TDDL调研笔记
一,TDDL是什么
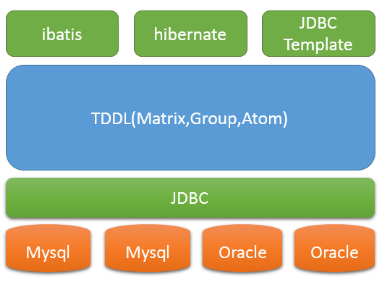
Taobao Distributed Data Layer,即淘宝分布式数据层,简称TDDL 。它是一套分布式数据访问引擎
淘宝一个基于客户端的数据库中间件产品
基于JDBC规范,没有server,以client-jar的形式存在
TDDL是一套分布式数据访问引擎,主要解决三个问题:
- 数据访问路由,将数据的读写请求发送到最合适的地方;
- 数据的多向非对称复制,一次写入,多点读取;
- 数据存储的自由扩展,不再受限于单台机器的容量瓶颈与速度瓶颈,平滑迁移。它遵守JDBC规范,支持mysql和oracle,具有分库分表、主备切换、读写分离、动态数据源配置等功能。
三层架构(可独立使用):
- Matrix(TDataSource)实现分库分表逻辑,持有多个Group实例;
- Group(TGroupDataSource)实现数据库的主备切换,读写分离逻辑,持有多个Atom实例;
- Atom(TAtomDataSource)实现数据库ip,port,password,connectionProperties等信息的动态推送,持有原子的数据源(分离的Jboss数据源)。
其它结构
- tddl-client:应用启动时初始化配置信息(规则信息,各层数据源拓扑结构,初始化是自上而下的Matrix的dsMap,Group的GroupDs,AtomDs),runtime
- tddl-rule:分库分表规则解析
- tddl-sequence:统一管理和分配全局唯一sequence(序列号)
- tddl-druid-datasource:数据库连接池(高效,可扩展性好),类dbcp、c3p0
二,TDDL不支持什么SQL
不支持各类join
不支持多表查询
不支持between/and
不支持not(除了支持not like)
不支持comment,即注释
不支持for update
不支持group by中having后面出现集函数
不支持force index
不支持mysql独有的大部分函数
画外音:分布式数据库中间件,join都是很难支持的,cobar号称的对join的支持即有限,又低效。
三,TDDL支持什么SQL
支持CURD基本语法
支持as
支持表名限定,即"table_name.column"
支持like/not like
支持limit,即mysql的分页语法
支持in
支持嵌套查询,由于不支持多表,只支持单表的嵌套查询
画外音:分布式数据库中间件,支持的语法都很有限,但对于与联网的大数据/高并发应用,足够了,服务层应该做更多的事情。
四,TDDL其他特性
支持oracle和mysql
支持主备动态切换
支持带权重的读写分离
支持分库分表
支持主键生成:oracle用sequence来生成,mysql则需要建立一个用于生成id的表
支持单库事务,不支持跨库事务
支持多库多表分页查询,但会随着翻页,性能降低
画外音:可以看到,其实TDDL很多东西都不支持,那么为什么它还如此流行呢?它解决的根本痛点是“分布式”“分库分表”等。
加入了解决“分布式”“分库分表”的中间件后,SQL功能必然受限,但是,我们应该考虑到:MYSQL的CPU和MEM都是非常珍贵的,我们应该将MYSQL从复杂的计算(事务,JOIN,自查询,存储过程,视图,用户自定义函数,,,)中释放解脱出来,将这些计算迁移到服务层。
当然,有些后台系统或者支撑系统,数据量小或者请求量小,没有“分布式”的需求,为了简化业务逻辑,写了一些复杂的SQL语句,利用了MYSQL的功能,这类系统并不是分布式数据库中间件的潜在用户,也不可能强行让这些系统放弃便利,使用中间件。
五,TDDL层次结构
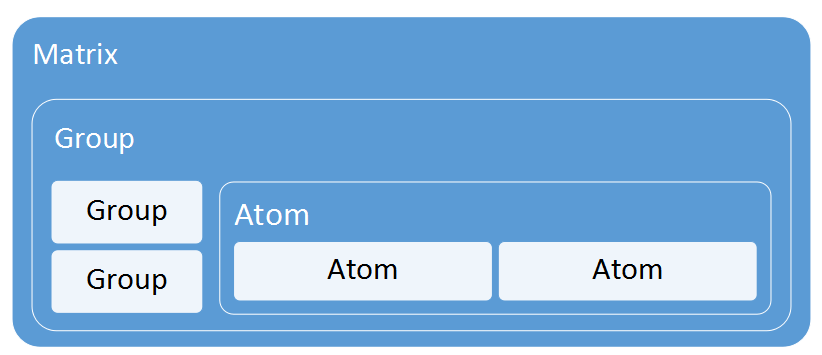
TDDL是一个客户端jar,它的结构分为三层:
|
层次 |
说明 |
其他 |
|
matrix |
可以理解为数据源的全部,它由多个group组成 |
|
|
group |
可以理解为一个分组,它由多个atom组成 |
|
|
atom |
可以理解为一个数据库,可能是读库,也可能是写库 |
matrix层
核心是规则引擎
实现分库分表
主要路径:sql解析 => 规则引擎计算(路由) => 执行 => 合并结果
group层
读写分离
权重计算
写HA切换
读HA切换
动态新增slave(atom)节点
atom层
单个数据库的抽象;
ip /port /user /passwd /connection 动态修改,动态化jboss数据源
thread count(线程计数):try catch模式,保护业务处理线程
动态阻止某些sql的执行
执行次数的统计和限制
整个SQL执行过程

六,TDDL最佳实践
尽可能使用1对多规则中的1进行数据切分(patition key),例如“用户”就是一个简单好用的纬度
买家卖家的多对多问题,使用数据增量复制的方式冗余数据,进行查询
利用表结构的冗余,减少走网络的次数,买家卖家都存储全部的数据
画外音:这里我展开一下这个使用场景。
以电商的买家卖家为例,业务方既有基于买家的查询需求,又有基于卖家的查询需求,但通常只能以一个纬度进行数据的分库(patition),假设以买家分库, 那卖家的查询需求如何实现呢?
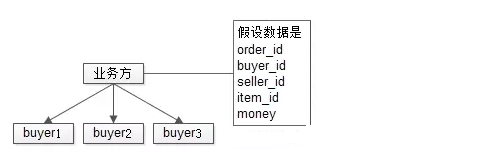
如上图所示:查询买家所有买到的订单及商品可以直接定位到某一个分库,但要查询卖家所有卖出的商品,业务方就必须遍历所有的买家库,然后对结果集进行合并,才能满足需求。
所谓的“数据增量复制”“表结构冗余”“减少网络次数”,是指所有的数据以买家卖家两个纬度冗余存储两份,如下图:
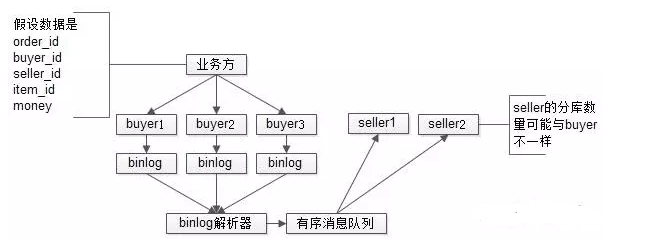
采用一个异步的消息队列机制,将数据以另一个纬度增量复制一份,在查询的时候,可以直接以卖家直接定位到相应的分库。
这种方式有潜在的数据不一致问题。
继续tddl最佳实践:
利用单机资源:单机事务,单机join
存储模型尽量做到以下几点:
- 尽可能走内存
- 尽可能将业务要查询的数据物理上放在一起
- 通过数据冗余,减少网络次数
- 合理并行,提升响应时间
- 读瓶颈通过增加slave(atom)解决
- 写瓶颈通过切分+路由解决
画外音:相比数据库中间件内核,最佳实践与存储模型,对我们有更大的借鉴意义。
七、TDDL的未来?
kv是一切数据存取最基本的组成部分
存储节点少做一点,业务代码就要多做一点
想提升查询速度,只有冗余数据一条路可走
类结构化查询语言,对查询来说非常方便
画外音:潜台词是,在大数据量高并发下,SQL不是大势所趋,no-sql和定制化的协议+存储才是未来方向?
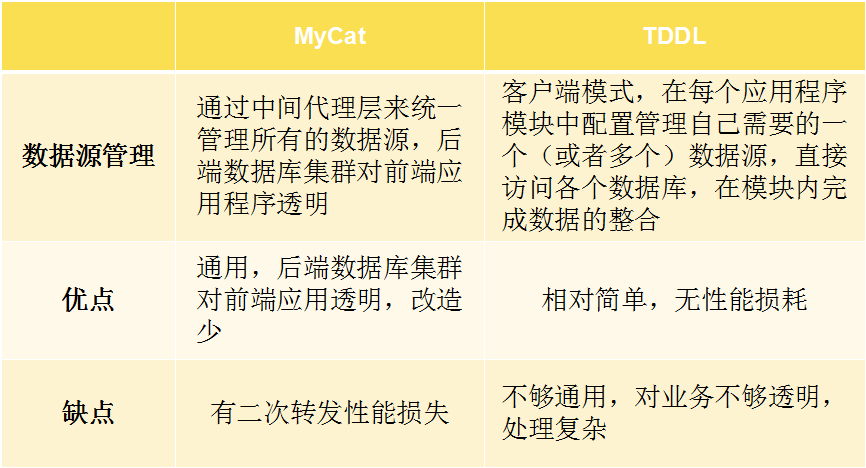
分布式数据中间件TDDL、Amoeba、Cobar、MyCAT架构比较
TDDL调研笔记的更多相关文章
- Spark调研笔记第2篇 - 怎样通过Sparkclient向Spark提交任务
在上篇笔记的基础上,本文介绍Sparkclient的基本配置及Spark任务提交方式. 1. Sparkclient及基本配置 从Spark官网下载的pre-built包中集成了Sparkclient ...
- Chrome DevTools 调研笔记
1 说明 此篇文章针对Chrome DevTools常用功能进行调研分析.描述了每个功能点能实现的功能.应用场景和详细操作. 2 Elements 2.1 功能 检查和实时更新页面的HTML与C ...
- MySQL调研笔记1:MySQL调研清单
0x00 背景 最近公司正在去微软化,之前使用的SQL Server.Oracle将逐步切换到MySQL,所以部门也会跟随公司步伐,一步步将现有业务从SQL Server切换到MySQL,当然上MyS ...
- iOS过场动画调研笔记
前言 因项目须要,近期一段时间都在调研iOS的过场动画.对于我来说这是一个之前没有太涉及的领域,所以有必要把调研的过程和自己的一些理解纪录下来 为什么要自己定义过场动画? 假设大家有关注Materia ...
- 一个网络传输框架——zeroMQ 调研笔记
一.它是什么 zeroMQ,一个处理消息传输的库,重点在传输上,看起来它像是在socket上面封装了一层,让我们可以很容易的利用它来做N对M的数据传输,在分布式系统中很方便,在接收端它有round-r ...
- Hadoop 调研笔记
由于从各光伏电站采集的数据量较大,必须解决海量数据的查询.分析的问题.目前主要考虑两种方式:1. Hadoop大数据技术:2. Oracle(数据仓库)+BI: 本文仅介绍hadoop的技术 ...
- Mono for Android开发调研笔记
安装完Mono for Android(简称:MonoDroid)之后,可以用MonoDevelop或Visual Studio来开发Mono for Android应用程序:目前只能在模拟器上调试和 ...
- Spark调研笔记第4篇 - PySpark Internals
事实上.有两个名为PySpark的概念.一个是指Sparkclient内置的pyspark脚本.而还有一个是指Spark Python API中的名为pyspark的package. 本文仅仅对第1个 ...
- Spark调研笔记第6篇 - Spark编程实战FAQ
本文主要记录我使用Spark以来遇到的一些典型问题及其解决的方法,希望对遇到相同问题的同学们有所帮助. 1. Spark环境或配置相关 Q: Sparkclient配置文件spark-defaults ...
随机推荐
- 2017-2018-1 20155320《信息安全技术》实验二——Windows口令破解
2017-2018-1 20155320<信息安全技术>实验二--Windows口令破解 实验目的 了解Windows口令破解原理 对信息安全有直观感性认识 能够运用工具实现口令破解 实验 ...
- # 2017-2018-1 20155337《信息安全系统设计基础》第5周学习总结+mybash
2017-2018-1 20155337<信息安全系统设计基础>第5周学习总结 教材学习内容总结 不论我们是在用C语言还是用JAVA或是其他的语言编程时,我们会被屏蔽了程序的机器级的实现. ...
- Zabbix学习之路(八)之自动化监控网络发现和主动注册
1.网络发现 分两步走:创建发现规则(rule)和执行的动作(Action)(1)创建发现规则"Configuration"-->"Create discover ...
- 实时备份工具之inotify+rsync
1.inotify简介 inotify 是一个从 2.6.13 内核开始,对 Linux 文件系统进行高效率.细粒度.异步地监控机制, 用于通知用户空间程序的文件系统变化.可利用它对用户空间进行安全. ...
- a data verification error occurred, file load failed
1. 调试创龙DSP6748的时候,下载.out文件出现这个错误 2. 换了其他板子,还有其他仿真器也不行,最后发现是没加载GEL文件
- 我们一起学习WCF 第三篇头消息验证用户身份
前言:今天我主要写的是关于头消息的一个用处验证用户信息 下面我画一个图,可以先看图 第一步:我们先开始做用户请求代码 首先:创建一个可执行的上下文对象块并定义内部传输的通道 using (Operat ...
- 英特尔® 实感™ 摄像头 (F200) 应用如何实现最佳用户体验
英特尔开发人员专区原文 由于视频不能直接嵌入, 请点击视频标题观看.谢谢. 英特尔® 实感™ 技术支持我们重新定义如何与计算设备交互,包括允许用户通过手势自然交互. 为了帮助大家了解使用英特尔® 实感 ...
- [python] Queue.Queue vs. collections.deque
https://stackoverflow.com/questions/717148/queue-queue-vs-collections-deque/717199#717199 Queue,Queu ...
- Wampserver 修改根目录
wampserver 默认根目录在 www 文件夹下 修改根目录方法如下: 1. 在打算存放项目或代码的位置新建文件夹(我建在了C:/MyProject) 2. 打开 httpd.conf 文件(该文 ...
- C++ STL 优先队列 priority_queue 详解(转)
转自https://blog.csdn.net/c20182030/article/details/70757660,感谢大佬. 优先队列 引入 优先队列是一种特殊的队列,在学习堆排序的时候就有所了解 ...