Kafka入门实战教程(9):深入了解Offset
1 什么是offset?
Offset,消息位移,它表示分区中每条消息的位置信息,是一个单调递增且不变的值。换句话说,offset可以用来唯一的标识分区中每一条记录。

消费者消费完一条消息记录之后,需要提交offset来告诉Kafka Broker自己消费到哪里了。
2 Offset存在哪里?
Kafka 0.9.0版本以前,这些数值维护在zookeeper中,但是zookeeper并不适合大量写入(涉及网络通讯),因此后来做了改动。
Kafka 0.9.0版本以后,这些数据维护在kafka的_consumer_offsets这个topic下。
_consumer_offsets这个topic中采用了key/value的方式存储数据,key为group.id+topic+分区号,而value则是当前offset的值。每隔一段时间,Kafka内部会对这个topic进行compact,也就是每个group.id+topic+分区号就保留最新数据。
3 提交offset的方式
自动提交offset
Kafka为了使我们能够专注于自己的业务逻辑,提供了自动提交offset的功能,这也是默认配置项。
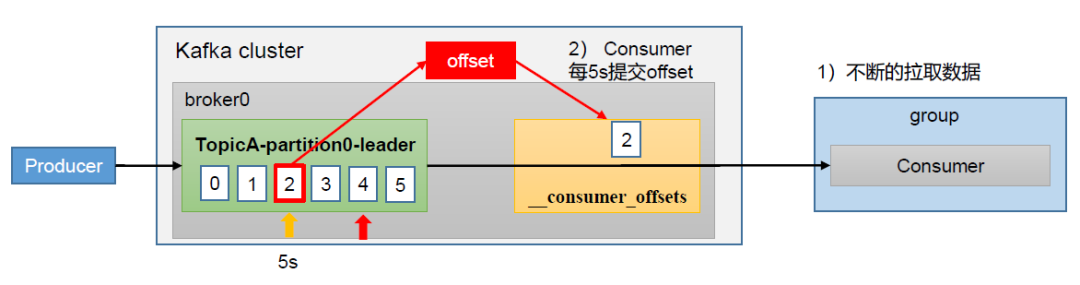
我们需要关注以下两个配置参数:
enable.auto.commit:是否开启自动提交offset功能,默认是true
auto.commit.interval.ms:自动提交offset的时间间隔,默认是5s
在Confluent.Kafka中如下配置即可:
var config = new ConsumerConfig
{
......
EnableAutoCommit = true, // 开启AutoCommit,默认为true,因此可以不显示配置
AutoCommitIntervalMs = 3000, // 自动提交offset的时间间隔,默认为5s
};
手动提交offset
虽然自动提交offset带来了很大的便利,但是在消息的可靠性上不太容易掌控,因此Kafka也提供了手动提交offset这个功能。
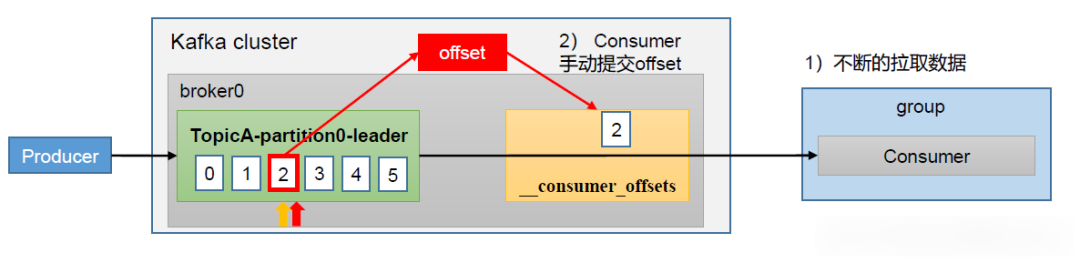
在Confluent.Kafka中可以这样设置:
var config = new ConsumerConfig
{
...
// Disable auto-committing of offsets.
EnableAutoCommit = false
} ... while (!cancelled)
{
var consumeResult = consumer.Consume(cancellationToken); // process message here. if (consumeResult.Offset % commitPeriod == 0)
{
try
{
consumer.Commit(consumeResult);
}
catch (KafkaException e)
{
Console.WriteLine($"Commit error: {e.Error.Reason}");
}
}
}
但是需要注意的是,使用Commit方法提交位移会产生阻塞,影响吞吐量。
在Confluent.Kafka中还提供了一种不产生阻塞的方式:Store Offsets。它的原理是允许Kafka在后台线程帮我们自动提交,但是offset的偏移量更新由我们手动来控制,兼顾了性能与可靠性,示例代码如下:
var config = new ConsumerConfig
{
...
EnableAutoCommit = true // (the default)
EnableAutoOffsetStore = false
} ... while (!cancelled)
{
var consumeResult = consumer.Consume(cancellationToken); // process message here. consumer.StoreOffset(consumeResult);
}
4 指定offset消费方式
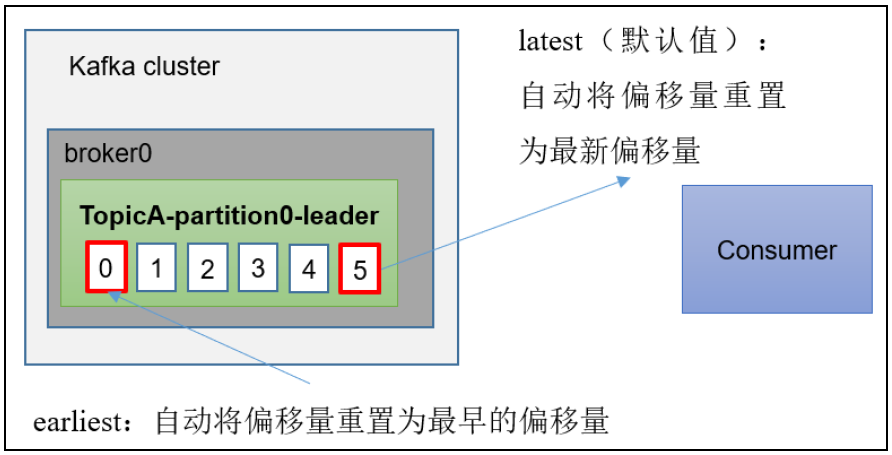
三种主要方式
Kafka针对offset的消费方式提供了三种类型:earliest | latest | none,默认是latest,即从最新的offset开始消费。
(1)earliest:自动将偏移量 重置为最早的,--fromfromfrom。
(2)latest(默认值):自动将偏移量重置为最新偏移量。
(3)none :如果未找到消费者组的先前偏移量,则向抛出异常。
在Confluent.Kafka中,Consumer可以进行如下配置:
var config = new ConsumerConfig
{
...
AutoOffsetReset = AutoOffsetReset.Earliest // 从最早的开始消费起
AutoOffsetReset = AutoOffsetReset.Latest // 从最新的开始消费起
AutoOffsetReset = AutoOffsetReset.Error // 如果未找到消费组的先前偏移量,则抛出错误异常
}
指定时间消费
在实际场景下,可能会遇到最近消费的几个小时数据异常,需要重新按照某个时间进行消费,比如:要求按照时间消费前一天的消息记录。
因此,我们可以通过下面的工具脚本将消费者组的位移进行重置:
bin/kafka-consumer-groups.sh --bootstrap-server kafka1:9092,kafka2:9092,kakfa3:9092 --group test-group --reset-offsets --to-datetime 2022-07-07T20:00:00.000 --execute
由于Confluent.Kafka组件并未提供这个功能,所以建议使用工具脚本进行按日期重设offset。
5 漏消费与重复消费
漏消费
在Consumer的消费逻辑中,如果先提交了offset后消费,有可能出现数据的漏消费。
例如,在某个场景中,我们设置了offset为手动提交,当offset被提交时,数据还在内存中未落盘,此时刚好消费者线程被kill掉了,那么offset已经提交,但是数据尚未进行真正的处理,导致这部分内存中的数据丢失。
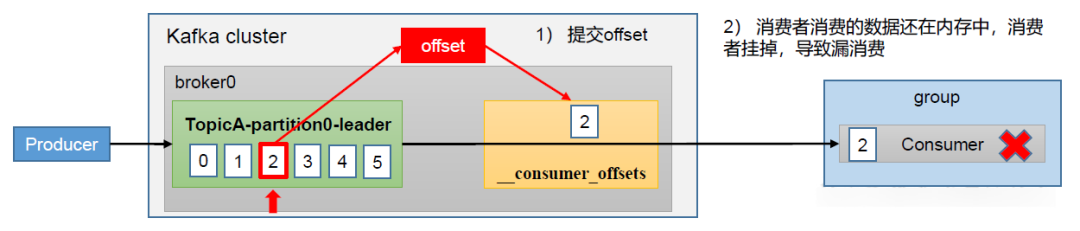
解决办法就是:先消费后再提交offset。
重复消费
如果开启了自动提交offset,在某些场景下,如果在提交后的某个时间(该时间尚未达到自动提交的时间间隔如5s)时Consumer挂了,可能会导致Consumer重启后从上一次成功提交的offset处继续消费,从而出现重复消费。
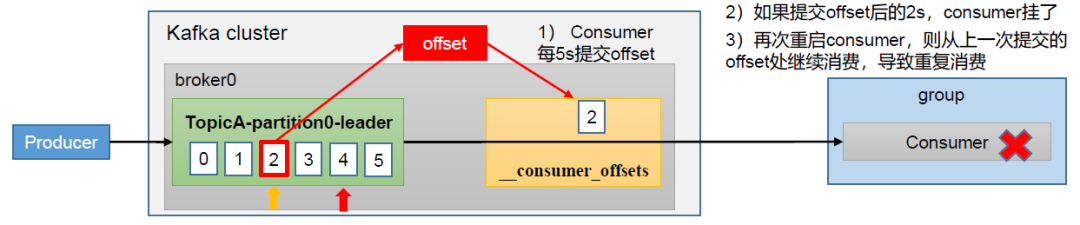
解决办法就是:关闭自动提交,手动提交offset。但仍然存在会重复消费的可能性,因此消费者端还是需要进行保证幂等性的处理。
例如,我们可以通过使用具有事务数据存储的IMessageTracker来跟踪消息ID,那么消费端的代码可能长下面这样子(该示例基于CAP组件做示例代码):
readonly IMessageTracker _messageTracker; public SomeMessageHandler(IMessageTracker messageTracker)
{
_messageTracker = messageTracker;
} [CapSubscribe]
public async Task Handle(SomeMessage message)
{
if (await _messageTracker.HasProcessed(message.Id))
{
return;
} // do the work here
// ... // remember that this message has been processed
await _messageTracker.MarkAsProcessed(messageId);
}
至于 IMessageTracker 的实现,可以使用诸如Redis或者数据库等存储消息Id和对应的处理状态。
6 消费数据积压
消息数据积压恐怕是比较常见的线上问题了,一般来说,Kafka数据积压问题需要分成两个维度来分析。
Kafka消费能力不足
如果是Kafka消费能力不足,可以考虑给Kafka增加Topic的分区数,并同步增加消费者Consumer的实例数,谨记:分区数=消费者数(二者缺一不可)。
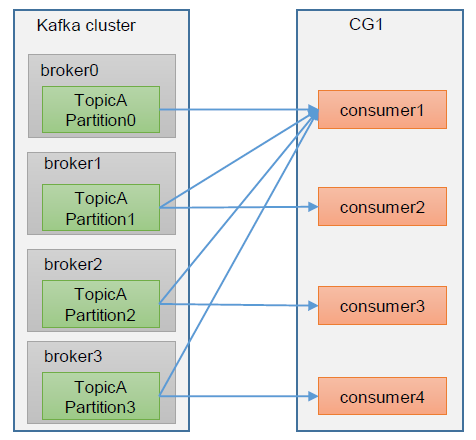
bin/kafka-topics.sh --bootstrap-server kafka1:9092,kafka2:9092,kafka3:9092 --alter --topic test --partitions 5
注意:分区数可以增加,但是不能减少!
Consumer数据处理不及时
如果是Consumer的数据处理不够及时,那么可以考虑提高每批次拉取的数量。如果批次拉取数据过少(拉取数据时间/处理时间 < 生产速度),当处理的数据小于生产的数据时,也会产生数据积压。
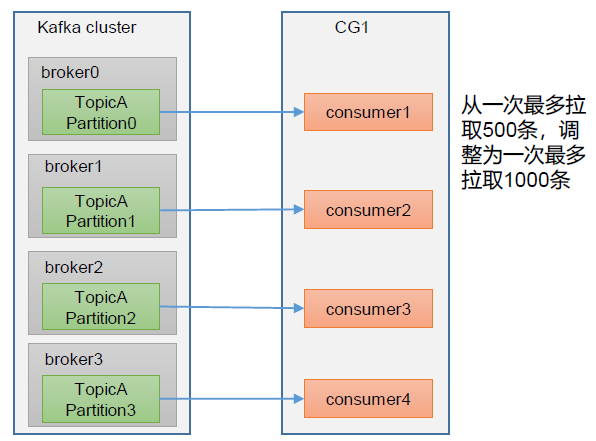
对应的Consumer端参数解释如下:

需要注意的是,如果单纯只扩大一次poll拉取数据的最大条数,可能它会收到消息最大字节数的限制,因此最好是同时更新两个参数的值。
7 总结
本文总结了offset的基础概念、存储位置、消费方式,扩展了两个常见问题:漏消费与重复消费,引出了一个消费数据积压问题,希望能对你有所帮助!
参考资料
极客时间,胡夕《Kafka核心技术与实战》
B站,尚硅谷《Kafka 3.x入门到精通教程》

Kafka入门实战教程(9):深入了解Offset的更多相关文章
- Kafka入门实战教程(7):Kafka Streams
1 关于流处理 流处理平台(Streaming Systems)是处理无限数据集(Unbounded Dataset)的数据处理引擎,而流处理是与批处理(Batch Processing)相对应的.所 ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- Kafka入门经典教程
本帖最后由 desehawk 于 2015-5-3 00:45 编辑问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程 ...
- Kafka入门经典教程【转】
问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程序?4.数据传输的事务定义有哪三种?5.Kafka判断一个节点是否活着有 ...
- [入门帮助] Kafka入门经典教程
问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic.发送消息.消费消息?3.如何书写Kafka程序?4.数据传输的事务定义有哪三种?5.Kafka判断一个节点是否活着有 ...
- ZooKeeper入门实战教程(一)-介绍与核心概念
1.ZooKeeper介绍与核心概念1.1 简介ZooKeeper最为主要的使用场景,是作为分布式系统的分布式协同服务.在学习zookeeper之前,先要对分布式系统的概念有所了解,否则你将完全不知道 ...
- 《OD大数据实战》Kafka入门实例
官网: 参考文档: Kafka入门经典教程 Kafka工作原理详解 一.安装zookeeper 1. 下载zookeeper-3.4.5-cdh5.3.6.tar.gz 下载地址为: http://a ...
- Kafka入门教程(二)
转自:https://blog.csdn.net/yuan_xw/article/details/79188061 Kafka集群环境安装 相关下载 JDK要求1.8版本以上. JDK安装教程:htt ...
- mybatis实战教程(mybatis in action),mybatis入门到精通
转自:http://www.yihaomen.com/article/java/302.htm (读者注:其实这个应该叫做很基础的入门一下下,如果你看过hibernate了那这个就非常的简单) (再加 ...
- mybatis实战教程(mybatis in action),mybatis入门到精通(转)
转自:http://www.yihaomen.com/article/java/302.htm (读者注:其实这个应该叫做很基础的入门一下下,如果你看过Hibernate了那这个就非常的简单) (再加 ...
随机推荐
- 面试题-Athas性能监控工具(原理部分未完成)
前言 Arthas工具已经被我们项目组简单的应用到了物流项目的日常运维中.物流项目之前出现过生产消费速度不一致导致内存队列中的消息数据积压的问题,在后来解决了问题之后,我们项目组就更加重视了对JVM的 ...
- 适配器设计模式--java进阶day03
1.设计模式 通俗来讲,设计模式就是其他程序员遇到某些问题时的解决经验,我们学习设计模式,在遇到了同样的问题后便可解决 2.适配器设计模式 有人可能会感到疑惑,接口和实现类会有什么问题,我们举两个例子 ...
- C# LINQ 快速入门实战指南,建议收藏学习!
前言 因为咱们的.NET EF Core快速入门实战教程经常会用到 LINQ 去查询和操作 MySQL 中的数据,因此我觉得很有必要对 LINQ 的一些使用技巧.常用方法.特性做一个详细的介绍,让大家 ...
- Asp.net mvc基础(十一)数据验证
1.获取验证失败错误 asp.net mvc会自动根据属性的类型进行基本的校验,但Asp.net mvc并不是在请求验证失败的时候抛异常,而是把决定权交给开发人员,开发人员需要决定如何处理数据校验失败 ...
- 如何使用 MySQL 的 EXPLAIN 语句进行查询分析?
如何使用 MySQL 的 EXPLAIN 语句进行查询分析? EXPLAIN 是 MySQL 提供的分析 SQL 查询执行计划的工具,用于了解查询语句的执行过程,帮助优化查询性能. 1. EXPLAI ...
- MySQL 中如果发生死锁应该如何解决?
MySQL 中如果发生死锁应该如何解决? 死锁是指多个事务在执行过程中因资源争用形成的循环等待,导致无法继续执行.MySQL 会自动检测死锁并选择一个事务进行回滚,但我们可以通过优化设计和操作来避免和 ...
- 一文速通Python并行计算:09 Python多进程编程-进程之间的数据同步-基于互斥锁、递归锁、信号量、条件变量、事件和屏障
一文速通 Python 并行计算:09 Python 多进程编程-进程之间的数据同步-基于互斥锁.递归锁.信号量.条件变量.事件和屏障 摘要: 多进程同步机制包括互斥锁.递归锁.信号量.条件变量.事件 ...
- 『Plotly实战指南』--样式定制基础篇
在数据可视化的世界中,一个精心设计的图表不仅能准确传达信息,还能提升整体的专业性和吸引力. 而Plotly作为Python中强大的可视化库,提供了丰富的样式定制功能,帮助我们轻松实现这一目标. 本文从 ...
- Sentinel——pull模式规则持久化
目录 pull模式规则持久化 定义数据源 定义SPI接口文件 测试 pull模式规则持久化 pull 模式的数据源(如本地文件.RDBMS 等)一般是可写入的.使用时需要在客户端注册数据源:将对应的读 ...
- Win 下 创建 Python 虚拟环境
主要是记录一个 用虚拟环境打包的坑, Virtualenv 不如自带的 venv 香. 需求 最近要对一个 tkinter 小程序打包为 exe. 毕竟业务人员是绝对不可能安装开发环境的. 不论你怎么 ...