nodejs将PDF文件转换成txt文本,并利用python处理转换后的文本文件
目前公司Web服务端的开发是用Nodejs,所以开发功能的话首先使用Nodejs,这也是为什么不直接用python转换的原因。
由于node对文本的处理(提取所需信息)的能力不强,类似于npm上的包:‘linebyline’、'lineReader',处理能力都不强,所以使用python来处理。
目的:提取PDF中带有‘检查'字样的文本(行)
思路:
1、Nodejs 找到PDF转换text的包,转换,将text文本信息发送到Python服务器。
2、创建一个简单的Python服务器,接收并处理text文本,得到所需要的文本信息,打包成Json并发送到Node服务端。
3、Node服务端接收到后,再发给前端页面将信息展示。
好,那首先我们要去npm官网上找到转换用的包,pdf-textstring是一个不错的包,测试之后,大部分PDF都可以成功转换成text文本,但是有个别文件转换不成功,所以还需要换一个,最后是使用了'pdf2json'这个包,在npm 上找包,有一个要点,就是包名很短,功能很多,类似的处理功能会集中在某个包上,但是包名可能只是其中一种功能。
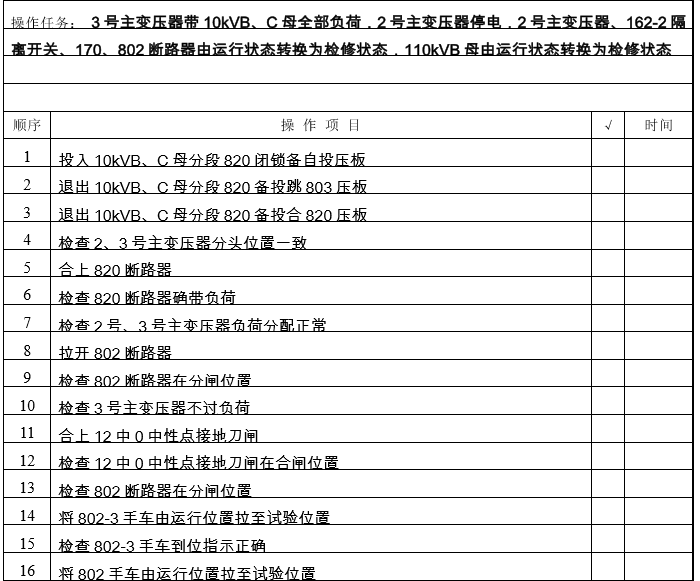
PDF文件样本:
转换代码:
var fs = require('fs'),
PDFParser = require("pdf2json");
var pdfParser = new PDFParser(this, 1);
pdfParser.loadPDF("tmp/testpdf.pdf");
pdfParser.on("pdfParser_dataError", errData => console.error(errData.parserError)); pdfParser.on("pdfParser_dataReady", pdfData => {
data = pdfParser.getRawTextContent()
console.log(‘文本信息:’+data)
});
转换后的文本信息:
操作任务: 3号主变压器带10kVB、C母全部负荷,2号主变压器停电,2号主变压器、162-2隔 离开关、170、802断路器由运行状态转换为检修状态,110kVB母由运行状态转换为检修状态 顺序 操 作 项 目 √ 时间
1 投入10kVB、C母分段820闭锁备自投压板
2 退出10kVB、C母分段820备投跳803压板
3 退出10kVB、C母分段820备投合820压板
4 检查2、3号主变压器分头位置一致
5 合上820断路器
6 检查820断路器确带负荷
7 检查2号、3号主变压器负荷分配正常
8 拉开802断路器
9 检查802断路器在分闸位置
10 检查3号主变压器不过负荷
11 合上12中0中性点接地刀闸
12 检查12中0中性点接地刀闸在合闸位置
13 检查802断路器在分闸位置
14 将802-3手车由运行位置拉至试验位置
15 检查802-3手车到位指示正确
16 将802手车由运行位置拉至试验位置
Node服务端将转换后的文本信息发送到Python服务端:
//Node发送数据并接受返回的处理后的数据
PDFPARSER(data, function(err, result) {
var test = unescape(result.replace(/\\u/g, '%u'))//解python端传来的unicode
res.send(ERRCODE.MakeResult(ERRCODE.OK, JSON.parse(test)));//JSON.parse一次,将解后的字符串换转成Json,发给前端
return;
});
//发送数据的函数
var PDFPARSER = function (reqData, callback) {
var buf = new BUFFER.Buffer(reqData);
var op = {
host: "127.0.0.1",
port: 8087,
method: 'POST',
path: "/",
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
'Content-Length': buf.length
}
};
var req = HTTP.request(op, function (res) {
var recvData = "";
res.on('data', function (chunk) {
recvData += chunk.toString();
});
res.on('end', function () {
if (callback) {
callback(null, recvData);
}
});
});
req.on('error', function (e) {
console.log(e);
});
req.write(reqData);
req.end();
};
Python服务端接受并处理、返还数据:
import sys
import codecs
import SimpleHTTPServer
import SocketServer
import json
import re
from urlparse import urlparse
from urlparse import parse_qs PORT = 8087 class Handler(SimpleHTTPServer.SimpleHTTPRequestHandler):
def do_GET(self):
pass#print self.headers def do_POST(self):
#print self.headers contentLength = int(self.headers["Content-Length"]) textString = self.rfile.read(contentLength)
s = textString.split("\n") test = []
for fileLine in s:
if u'检查' in fileLine:
line_pattern =r'\s*\d+\s?(.*)' def func(text):
c = re.compile(line_pattern)
lists = []
lines = text.split('\n')
for line in lines:
r = c.findall(line)
if r:
lists.append(r[0]) return '\n'.join(lists) result = func(fileLine)
test.append(result)
print test self.send_response(200)
self.send_header('Content-type','text/plain')
self.end_headers()
#print result.decode("utf-8")
#print result
test = {"CZBZ": test}
#这里test的格式是因为前端页面接收数据的格式需要
self.wfile.write(json.dumps(test) ) if __name__ == "__main__":
reload(sys)
sys.setdefaultencoding("utf-8")
httpd = SocketServer.TCPServer(("", PORT), Handler)
print "serving at port", PORT
httpd.serve_forever()
Python处理后的数据:
{"CZBZ":['\xe6\xa3\x80\xe6\x9f\xa52\xe3\x80\x813\xe5\x8f\xb7\xe4\xb8\xbb\xe5\x8f\x98\xe5\x8e\x8b\xe5\x99\xa8\xe5\x88\x86\xe5\xa4\xb4\xe4\xbd\x8d\xe7\xbd\xae\xe4\xb8\x80\xe8\x87\xb4 \r', '\xe6\xa3\x80\xe6\x9f\xa5820\xe6\x96\xad\xe8\xb7\xaf\xe5\x99\xa8\xe7\xa1\xae\xe5\xb8\xa6\xe8\xb4\x9f\xe8\x8d\xb7 \r', '\xe6\xa3\x80\xe6\x9f\xa52\xe5\x8f\xb7\xe3\x80\x813\xe5\x8f\xb7\xe4\xb8\xbb\xe5\x8f\x98\xe5\x8e\x8b\xe5\x99\xa8\xe8\xb4\x9f\xe8\x8d\xb7\xe5\x88\x86\xe9\x85\x8d\xe6\xad\xa3\xe5\xb8\xb8 \r', '\xe6\xa3\x80\xe6\x9f\xa5802\xe6\x96\xad\xe8\xb7\xaf\xe5\x99\xa8\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa53\xe5\x8f\xb7\xe4\xb8\xbb\xe5\x8f\x98\xe5\x8e\x8b\xe5\x99\xa8\xe4\xb8\x8d\xe8\xbf\x87\xe8\xb4\x9f\xe8\x8d\xb7 \r', '\xe6\xa3\x80\xe6\x9f\xa512\xe4\xb8\xad0\xe4\xb8\xad\xe6\x80\xa7\xe7\x82\xb9\xe6\x8e\xa5\xe5\x9c\xb0\xe5\x88\x80\xe9\x97\xb8\xe5\x9c\xa8\xe5\x90\x88\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5802\xe6\x96\xad\xe8\xb7\xaf\xe5\x99\xa8\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5802-3\xe6\x89\x8b\xe8\xbd\xa6\xe5\x88\xb0\xe4\xbd\x8d\xe6\x8c\x87\xe7\xa4\xba\xe6\xad\xa3\xe7\xa1\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5802\xe6\x89\x8b\xe8\xbd\xa6\xe5\x88\xb0\xe4\xbd\x8d\xe6\x8c\x87\xe7\xa4\xba\xe6\xad\xa3\xe7\xa1\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170\xe6\x96\xad\xe8\xb7\xaf\xe5\x99\xa8\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170-2\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170-3\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5162-3\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5162-2\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170-2\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170-20\xe6\x8e\xa5\xe5\x9c\xb0\xe5\x88\x80\xe9\x97\xb8\xe5\x9c\xa8\xe5\x90\x88\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170-3\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5170-30\xe6\x8e\xa5\xe5\x9c\xb0\xe5\x88\x80\xe9\x97\xb8\xe5\x9c\xa8\xe5\x90\x88\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa51B9\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa51B90\xe6\x8e\xa5\xe5\x9c\xb0\xe5\x88\x80\xe9\x97\xb8\xe5\x9c\xa8\xe5\x90\x88\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa5162-2\xe9\x9a\x94\xe7\xa6\xbb\xe5\xbc\x80\xe5\x85\xb3\xe5\x9c\xa8\xe5\x88\x86\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r', '\xe6\xa3\x80\xe6\x9f\xa51B10\xe6\x8e\xa5\xe5\x9c\xb0\xe5\x88\x80\xe9\x97\xb8\xe5\x9c\xa8\xe5\x90\x88\xe9\x97\xb8\xe4\xbd\x8d\xe7\xbd\xae \r']}
nodejs将PDF文件转换成txt文本,并利用python处理转换后的文本文件的更多相关文章
- C# 使用 iTextSharp 将 PDF 转换成 TXT 文本
var pdfReader = new PdfReader("xxx.pdf"); StreamWriter output = new StreamWriter(new FileS ...
- PDF文件可以转换成txt文档吗
PDF是一种便携式的文件格式,传送和阅读都非常方便,是Adobe公司开发的跨平台文件格式,它无论在哪种打印机上都可以保证精确的颜色和准确的打印效果.可是有点遗憾的是PDF格式一般不能在手机上打开,或者 ...
- Python 将pdf转换成txt(不处理图片)
上一篇文章中已经介绍了简单的python爬网页下载文档,但下载后的文档多为doc或pdf,对于数据处理仍然有很多限制,所以将doc/pdf转换成txt显得尤为重要.查找了很多资料,在linux下要将d ...
- PDF转换成Txt
我的弱智想法是所有能转换成PDF的文件,就都用PDF预览,上传成功后开启一个线程把文档转换成PDF,PDF再转换成txt. 目的是把txt插入索引进行全文检索. 调用的时候 string filePa ...
- 【转】java将excel文件转换成txt格式文件
在实际应用中,我们难免会遇到解析excel文件入库事情,有时候为了方便,需要将excel文件转成txt格式文件.下面代码里面提供对xls.xlsx两种格式的excel文件解析,并写入到一个新的txt文 ...
- 把TXT GB2312文件转换成TXT UTF8文件
/// <summary> /// 把TXT GB2312文件转换成TXT UTF8文件 /// </summary> /// < ...
- PDF 补丁丁 0.4.2.891 测试版发布:合并PDF文件时设置书签文本和样式
新的测试版在合并文件界面增加了设置书签样式的功能.除了可以为所合并的图片(或PDF文件)指定书签文本之外,还可以指定其文本样式(文本颜色.粗体.斜体).如下图所示. 此外,合并文件界面还添加了文件夹历 ...
- XML转换成TXT行数据的Java程序
ZKe ------------------- XML数据的一个块内的所有属性,转换成TXT文件的一行.众所周知XML文件是通过类似HTML的标签进行数据的定义如图所示 属性由id, article, ...
- 将Model对象转换成json文本或者json二进制文件
将Model对象转换成json文本或者json二进制文件 https://github.com/casatwy/AnyJson 注意:经过测试,不能够直接处理字典或者数组 主要源码的注释 AJTran ...
随机推荐
- matlab 非平稳变化时域分析
对于非平稳信号,由于傅立叶变换核心函数-正弦函数具有无限性,因此选用短时窗来分析局域信号: 需要注意的时,选取完滑动的时间窗一般是中心对称而且为奇数,这时被分析的时间点正好是滑动窗的中点. 因此,时域 ...
- Markov Random Fields
We have seen that directed graphical models specify a factorization of the joint distribution over a ...
- TCP 状态机
TCP 状态机 TCP 协议的操作可以使用一个具有 11 种状态的有限状态机( Finite State Machine )来表示,图 3-12 描述了 TCP 的有限状态机,图中的圆角矩形表示状态, ...
- substring,substr,和slice的区别详解。
1.Substring(x,y) : 输出一个字符串,当其中只有一个参数时,会输出从x开始到结尾的String. 举例: var str="hello"; conso ...
- Spark 个人实战系列(1)--Spark 集群安装
前言: CDH4不带yarn和spark, 因此需要自己搭建spark集群. 这边简单描述spark集群的安装过程, 并讲述spark的standalone模式, 以及对相关的脚本进行简单的分析. s ...
- 【转载】7 Steps for Calculating the Largest Lyapunov Exponent of Continuous Systems
原文地址:http://sprott.physics.wisc.edu/chaos/lyapexp.htm The usual test for chaos is calculation of the ...
- 【转】浏览器内核、渲染引擎、js引擎
[1]定义 浏览器内核分成两部分渲染引擎和js引擎,由于js引擎越来越独立,内核就倾向于只指渲染引擎 渲染引擎是一种对HTML文档进行解析并将其显示在页面上的工具[2]常见引擎 渲染引擎: firef ...
- urllib2.open(req).read() 报403的错误:怎么办?
http://www.douban.com/group/topic/18095751/ heads = {'Accept':'text/html,application/xhtml+xml,appli ...
- linux 中printf的使用
linux 中printf的使用printf "helloworld\n"printf 中换行必须加上\n printf '%d %s\n' 1 "abc" c ...
- BulkCopy频繁执行产生的性能问题
问题现象: 完整的SQL脚本如下: from all_cons_columns acc, all_constraints ac where acc.owner = ac.owner and acc.c ...