: 1 X2 2 5
#执行整合
# rowvar1 + rowvar2 + ... ~ colvar1 + colvar2 + ...
# 在这个公式中,rowvar1 + rowvar2 + ... 定义了要划掉的变量集合,以确定各行的内容,而colvar1 + colvar2 + ... 则定义了要划掉的、确定各列内容的变量集合。
newmd<- dcast(md, ID~variable, mean)
newmd
## ID X1 X2
## 1: 1 3 5.0
## 2: 2 NA 2.5
## 3: NA 5 NA
newmd2<- dcast(md, ID+variable~Time)
newmd2
## ID variable 1 2 NA
## 1: 1 X1 NA 3 NA
## 2: 1 X2 NA 5 NA
## 3: 2 X1 2 NA NA
## 4: 2 X2 4 NA 1
## 5: NA X1 5 NA NA
## 6: NA X2 NA NA NA
#ID+variable~Time 使用Time对(ID,variable)分组 Time:1,2,NA 类似excel的数据透析
newmd3<- dcast(md, ID~variable+Time)
newmd3 #variable:X1,X2 Time:1,2,NA 类似excel的数据透析
## ID X1_1 X1_2 X1_NA X2_1 X2_2 X2_NA
## 1: 1 NA 3 NA NA 5 NA
## 2: 2 2 NA NA 4 NA 1
## 3: NA 5 NA NA NA NA NA
R之data.table -melt/dcast(数据合并和拆分)的更多相关文章
- R语言data.table包fread读取数据
R语言处理大规模数据速度不算快,通过安装其他包比如data.table可以提升读取处理速度. 案例,分别用read.csv和data.table包的fread函数读取一个1.67万行.230列的表格数 ...
- R之data.table速查手册
R语言data.table速查手册 介绍 R中的data.table包提供了一个data.frame的高级版本,让你的程序做数据整型的运算速度大大的增加.data.table已经在金融,基因工程学等领 ...
- R(7): data.table
这个包让你可以更快地完成数据集的数据处理工作.放弃选取行或列子集的传统方法,用这个包进行数据处理.用最少的代码,你可以做最多的事.相比使用data.frame,data.table可以帮助你减少运算时 ...
- r里面如何实现两列数据合并为一列
library(dplyr) unite(mtcars, "vs_am", vs, am) Merging Data Adding Columns To merge two dat ...
- R︱高效数据操作——data.table包(实战心得、dplyr对比、key灵活用法、数据合并)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于业务中接触的数据量很大,于是不得不转战开始 ...
- R语言数据分析利器data.table包 —— 数据框结构处理精讲
R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代码简洁,只要一行命令就可以完成诸多任务,另一方面是处理 ...
- R读取大数据data.table包之fread
>library(data.table)>data=fread("10000000.txt")>Read 9999999 rows and 71 (of 71) ...
- R语言数据分析利器data.table包—数据框结构处理精讲
R语言数据分析利器data.table包-数据框结构处理精讲 R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快.包括两个方面,一方面是写的快,代 ...
- 基于R数据分析之常用Package讲解系列--1. data.table
利用data.table包变形数据 一. 基础概念 data.table 这种数据结构相较于R中本源的data.frame 在数据处理上有运算速度更快,内存运用更高效,可认为它是data.frame ...
随机推荐
- Spring注解详解
概述 注释配置相对于 XML 配置具有很多的优势: 它可以充分利用 Java 的反射机制获取类结构信息,这些信息可以有效减少配置的工作.如使用 JPA 注释配置 ORM 映射时,我们就不需要指定 PO ...
- hdu1201-18岁生日
Gardon的18岁生日就要到了,他当然很开心,可是他突然想到一个问题,是不是每个人从出生开始,到达18岁生日时所经过的天数都是一样的呢?似乎并不全都是这样,所以他想请你帮忙计算一下他和他的几个朋友从 ...
- C遇到的问题
1. stdout-------printf输出到stdout,并在终端打印 stderr--------perror错误输出到stderr,并在终端打印 2. usleep(1)//代表一微妙 sl ...
- EmguCV 如何从数组中创建出IntPtr
需要添加引用:System.Runtime.InteropServices 举例如下: float[] priors={1,10}; IntPtr intPtrSet = new IntPtr(); ...
- ServletContext读取Web应用中的资源文件
package cn.itcast; import java.io.FileInputStream; import java.io.IOException; import java.io.InputS ...
- mac svn 更新到新版本1.8
1.执行:brew install scons 如果没装brew,先装它.安装命令如下:curl -LsSf http://github.com/mxcl/homebrew/tarball/maste ...
- (转)php自己创建框架
前言 说到写PHP的MVC框架,大家想到的第一个词--“造轮子”,是的,一个还没有深厚功力的程序员,写出的PHP框架肯定不如那些出自大神们之手.经过时间和各种项目考验的框架.但我还是准备并且这么做了, ...
- Git command line
# Pull the repo from master git pull # Create branch for myself in local git branch john/jenkins_cod ...
- HDU 1176 免费馅饼
免费馅饼 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- AJAX-----05XMLHttpRequest对象的用post方式进行ajax请求
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...