rabbitmq redis
RabbitMQ
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列
用rabbitmq实现一个简单的生产者消费者模型
发送端代码
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel()
channel.queue_declare(queue="hello")
channel.basic_publish(exchange='',
routing_key = 'hello',
body='hello world',
)
print("Send hello world")
connection.close()
接收端代码
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel()
channel.queue_declare(queue="hello")
def callback(ch,method,properties,body):
print(ch,method,properties)
print("received %s" %body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print("waiting for messages to exit press 'CTRL+C'")
channel.start_consuming()
通过上述代码便可以实现一个简单的生产者消费者模型,但是现在的结果是:当开启多个消费者程序的时候,启动生产者发送消息,这个时候只有一个可以收到,并且再次启动,会下一个消费者收到,类似一个轮询的关系。
acknowledgment 消息不丢失(通过客户端设置实现)
通过no_ack = False参数设置,如果消费者遇到情况突然中断了没有收到,那么RabbitMQ会重新将任务添加到队列中
下面将接收端的代码进行更改:
#AUTHOR:FAN
import pika
import time connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel()
channel.queue_declare(queue="hello") def callback(ch,method,properties,body):
print(ch,method,properties)
time.sleep(10)
print("received %s" %body) channel.basic_consume(callback,
queue='hello',
no_ack=False) print("waiting for messages to exit press 'CTRL+C'")
channel.start_consuming()
标注的地方就是代码修改的地方,通过将no_ack更改为False,以及在callback回到函数这里让等待10s,这样启动接收端后,再启动发送算,在还没有打印数据的时候将客户端关闭,然后再启动,发现依然可以收到刚才发送端发送的数据。
但是这种方式只能实现客户端断开重新连接的时候数据不丢失,如果是rabbitmq挂了的情况如何解决?
durable消息不丢失(通过在服务端设置保证数据不丢失)
这个时候生产者和消费者的代码都需要改动
发送者代码
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel()
channel.queue_declare(queue='fan',durable=True)
channel.basic_publish(exchange='',
routing_key='fan',
body='hello world',
properties = pika.BasicProperties(
delivery_mode=2
))
print("send 'hello world'")
connection.close()
接收者的代码
import pika
import time connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel() channel.queue_declare(queue='fan',durable=True) def callback(ch,method,properies,body):
print("received %s" %body)
time.sleep(10)
print("is ok")
ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_consume(callback,
queue='fan',
no_ack=False) print("waitting for messages.To exit press CTRL+C")
channel.start_consuming()
这样即使在接收者接收数据过程中rabbitmq服务器出现问题了,在服务恢复之后,依然可以收到数据
发布订阅

发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
通过exchange type = fanout参数实现
代码例子:
发布者:
#AUTHOR:FAN import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.8.103'))
channel = connection.channel() channel.exchange_declare(exchange="fan",
type='fanout') message = ' '.join(sys.argv[1:]) or "info :hello world"
channel.basic_publish(exchange = 'fan',
routing_key='',
body=message) print("send %s" %message)
connection.close()
订阅者:
#AUTHOR:FAN
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.8.103'))
channel = connection.channel()
channel.exchange_declare(exchange="fan",
type='fanout')
#随机生成队列名字
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
#将exchange和队列绑定
channel.queue_bind(exchange='fan',
queue=queue_name)
print("waiting for fan ,To exit press CTRL+C")
def callback(ch,method,proerties,body):
print("---",body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
关键字发送
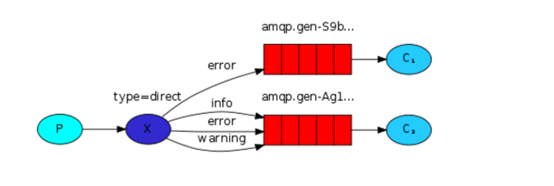
通过参数:exchange type = direct实现
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
代码例子如下:
消费者代码:
#AUTHOR:FAN
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs_1',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
exit(1)
print(severities)
for severity in severities:
print(severity)
channel.queue_bind(exchange='direct_logs_1',
queue=queue_name,
routing_key=severity)
print("waiting for logs,To exit press CTRL+C")
def callback(ch,method,properties,body):
print("%s:%s" %(method.routing_key,body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
生产者代码
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.25'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs_1',
type='direct') print(sys.argv)
severity = sys.argv[1] if len(sys.argv) >1 else "error"
message = ' '.join(sys.argv[2:]) or 'hello world'
channel.basic_publish(exchange='direct_logs_1',
routing_key = severity,
body = message)
print("send %s:%s" %(severity,message))
connection.close()
模糊匹配
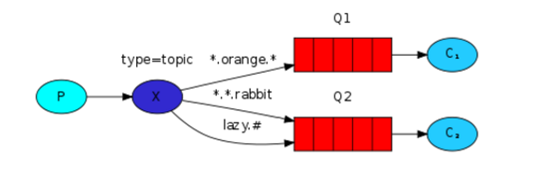
通过参数exchange type = topic实现
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
# 表示可以匹配 0 个 或 多个 单词
* 表示只能匹配 一个 单词
--------------------还没有整理完
rabbitmq redis的更多相关文章
- 现在 做java 构架(RabbitMQ redis mysql )之类的
现在 做java 构架(RabbitMQ redis mysql )之类的
- 消息队列介绍、RabbitMQ&Redis的重点介绍与简单应用
消息队列介绍.RabbitMQ&Redis的重点介绍与简单应用 消息队列介绍.RabbitMQ.Redis 一.什么是消息队列 这个概念我们百度Google能查到一大堆文章,所以我就通俗的讲下 ...
- RabbitMQ+Redis模拟手机验证码登录
RabbitMQ+Redis模拟手机验证码登录 依赖 <dependency> <groupId>org.springframework.boot</groupId> ...
- 冰冻三尺非一日之寒--rabbitMQ,redis
第11章 1.rabbitMQ 2. redis 一.rabbitMQ: 人们写了有好多好多的开源的MQ服务器.其中大多数都是写出来用来解决特定问题的.它们不关心上面跑的是什么类型的消息,设计思想 ...
- Python-Day11 RabbitMQ/redis
写在前面: 好久不写了,实在是不想写,坚持果然是一件不容易的事情. 我喜欢玩,我更爱学习,然而喜欢是放肆,爱是克制,哈哈.每天上班有些忙就不想动,只想在床上翻滚或者鏖战召唤师峡谷.上班闲着时想了想,一 ...
- 使用python操作RabbitMQ,Redis,Memcache,SQLAlchemy 其二
一.概念 1.Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态 ...
- 使用python操作RabbitMQ,Redis,Memcache,SQLAlchemy 其一
一.概念 1.Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态 ...
- Python之异步IO&RabbitMQ&Redis
协程: 1.单线程运行,无法实现多线程. 2.修改数据时不需要加锁(单线程运行),子程序切换是线程内部的切换,耗时少. 3.一个cpu可支持上万协程,适合高并发处理. 4.无法利用多核资源,因为协程只 ...
- Python11 RabbitMQ Redis
本节内容 1.RabbitMQ 2.Redis RabbitMQ队列 安装 http://www.rabbitmq.com/install-standalone-mac.html 安装python r ...
- Python学习-day11 RabbitMQ Redis
这次文章包含两个内容: 1.RabbitMQ使用 2.Redis基础操作 代码部分为练习笔记和作业 概念部分转自Alex老师 RabbitMQ 安装 http://www.rabbitmq.com/i ...
随机推荐
- C语言工具---Code::Blocks
Code::Blocks Code::Blocks 是一个开源的全功能的跨平台C/C++集成开发环境. Code::Blocks是开放源码软件.由纯粹的C++语言开发完成,它使用了著名的图形界面库wx ...
- 采用DOM进行表格的修改操作
2015-08-31 <html> <head> <title>采用DOM进行表格的修改操作</title> <script language=& ...
- [LintCode] Surrounded Regions 包围区域
Given a 2D board containing 'X' and 'O', capture all regions surrounded by 'X'. A region is captured ...
- linux中,常用的账号管理命令
创建新用户:adduser 用户名创建新用户并将其加入一个现有组中:adduser 用户名 -G 组名创建新用户并使其只属于该组:adduser 用户名 -g 组名创建用户密码:passwd 用户名创 ...
- mysql实验
实验步骤同一台电脑装了两个mysql,端口号不同,mysql5.6安装好之后只有一个my-default的文件,将其中添加一些错误内容,改mysql依然可以启动成功,说明使用的不是该文件,将my-de ...
- 20145334 第五次 java 实验报告
实验内容 1.掌握Socket程序的编写: 2.掌握密码技术的使用: 3.设计安全传输系统. 我和20145306张文锦组队编程 http://www.cnblogs.com/besti145306/ ...
- NLP文本情感分类传统模型+深度学习(demo)
文本情感分类: 文本情感分类(一):传统模型 摘自:http://spaces.ac.cn/index.php/archives/3360/ 测试句子:工信处女干事每月经过下属科室都要亲口交代24口交 ...
- Asp.net点击按钮弹出文件夹选择框的实现(网页)
本文地址:http://www.cnblogs.com/PiaoMiaoGongZi/p/4092112.html 在Asp.net网站实际的开发中,比如:需要实现点击一个类似于FileUpload的 ...
- IOS第一天多线程-03线程间通信
**** #import "HMViewController.h" @interface HMViewController () @property (weak, nonatomi ...
- IOS第16天(4,Quartz2D柱状图)
*** #import "HMBarView.h" #import "UIColor+Random.h" @implementation HMBarView - ...