【倍增】LCM QUERY
给一个序列,每次给一个长度l,问长度为l的区间中lcm最小的。
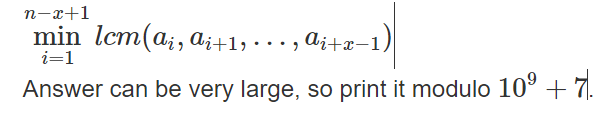
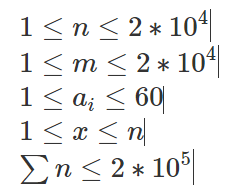
题解:因为ai<60,所以以某个点为左端点的区间的lcm只有最多60种的情况,而且相同的lcm区间的连续的。
所以就想到一个n*60*logn的做法,倍增找出每个点的区间lcm情况,然后修改答案……
1-60的lcm的积大于long long,只能把数拆开,然后比较时用log,结果才用这个数的质因数相乘。
问题在于一开始我对于每个点开个20的数组记录60内第几个质数的个数,这样每次常数就要再乘个20,然后就tle……
优化的方法是位运算,因为只会是2,3,5,7的次幂大于1次,单独记录,其他的只会是0次幂和1次幂。
最后作死的两个小错误:33不是质数……,用ln【60】数组记录log的值然而其中对n取对数……
#include<cstring>
#include<cstdio>
#include<algorithm>
#include<cmath>
#define maxn 40000
#define mm 1000000007
#define LL long long
#define inf 100000000000
#define rep(i,l,r) for(int i=l;i<=r;i++)
#define dow(i,l,r) for(int i=r;i>=l;i--)
using namespace std; typedef struct {
int v1;
double v2;
}Big;
Big tree[maxn*];
double ln[maxn];
int f[maxn][],now;
int n,m,maxln,tot=;
LL ans1[maxn],ans2[maxn];
int pri[]={,,,,
,,,,
,,,,
,,,,
,,,,
,,,,}; double calc(int x)
{
double sum=;
rep(i,,tot)
if ((x>>i)&)
sum+=ln[pri[i]];
dow(i,,)
if ((x>>i)&) {
sum+=(i+)*ln[];
break;
}
if ((x>>)&) sum+=*ln[];
else
if ((x>>)&) sum+=*ln[];
else
if ((x>>)&) sum+=ln[]; if ((x>>)&) sum+=*ln[];
else
if ((x>>)&) sum+=ln[]; if ((x>>)&) sum+=*ln[];
else
if ((x>>)&) sum+=ln[]; return sum;
} LL answer(Big x)
{
LL sum=;
rep(i,,tot)
if ((x.v1>>i)&)
sum=sum*pri[i]%mm;
dow(i,,)
if ((x.v1>>i)&) {
sum=sum*pri[i]%mm;
break;
}
if ((x.v1>>)&) sum=sum*%mm;
else
if ((x.v1>>)&) sum=sum*%mm;
else
if ((x.v1>>)&) sum=sum*%mm; if ((x.v1>>)&) sum=sum*%mm;
else
if ((x.v1>>)&) sum=sum*%mm; if ((x.v1>>)&) sum=sum*%mm;
else
if ((x.v1>>)&) sum=sum*%mm; return sum;
} void build(int x,int l,int r)
{
tree[x].v2=inf;
if (l==r) return;
int mid=(l+r)>>;
build(x<<,l,mid);
build(x<<|,mid+,r);
} void change(int x,int l,int r,int ll,int rr,double z)
{
if (tree[x].v2<=z) return;
if (ll<=l && r<=rr) {
tree[x].v1=now;
tree[x].v2=z;
return;
}
int mid=(l+r)>>;
if (ll<=mid) change(x<<,l,mid,ll,rr,z);
if (rr>mid) change(x<<|,mid+,r,ll,rr,z);
} Big ask(int x,int l,int r,int y)
{
if (l==r) return tree[x];
int mid=(l+r)>>;
Big more;
if (y<=mid) more=ask(x<<,l,mid,y);
else more=ask(x<<|,mid+,r,y);
if (more.v2<tree[x].v2) return more;
return tree[x];
} int main()
{
rep(i,,maxn-) ln[i]=log(i);
int tt=;
while (scanf("%d %d",&n,&m)!=EOF) {
++tt;
rep(i,,n) {
f[i][]=;
int k;
scanf("%d",&k);
dow(j,,tot)
if (k%pri[j]==) k/=pri[j],f[i][]+=<<j;
}
maxln=floor(ln[n]/ln[])+;
rep(i,,maxln)
rep(j,,n+-(<<i))
f[j][i]=f[j][i-]|f[j+(<<(i-))][i-];
build(,,n);
rep(i,,n) {
int l=i;
now=;
while (l<=n) {
// printf("!!%d %d\n",now,f[l][0]);
now=now|f[l][];
int r=l;
dow(j,,maxln)
if (r-+(<<j)<=n && !(~((~f[r][j])|now)) ) r=r-+(<<j); change(,,n,l-i+,r-i+,calc(now));
l=r+;
}
} while (m--) {
int j;
scanf("%d",&j);
printf("%lld\n",answer(ask(,,n,j)));
}
}
return ;
}
这种区间答案连续的思想并不是第一次遇见了
【倍增】LCM QUERY的更多相关文章
- 刷题总结——Interval query(hdu4343倍增+贪心)
题目: Problem Description This is a very simple question. There are N intervals in number axis, and M ...
- QTREE2 spoj 913. Query on a tree II 经典的倍增思想
QTREE2 经典的倍增思想 题目: 给出一棵树,求: 1.两点之间距离. 2.从节点x到节点y最短路径上第k个节点的编号. 分析: 第一问的话,随便以一个节点为根,求得其他节点到根的距离,然后对于每 ...
- 【HDU 4343】Interval query(倍增)
BUPT2017 wintertraining(15) #8D 题意 给你x轴上的N个线段,M次查询,每次问你[l,r]区间里最多有多少个不相交的线段.(0<N, M<=100000) 限 ...
- [SPOJ913]QTREE2 - Query on a tree II【倍增LCA】
题目描述 [传送门] 题目大意 给一棵树,有两种操作: 求(u,v)路径的距离. 求以u为起点,v为终点的第k的节点. 分析 比较简单的倍增LCA模板题. 首先对于第一问,我们只需要预处理出根节点到各 ...
- HDU4343Interval query 倍增
去博客园看该题解 题意 给定n个区间[a,b),都是左闭右开,有m次询问,每次询问你最多可以从n个区间中选出多少[L,R]的子区间,使得他们互不相交. n,m<=10^5. 区间下标<=1 ...
- SPOJ375 Query on a tree 【倍增,在线】
题目链接[http://www.spoj.com/problems/QTREE/] 题意:给出一个包含N(N<=10000)节点的无根树,有多次询问,询问的方式有两种1.DIST a b 求a ...
- Query on a tree II 倍增LCA
You are given a tree (an undirected acyclic connected graph) with N nodes, and edges numbered 1, 2, ...
- spoj 913 Query on a tree II (倍增lca)
Query on a tree II You are given a tree (an undirected acyclic connected graph) with N nodes, and ed ...
- HDU 4343 Interval query(贪心 + 倍增)
题目链接 2012多校5 Problem D 题意 给定$n$个区间,数字范围在$[0, 10^{9}]$之间,保证左端点严格大于右端点. 然后有$m$个询问,每个询问也为一个区间,数字范围在$[ ...
随机推荐
- mysql主从集群搭建;(集群复制数据)
1.搭建mysql 5.7环境chown mysql:mysql -R /data/groupadd mysqluseradd -g mysql mysql yum install numactlrp ...
- MySQL高级-主从复制
一.复制的基本原理 1.slave会从master读取binlog来进行数据同步 2.步骤+原理图 二.复制的基本原则 1.每个slave只有一个master 2.每个slave只能有一个唯一的服务器 ...
- 你想找的Python资料这里全都有!没有你找不到!史上最全资料合集
你想找的Python资料这里全都有!没有你找不到!史上最全资料合集 2017年11月15日 13:48:53 技术小百科 阅读数:1931 GitHub 上有一个 Awesome - XXX 系列 ...
- 聊聊WS-Federation(test)
本文来自网易云社区 单点登录(Single Sign On),简称为 SSO,目前已经被大家所熟知.简单的说, 就是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统. 举例: 我们 ...
- ToString的格式化字符串
如下: , , ).ToString(@"d\.hh\:mm\:ss"); var b = DateTimeOffset.Now.ToString("yyyy-MM-dd ...
- Solr与Elasticsearch区别
Elasticsearch Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据. 它可以用于全文搜索,结构化搜索以及分析. 优点 Elastics ...
- Java中定时器相关实现的介绍与对比之:Timer和TimerTask
Timer和TimerTask JDK自带,具体的定时任务由TimerTask指定,定时任务的执行调度由Timer设定.Timer和TimerTask均在包java.util里实现. 本文基于java ...
- Python对文本文件逐行扫描,将含有关键字的行存放到另一文件
#逐行统计关键字行数,并将关键字所在行存放在新的文件中 keyword = "INFO" b = open("C:\\Users\\xxx\\Documents\\new ...
- [堆+贪心]牛客练习赛40-B
传送门:牛客练习赛40 题面: 小A手头有 n 份任务,他可以以任意顺序完成这些任务,只有完成当前的任务后,他才能做下一个任务 第 i 个任务需要花费 x_i 的时间,同时完成第 i 个任务的时间不 ...
- hibernate 异常a different object with the same identifier value was already associated with the session
在使用hibernate的时候发现了一个问题,记录一下解决方案. 前提开启了事务和事务间并无commit,进行两次save,第二次的时候爆出下面的异常a different object with t ...