Hadoop NameNode HA 和 ResourceManager HA
1、集群规划
1.1 规划说明
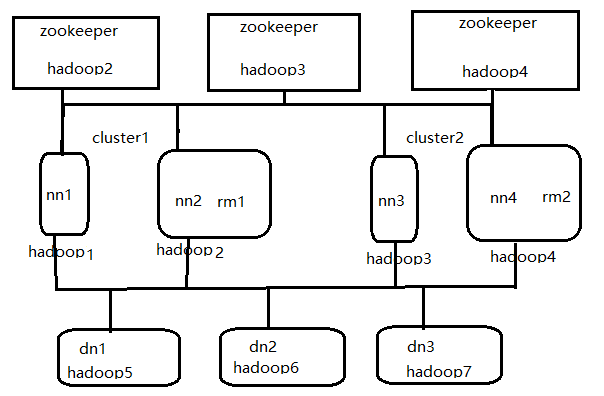
hadoop1 cluster1 nameNode
hadoop2 cluster1 nameNodeStandby ZooKeeper ResourceManager
hadoop3 cluster2 nameNode ZooKeeper
hadoop4 cluster2 nameNodeStandby ZooKeeper ResourceManagerStandBy
hadoop5 DataNode
hadoop6 DataNode
hadoop7 DataNode
1.2 集群 拓扑图
2、hadoop配置
2.1 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value>
</property>
</configuration>
2.2 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration> <property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可。-->
<property>
<name>dfs.nameservices</name>
<value>cluster1,cluster2</value>
</property>
<!--使用federation时,使用了2个HDFS集群。这里抽象出两个NameService实际上就是给这2个HDFS集群起了个别名。名字可以随便起,相互不重复即可 --> <!-- 以下是集群cluster1的配置信息-->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
</property>
<!-- 指定NameService是cluster1时的namenode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>hadoop1:9000</value>
</property>
<!-- 指定hadoop1的RPC地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- 指定hadoop1的http地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>hadoop2:9000</value>
</property>
<!-- 指定hadoop2的RPC地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>hadoop2:50070</value>
</property>
<!-- 指定hadoop2的http地址 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop2:8485;hadoop3:8485;hadoop4:8485/cluster1</value>
</property>
<!-- 指定cluster1的两个NameNode共享edits文件目录时,使用的JournalNode集群信息,在cluster1中配置此信息 -->
<property>
<name>dfs.ha.automatic-failover.enabled.cluster1</name>
<value>true</value>
</property>
<!-- 指定cluster1是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定cluster1出故障时,哪个实现类负责执行故障切换 --> <!-- 以下是集群cluster2的配置信息-->
<property>
<name>dfs.ha.namenodes.cluster2</name>
<value>nn3,nn4</value>
</property>
<!-- 指定NameService是cluster2时的namenode有哪些,这里的值也是逻辑名称,名字随便起,相互不重复即可 -->
<property>
<name>dfs.namenode.rpc-address.cluster2.nn3</name>
<value>hadoop3:9000</value>
</property>
<!-- 指定hadoop3的RPC地址 -->
<property>
<name>dfs.namenode.http-address.cluster2.nn3</name>
<value>hadoop3:50070</value>
</property>
<!-- 指定hadoop3的http地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster2.nn4</name>
<value>hadoop4:9000</value>
</property>
<!-- 指定hadoop4的RPC地址 -->
<property>
<name>dfs.namenode.http-address.cluster2.nn4</name>
<value>hadoop4:50070</value>
</property>
<!-- 指定hadoop4的http地址 -->
<!--
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop2:8485;hadoop3:8485;hadoop4:8485/cluster2</value>
</property>
-->
<!-- 指定cluster2的两个NameNode共享edits文件目录时,使用的JournalNode集群信息,在cluster2中配置此信息 -->
<property>
<name>dfs.ha.automatic-failover.enabled.cluster2</name>
<value>true</value>
</property>
<!-- 指定cluster2是否启动自动故障恢复,即当NameNode出故障时,是否自动切换到另一台NameNode -->
<property>
<name>dfs.client.failover.proxy.provider.cluster2</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 指定cluster2出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop/jndir</value>
</property>
<!-- 指定JournalNode集群在对NameNode的目录进行共享时,自己存储数据的磁盘路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/datadir</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/namedir</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 一旦需要NameNode切换,使用ssh方式进行操作 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 一旦需要NameNode切换,使用ssh方式进行操作 -->
</configuration>
2.3 mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
--> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2.4 yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop5</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop6</value>
</property>
<!--开启故障自动切换-->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--在RM1上配置rm1,在MR2上配置rm2,注意:一般都喜欢把配置好的文件远程复制到其它机器上,但这个在YARN的另一个机器上一定要修改-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node, we need this configuration</description>
</property>
<!--
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
<description>If we want to launch more than one RM in single node, we need this configuration</description>
</property>
-->
<!--配置与zookeeper的连接地址-->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop2:2181,hadoop3:2181,hadoop4:2181</value>
</property>
<!--开启自动恢复功能-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--schelduler失联等待连接时间-->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!--配置rm1-->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop2:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop2:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop2:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop2:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop2:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>hadoop2:23142</value>
</property> <!--配置rm2-->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop4:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop4:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop4:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop4:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop4:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>hadoop4:23142</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/hadoop/yarn/log/</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!--故障处理类-->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
2.5 slaves文件
hadoop5
hadoop6
hadoop7
3 zookeeper 配置
3.1 zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
#dataDir=/tmp/zookeeper
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
dataDir=/home/hadoop/zookeeper/data
dataLogDir=/home/hadoop/zookeeper/log
server.1=hadoop2:2888:3888
server.2=hadoop3:2888:3888
server.3=hadoop4:2888:3888
3.2 配置myid
在zookeeper data目录中分别执行
echo > myid
echo > myid
echo > myid
4 集群初始化及启动
4.1 在 hadoop2,hadoop3,hadoop4启动zookeeper
cd apps/zookeeper-3.4./
bin/zkServer.sh start
4.2 格式化zookeeper集群,在hadoop1、hadoop3 执行
hdfs zkfc -formatZK
4.3 启动JournalNode集群,在hadoop2,hadoop3,hadoop4 上执行
hadoop-daemon.sh start journalnode
4.4 格式化cluster1的namenode 在hadoop1上执行
hdfs namenode -format -clusterId c1
4.5 启动cluster1格式化后的namenode,在hadoop1上执行
hadoop-daemon.sh start namenode
4.6 把NameNode的数据从hadoop1同步到hadoop2中
hdfs namenode -bootstrapStandby
4.7 启动hadoop2即cluster1 nameNodeStandby
hadoop-daemon.sh start namenode
4.8 格式化cluster2的namenode 在hadoop3上执行
hdfs namenode -format -clusterId c2
4.9 启动cluster2格式化后的namenode,在hadoop3上执行
hadoop-daemon.sh start namenode
4.10 把NameNode的数据从hadoop3同步到hadoop4中在hadoop4上执行
hdfs namenode -bootstrapStandby
4.11 启动hadoop4即cluster2 namenode的standby
hadoop-daemon.sh start namenode
4.12 启动所有 datanode,在任何一个namenode上执行
hadoop-daemons.sh start datanode
4.13 启动yarn 在hadoop2上执行
start-yarn.sh
4.14 启动yarn 在hadoop4上执行
yarn-daemon.sh start resourcemanager
4.15 启动ZooKeeperFailoverController在每个namenode上执行
hadoop-daemon.sh start zkfc
Hadoop NameNode HA 和 ResourceManager HA的更多相关文章
- 安装部署Apache Hadoop (完全分布式模式并且实现NameNode HA和ResourceManager HA)
本节内容: 环境规划 配置集群各节点hosts文件 安装JDK1.7 安装依赖包ssh和rsync 各节点时间同步 安装Zookeeper集群 添加Hadoop运行用户 配置主节点登录自己和其他节点不 ...
- Hadoop-2.3.0-cdh5.0.1完全分布式环境搭建(NameNode,ResourceManager HA)
编写不易,转载请注明(http://shihlei.iteye.com/blog/2084711)! 说明 本文搭建Hadoop CDH5.0.1 分布式系统,包括NameNode ,Resource ...
- 【Hadoop学习】Apache Hadoop ResourceManager HA
简介 本向导简述了YARN资源管理器的HA,并详述了如何配置并使用该特性.RM负责追踪集群中的资源,并调度应用程序(如MapReduce作业).Hadoop2.4以前,RM是YARN集群中的单点故障. ...
- Hadoop 2.6.0 Namenode HA,ResourceManager HA
先启动所有的zookeeper zkServer.sh start 在所有节点上启动JournalNode: sbin/hadoop-daemon.sh start journalnode 格式化第一 ...
- hadoop NameNode HA 和ResouceManager HA
官网配置地址: HDFS HA : http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSHighAvai ...
- hadoop namenode HA集群搭建
hadoop集群搭建(namenode是单点的) http://www.cnblogs.com/kisf/p/7456290.html HA集群需要zk, zk搭建:http://www.cnblo ...
- Apache hadoop namenode ha和yarn ha ---HDFS高可用性
HDFS高可用性Hadoop HDFS 的两大问题:NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用--阶段性的合并edits和fsimage,以缩短集群启动的时 ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
- Hadoop 2、配置HDFS HA (高可用)
前提条件 先搭建 http://www.cnblogs.com/raphael5200/p/5152004.html 的环境,然后在其基础上进行修改 一.安装Zookeeper 由于环境有限,所以在仅 ...
随机推荐
- 【[CQOI2016]手机号码】
递推版的数位dp 绝对的暴力美学 我们设\(dp[l][i][j][0/1][0/1][0/1]\)表示到了第\(l\)位,这一位上选择的数是\(i\),\(l-1\)位选择的数是\(j\),第一个\ ...
- [19/04/24-星期三] GOF23_创建型模式(建造者模式、原型模式)
一.建造者模式 本质:分离了对象子组件的单独构造(由Builder负责)和装配的分离(由Director负责),从而可以构建出复杂的对象,这个模式适用于:某个对象的构建过程十分复杂 好处:由于构建和装 ...
- windows下搭建nginx+php开发环境
windows下搭建nginx+php开发环境 1.前言 windows下大多我们都是下载使用集成环境,但是本地已经存在一个集成环境,但不适合项目的需求.因此准备再自己搭建一个环境. 2.准备 工具: ...
- PHP扩展功能----cURL
一.入门三部曲 1.cURL是什么? wikipedia介绍: * cURL是一个利用URL语法在命令行下工作的文件传输工具,1997年首次发行.它支持文件上传和下载,所以是综合传输工具,但按传统,习 ...
- PHP去重可用
//国外 $arr6 = array_merge($arr2,$arr4); $arr8 = array(); $arr10 = array(); foreach($arr6 as $k6=> ...
- Android ProgressBar 进度条荧光效果
http://blog.csdn.net/ywtcy/article/details/7878289 这段时间做项目,产品需求,进度条要做一个荧光效果,类似于Android4.0 浏览器中进度条那种样 ...
- HDU 1165 Eddy's research II(给出递归公式,然后找规律)
- Eddy's research II Time Limit:2000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64 ...
- SQL 语句 merge into
MERGE INTO tb_st_shxxcount tt USING ( SELECT DISTINCT sd.CODE, COUNT (ts.LRDW) count1, TO_CHAR (ts.L ...
- Delphi XE10在 Android下调用静态库a文件
Delphi Seatle can link Delphi project with Static library files(*.a): 1.at Delphi IDE, Add the " ...
- SharePoint2010QuickFlow安装及使用
一:QuickFlow的安装 1,从http://quickflow.codeplex.com/下载解决方案包以及设计器. 2,将QuickFlow.dll以及QuickFlow.UI.dll添加到程 ...