正排索引(forward index)与倒排索引(inverted index)
正常的索引一般是指关系型数据库里的索引。 把不同的数据存放到不同的字段中。如果要实现baidu或google那种搜索,就需要与一条记录的多个字段进行比对,需要 全表扫描,如果数据量比较大的话,性能就很低。
那反过来,如果把mysql中存放在不同字段中字符串,按一定规则拆分成term【词】存放到 一个字段中【套用mysql中的表结构,实际上不是这样处理的】,然后把这些词存放到一个字段中,并在这个字段建立索引。
这样一来,搜索时,只需要查 带有索引的这列就可以了【这一点和关系型数据库 field_name='xxx'一样了】,这一步解决了效率问题
这个term对应所在记录,中这个term所在的原始记录,这一步解决了获取源内容的问题
正排索引(forward index)与倒排索引(inverted index)
正排索引(前向索引) 正排索引也称为"前向索引"。
正向索引的结构如下:
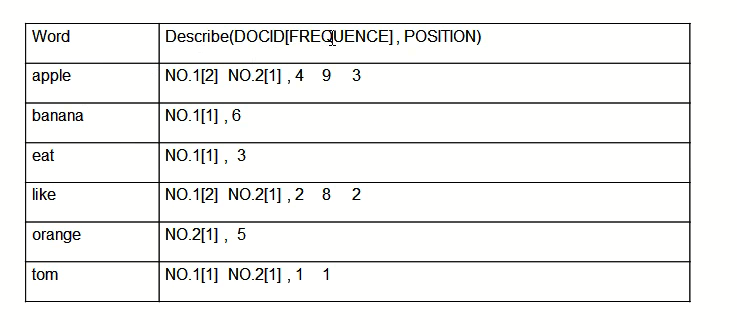
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。

一般是通过key,去找value。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

从词的关键字,去找文档。
官网
https://www.elastic.co/guide/en/elasticsearch/reference/5.x/analysis.html

官网,提供了很多很多。大家自行去看!
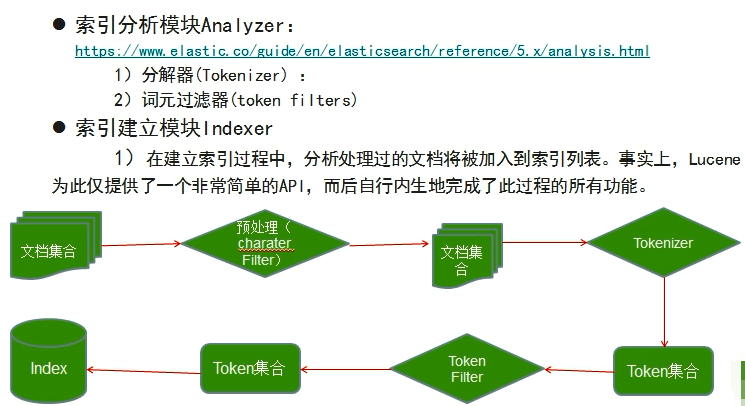
索引分析模块Analyzer
分解器Tokenizer
词元过滤器token filters

经过 Tokenizer

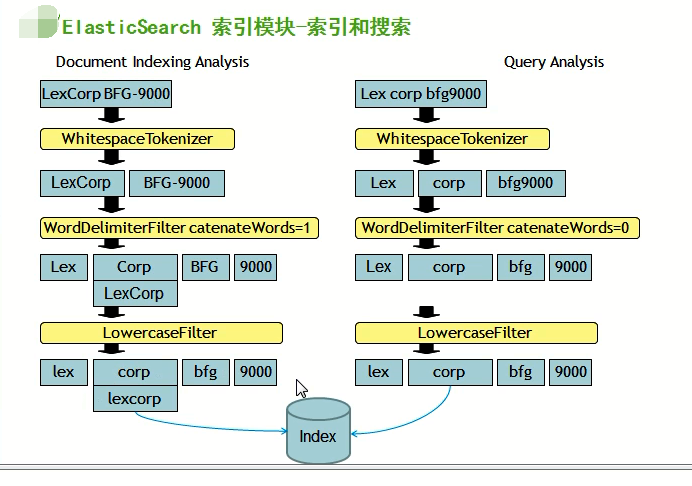

Elasticsearch之IKAnalyzer的过滤停止词
大家,有兴趣,可以看看,英文停用词
http://www.ranks.nl/stopwords
大家,有兴趣,可以看看,中文停用词

Elasticsearch之中文分词器

Elasticsearch之几个重要的分词器
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。 如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!
正排索引(forward index)与倒排索引(inverted index)的更多相关文章
- 正排索引(forward index)与倒排索引(inverted index) (转)
一.正排索引(前向索引) 正排索引也称为"前向索引".它是创建倒排索引的基础,具有以下字段. (1)LocalId字段(表中简称"Lid"):表示一个文档的局部 ...
- 后端程序员之路 35、Index搜索引擎实现分析4-最终的正排索引与倒排索引
# index_box 提供搜索功能的实现- 持有std::vector<ITEM> _buffer; 存储所有文章信息- 持有ForwardIndex _forward_index; ...
- es倒排索引和正排索引
搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values.在建立索引的时候,一方面会建立倒排索引, ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- 16 doc values 【正排索引】
搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values 在建立索引的时候,一方面会建立倒排索引, ...
- 52.基于doc value正排索引的聚合内部原理
主要知识点: 本节没有太懂,以后复习时补上 聚合分析的内部原理是什么????aggs,term,metric avg max,执行一个聚合操作的时候,内部原理是怎样的呢?用了什么样的数据结 ...
- Elasticsearch的索引模块(正排索引、倒排索引、索引分析模块Analyzer、索引和搜索、停用词、中文分词器)
正向索引的结构如下: “文档1”的ID > 单词1:出现次数,出现位置列表:单词2:出现次数,出现位置列表:…………. “文档2”的ID > 此文档出现的关键词列表. 一般是通过key,去 ...
- ElasticSearch(二十一)正排和倒排索引
1.区别 搜索的时候,要依靠倒排索引:排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序,所谓的正排索引,其实就是doc values 在建立索引的时候,一方面会建立 ...
- ES系列七、ES-倒排索引详解
1.单词——文档矩阵 单词-文档矩阵是表达两者之间所具有的一种包含关系的概念模型,图3-1展示了其含义.图3-1的每列代表一个文档,每行代表一个单词,打对勾的位置代表包含关系. 图3-1 单词-文档矩 ...
随机推荐
- Spring MVC 基本配制
WEB.XML 文件中的配制: <?xml version="1.0" encoding="UTF-8"?> <web-app id=&quo ...
- MSSQL Server中partition by与group by的区别
在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by(但此排序顺序优先级是最高的)”的执行. ①group by 列名 合并(列值相同的并作一 ...
- 工作中的Buff加成-结构化思考力:第一章:认识结构化思维及其作用
一:引言 为了更好的说明结构思考力,我们先来做几个小测试. PS:如果你能做到,请留言,因为我要和你交好友,因为你是人才啊,可以挖一挖,挖到我的公司中. 第一个测试:请在三秒内记住下列数字.数字顺序不 ...
- MySQL数据库(二)
1.模糊查询like 在where 后面使用like 通配符: % 任意字符 _ 单个字符 2.order by 排序 order by price //默认升序排序 order by price d ...
- oppo手机永久打开USB调试模式
现象:十分钟不使用就会自动关闭 usb 调试模式,重新打开还得输入验证码,真尼玛烦人. 方法: 数字拨号盘 输入 *#8011# 就可以永久打开.
- pandas筛选数据。
https://jingyan.baidu.com/article/0eb457e508b6d303f0a90572.html 假如我们想要筛选D列数据中大于0的行:df[df['D']>0] ...
- [原创] Linux 中的 nohup 与 &
目录 背景 结论放前面 & nohup nohup + & 测试 直接运行 单独使用 & 单独使用 nohup nohup + & 背景 一直没搞清楚 nohup 与 ...
- 测试sql语句执行速度
DBCC DROPCLEANBUFFERS --清除缓冲区 DBCC FREEPROCCACHE --删除计划高速缓存中的元素 SET STATISTICS io ON SET STATISTICS ...
- iview 怎样屏蔽掉账户框自动显示账户名和密码(root,***)
用iview框架做出的登录页面,账户名和密码显示框,会自动有占位信息(root,****) 后来解决问题发现,只要在真正的输入框下面添加这样的一行隐藏的代码,占位信息会自动填充到隐藏的input框内, ...
- python设计模式--读书笔记
GoF在其设计模式一书中提出了23种设计模式,并将其分为三类: 创建型模式 将对象创建的细节隔离开来,代码与所创建的对象的类型无关. 结构型模式 简化结构,识别类与对象间的关系,重点关注类的继承和组合 ...