【Flume】数据采集引擎Flume
【Flume】数据采集引擎Flume的更多相关文章
- 带你看懂大数据采集引擎之Flume&采集目录中的日志
一.Flume的介绍: Flume由Cloudera公司开发,是一种提供高可用.高可靠.分布式海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于采集数据:同时,flum ...
- 大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎 采集关系型数据库中的数据 用在离线计算的应用中 强调:批量 (1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS.HBas ...
- Flume数据采集结合etcd作为配置中心在爬虫数据采集处理中的架构实践。
Apache Flume是一个分布式的.可靠的.可用的系统,用于有效地收集. 聚合和将大量日志数据从许多不同的源移动到一个集中的数据存储,但是其本身是以本地properties作为配置的,配置无法做到 ...
- Flume数据采集准备
, flume的官网:http://flume.apache.org/ flume的下载地址:http://flume.apache.org/download.html 这里我们用的是apache版本 ...
- 详解大数据采集引擎之Sqoop&采集oracle数据库中的数据
一.Sqoop的简介: Sqoop是一个数据采集引擎/数据交换引擎,采集关系型数据库(RDBMS)中的数据,主要用于在RDBMS与HDFS/Hive/HBase之间进行数据传递,可以通过sqoop i ...
- Flume官方文档翻译——Flume 1.7.0 User Guide (unreleased version)中一些知识点
Flume官方文档翻译--Flume 1.7.0 User Guide (unreleased version)(一) Flume官方文档翻译--Flume 1.7.0 User Guide (unr ...
- Flume官方文档翻译——Flume 1.7.0 User Guide (unreleased version)(二)
Flume官方文档翻译--Flume 1.7.0 User Guide (unreleased version)(一) Logging raw data(记录原始数据) Logging the raw ...
- 大数据技术之_09_Flume学习_Flume概述+Flume快速入门+Flume企业开发案例+Flume监控之Ganglia+Flume高级之自定义MySQLSource+Flume企业真实面试题(重点)
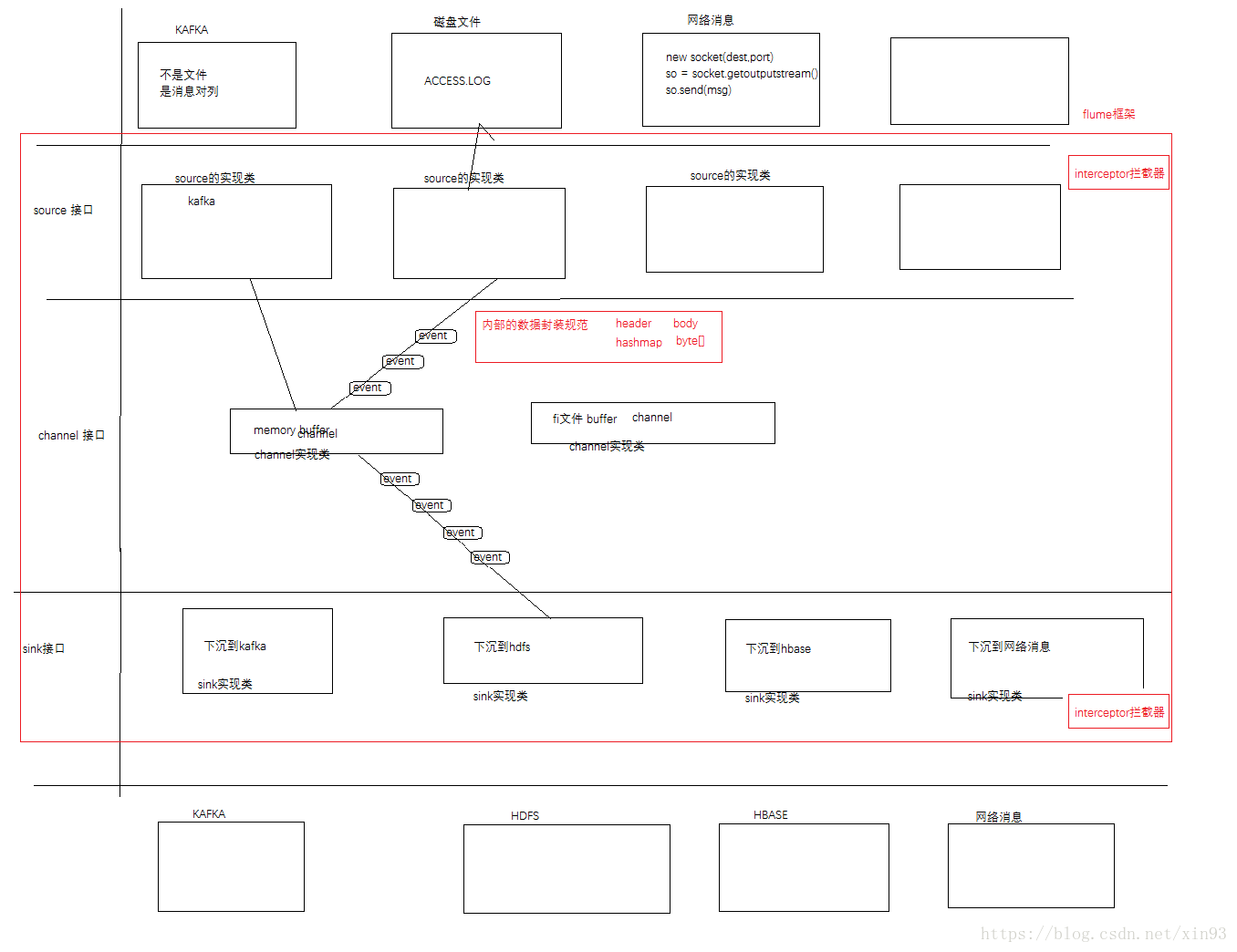
第1章 Flume概述1.1 Flume定义1.2 Flume组成架构1.2.1 Agent1.2.2 Source1.2.3 Channel1.2.4 Sink1.2.5 Event1.3 Flum ...
- Flume OG 与 Flume NG 的对比
Flume OG 与 Flume NG 的对比 1.Flume OG Flume OG:Flume original generation 即Flume 0.9.x版本,它由agent.collect ...
随机推荐
- 理解LSTM/RNN中的Attention机制
转自:http://www.jeyzhang.com/understand-attention-in-rnn.html,感谢分享! 导读 目前采用编码器-解码器 (Encode-Decode) 结构的 ...
- 创建第一个windows服务
windows服务应用程序是一种长期运行在操作系统后台的程序,它对于服务器环境特别适合,它没有用户界面,不会产生任何可视输出,任何用户输出都回被写进windows事件日志. 计算机启动时,服务会自动开 ...
- 爬虫入门之Scrapy框架基础rule与LinkExtractors(十一)
1 parse()方法的工作机制: 1. 因为使用的yield,而不是return.parse函数将会被当做一个生成器使用.scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的 ...
- 允许远程链接mysql,开放3306端口
首先查看端口是否打开 netstat -an|grep 3306 此图为开启3306端口的截图,之前显示为. . . 127.0.0.1:3306 . . . 打开mysql配置文件vi /etc/m ...
- jQuery解决高度统一问题
<div class="itemdl over"> <dl class="fl"> <dt><img src=&quo ...
- 贝叶斯网络(Bayesian network))简介(PRML第8.1节总结)概率图模型(Graphical models)
转:http://www.cnblogs.com/Dzhouqi/p/3204353.html 部分图为手写,由于本人字很丑,望见谅,只是想把PRML书的一些部分总结出来,给有需要的人看,希望能帮到一 ...
- MySQL绿色解压缩版安装与配置
操作步骤: 一.安装MySQL数据库 1.下载MySQL-5.6.17-winx64.zip文件.2.解压到指定目录,本例为D:\mysql-5.6.17-winx64.3.修改配置文件,my-def ...
- 如何在两个月的时间内发表一篇EI/SCI论文-我的时间管理心得
在松松垮垮的三年研究生时期,要说有点像样的成果,也只有我的小论文可以谈谈了.可能有些厉害的角色研究生是丰富而多彩的,而大多数的同学在研究生阶段可能同我一样,是慢悠悠的渡过的,而且可能有的还不如我,我还 ...
- 使用redux开发的简单步骤
一.安装redux包 npm install redux --save 二.根据APP数据结构或者后台请求的数据结构拟定state的大致结构. 可以把state写成一个对象字面量,放在reducer文 ...
- html基值 仿淘宝
$(function(){ var scale = 1 / devicePixelRatio; document.querySelector('meta[name="viewport&quo ...