pg数据库性能优化(转)
参数修改的方式
1.修改配置文件
在配置文件data目录下postgresql.conf 中直接修改,修改前记得备份一下原文件。修改完成之后,记得重启数据库哦。
2.命令行的修改方式
ALTER SYSTEM SET configuration_parameter { TO | = } { value | 'value' | DEFAULT }
例如:我们现在要修改 maintenance_work_mem参数
show all;
show maintenance_work_mem;
ALTER SYSTEM SET maintenance_work_mem= 1048576;
show maintenance_work_mem;
--注意这里的设置不会改变postgresql.conf,只会改变postgresql.conf
修改参数表
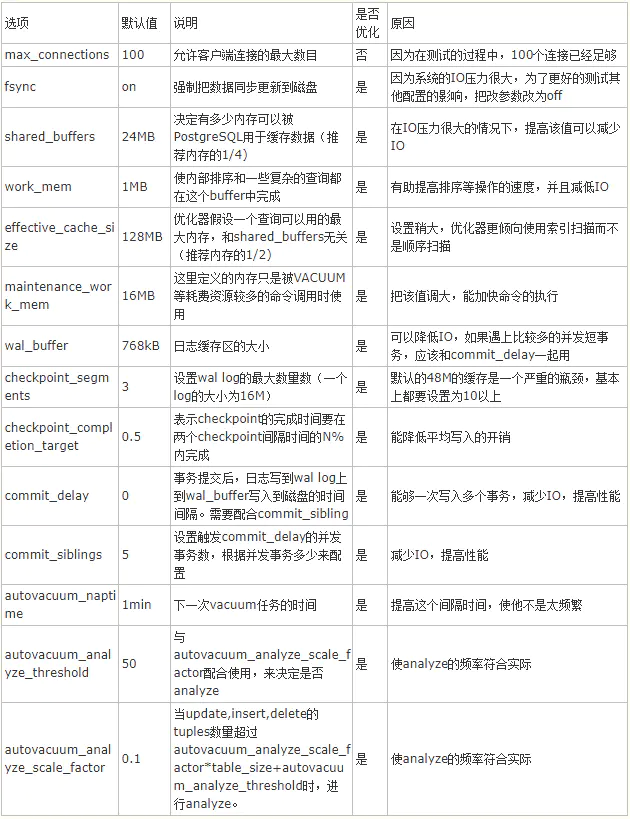
参数详解
1.shared_buffers
PostgreSQL既使用自身的缓冲区,也使用内核缓冲IO。这意味着数据会在内存中存储两次,首先是存入PostgreSQL缓冲区,然后是内核缓冲区。这被称为双重缓冲区处理。对大多数操作系统来说,这个参数是最有效的用于调优的参数。此参数的作用是设置PostgreSQL中用于缓存的专用内存量。
shared_buffers的默认值设置得非常低,因为某些机器和操作系统不支持使用更高的值。但在大多数现代设备中,通常需要增大此参数的值才能获得最佳性能。
建议的设置值为机器总内存大小的25%,但是也可以根据实际情况尝试设置更低和更高的值。实际值取决于机器的具体配置和工作的数据量大小。举个例子,如果工作数据集可以很容易地放入内存中,那么可以增加shared_buffers的值来包含整个数据库,以便整个工作数据集可以保留在缓存中。
在生产环境中,将shared_buffers设置为较大的值通常可以提供非常好的性能,但应当时刻注意找到平衡点。
查看当前shared_buffers的值:
postgres=# show shared_buffers;
shared_buffers
----------------
128MB
(1 row)
2.wal_buffers
PostgreSQL将其WAL(预写日志)记录写入缓冲区,然后将这些缓冲区刷新到磁盘。由wal_buffers定义的缓冲区的默认大小为16MB,但如果有大量并发连接的话,则设置为一个较高的值可以提供更好的性能。
查看当前wal_buffers的值:
postgres=# show wal_buffers;
wal_buffers
-------------
4MB
(1 row)
3.effective_cache_size
effective_cache_size提供可用于磁盘高速缓存的内存量的估计值。它只是一个建议值,而不是确切分配的内存或缓存大小。它不会实际分配内存,而是会告知优化器内核中可用的缓存量。在一个索引的代价估计中,更高的数值会使得索引扫描更可能被使用,更低的数值会使得顺序扫描更可能被使用。在设置这个参数时,还应该考虑PostgreSQL的共享缓冲区以及将被用于PostgreSQL数据文件的内核磁盘缓冲区。默认值是4GB。
查看当前effective_cache_size的值:
postgres=# show effective_cache_size;
effective_cache_size
----------------------
4GB
(1 row)
4.work_mem
此配置用于复合排序。内存中的排序比溢出到磁盘的排序快得多,设置非常高的值可能会导致部署环境出现内存瓶颈,因为此参数是按用户排序操作。如果有多个用户尝试执行排序操作,则系统将为所有用户分配大小为work_mem *总排序操作数的空间。全局设置此参数可能会导致内存使用率过高,因此强烈建议在会话级别修改此参数值。默认值为4MB。
查看当前work_mem的值:
postgres=# show work_mem;
work_mem
----------
4MB
(1 row)
5.maintenance_work_mem
maintenance_work_mem是用于维护任务的内存设置。默认值为64MB。设置较大的值对于VACUUM,RESTORE,CREATE INDEX,ADD FOREIGN KEY和ALTER TABLE等操作的性能提升效果显著。
查看当前maintenance_work_mem的值:
postgres=# show maintenance_work_mem;
maintenance_work_mem
----------------------
64MB
(1 row)
6.synchronous_commit
此参数的作用为在向客户端返回成功状态之前,强制提交等待WAL被写入磁盘。这是性能和可靠性之间的权衡。如果应用程序被设计为性能比可靠性更重要,那么关闭synchronous_commit。这意味着成功状态与保证写入磁盘之间会存在时间差。在服务器崩溃的情况下,即使客户端在提交时收到成功消息,数据也可能丢失。
查看当前synchronous_commit的设置值:
postgres=# show synchronous_commit;
synchronous_commit
--------------------
on
(1 row)
7.checkpoint_timeout和checkpoint_completion_target
PostgreSQL将更改写入WAL。检查点进程将数据刷新到数据文件中。发生CHECKPOINT时完成此操作。这是一项开销很大的操作,整个过程涉及大量的磁盘读/写操作。用户可以在需要时随时发出CHECKPOINT指令,或者通过PostgreSQL的参数checkpoint_timeout和checkpoint_completion_target来自动完成。
checkpoint_timeout参数用于设置WAL检查点之间的时间。将此设置得太低会减少崩溃恢复时间,因为更多数据会写入磁盘,但由于每个检查点都会占用系统资源,因此也会损害性能。此参数只能在postgresql.conf文件中或在服务器命令行上设置。
checkpoint_completion_target指定检查点完成的目标,作为检查点之间总时间的一部分。默认值是 0.5。 这个参数只能在postgresql.conf文件中或在服务器命令行上设置。高频率的检查点可能会影响性能。
查看当前checkpoint_timeout和checkpoint_completion_target的值:
postgres=# show checkpoint_timeout;
checkpoint_timeout
--------------------
5min
(1 row)
postgres=# show checkpoint_completion_target;
checkpoint_completion_target
------------------------------
0.5
(1 row)
注意:
并非所有参数都适用于所有应用程序类型。某些应用程序通过调整参数可以提高性能,有些则不会。必须针对应用程序及操作系统的特定需求来调整数据库参数。
pg数据库性能优化(转)的更多相关文章
- 基于linux(CentOS7)数据库性能优化(Postgresql)
基于CentOS7数据库性能优化(Postgresql) 1. 磁盘 a) Barriers IO i. 通过查看linux是否加载libata,确定是否开 ...
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- mysql数据库性能优化(包括SQL,表结构,索引,缓存)
优化目标减少 IO 次数IO永远是数据库最容易瓶颈的地方,这是由数据库的职责所决定的,大部分数据库操作中超过90%的时间都是 IO 操作所占用的,减少 IO 次数是 SQL 优化中需要第一优先考虑,当 ...
- 数据库性能优化:SQL索引
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
- MySQL 数据库性能优化之索引优化
接着上一篇 MySQL 数据库性能优化之表结构,这是 MySQL数据库性能优化专题 系列的第三篇文章:MySQL 数据库性能优化之索引优化 大家都知道索引对于数据访问的性能有非常关键的作用,都知道索引 ...
- DB2数据库性能优化介绍
DB2数据库性能优化介绍 作者:chszs,转载需注明.博客主页:http://blog.csdn.net/chszs 前段时间,我从CSDN得到了这本书<DB2数据库性能调整和优化(第2版)& ...
- 数据库性能优化一:SQL索引一步到位
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
- 浅谈Oracle数据库性能优化的目标
Oracle性能优化保证了Oracle数据库的健壮性,为了保证Oracle数据库运行在最佳的性能状态下,在信息系统开发之前就应该考虑数据库的优化策略.从数据库性能优化的场景来区分,可以将性能优化分为如 ...
- (转)Db2 数据库性能优化中,十个共性问题及难点的处理经验
(转)https://mp.weixin.qq.com/s?__biz=MjM5NTk0MTM1Mw==&mid=2650629396&idx=1&sn=3ec17927b3d ...
- 基于SSD固态硬盘的数据库性能优化
基于SSD固态硬盘的数据库性能优化 2010-11-08 00:0051cto佚名 关键字:固态硬盘 数据库管理 SSD 企业软件热点文章 Java内存结构与模型结构分析 Oracle触发器的语法 ...
随机推荐
- Servlet 3.0 新特性详解(servlet是单实例多线程的,线程池数量有限)
Servlet 是 Java EE 规范体系的重要组成部分,也是 Java 开发人员必须具备的基础技能,Servlet 3.0 是 Servlet 规范的最新版本.本文主要介绍了 Servlet 3. ...
- pycharm之远程开发
转载:https://amos-x.com/index.php/amos/archives/pycharm-remote/ 前言 远程开发什么意思? 远程开发就是用本地的个人电脑进行代码编写开发,但是 ...
- 使用 wireshark 捕获 请求包
1.出错场景 今天遇到一个问题,在用户登录时,发现用户在登录的时候,一个用户登录正常,一个用户登录报错,报错的原因时400错误,分析对比发现一个用户的分配用户组多,一个分配的少,其中多的那个出错了. ...
- WinForm 开源组件 Realtiizor
Realtiizor 的优势 现代美观的界面设计 Realtiizor 为 WinForm 应用带来了现代感十足的界面风格.它采用了流行的设计理念,如 Material Design 的元素融入,使得 ...
- 物联网CC2530按键单双击分别控制两灯
(1)确定思路单击和双击的效果分别是怎样的(此文章采用简单的延时函数不涉及中断).首先可以定义一个普通延时delay和一个标志位count变量,这里需有个延时阈值咱们直接可以宏定义B值(这里需要注意宏 ...
- PM的正交解调法
1.PM的模拟调制过程 PM信号是一种相位调制信号,其携带的信息保存在其信号的相位中,通过改变载波的相位来实现基带数据的传输. 其函数表达式如下: \[s(t) = A*cos(w_c*t + K ...
- FISCO BCOS 控制台 部署合约 调用 查看已部署合约的地址
deploy 部署合约.(默认提供HelloWorld合约和TableTest.sol进行示例使用) 参数: 合约路径:合约文件的路径,支持相对路径.绝对路径和默认路径三种方式.用户输入为文件名时,从 ...
- 【转载】Spring Cloud Gateway-全局过滤器(Global Filters)
http://www.imooc.com/article/290821 TIPS 本文基于Spring Cloud Gateway SR2,理论适配Spring Cloud Gateway SR1以及 ...
- Supermap Objects API开发中禁用默认的选择集显示风格,启用自定义的显示风格的代码
//#region 使用自定义风格设置选中状态 Selection selection = new Selection();//从该记录集获取选择集 selection.FromRecordset(r ...
- [转]WorldWind开发中WorldWindowGLCanvas .setPreferredSize()函数找不到
值高温假期,无意翻到了csdn中三维GIS开发的专栏,讲的是worldwind Java三维GIS系统开发的东西,十分感兴趣.恰巧要求的环境已经存在,直接耍起来.将最新的Worldwind和JOGL下 ...