Java源码分析系列笔记-1.JMM模型之先谈硬件
要理解JMM,我们先要理解底层硬件的工作原理
1. 冯诺依曼体系结构
冯诺依曼提出将程序当作数据对待,将程序(指令)和数据用同样的方式储存。根据这个理论计算机被分成控制器、运算器、存储器、输出设备、输入设备这几个部件,如下图
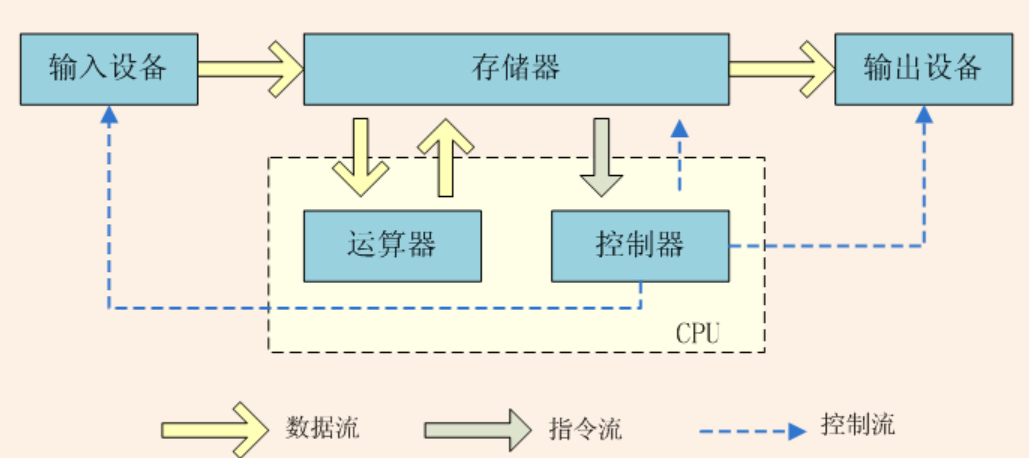
其中运算器和控制器组合成了CPU,CPU执行指令或者操作数据的时候都要跟存储器交互,而CPU和存储器的速度差异是巨大的,为了弥补这个鸿沟,计算机科学家们在CPU和主内存之间引入了高速缓存
2. 高速缓存
引入了高速缓存后,CPU和存储器之间的结构如下图
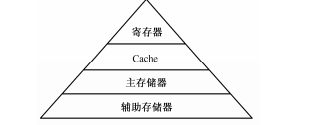
2.1. 工作原理
有了高速缓存后,CPU取数据先从寄存器中取,没有则去cache中取,还没有则去主存储器中取,再没有则去辅助存储器中取。
如果这个数据是在辅助存储器中,那么他会把这个数据就会存入主存储器,再存入cache,最后存入寄存器。
因此可以这么说,寄存器是cache的缓存,cache是主存储器的缓存,主存储器是辅助存储器的缓存,这个就叫做存储器层次结构
2.2. 存储器层次结构
越往顶部,越靠近CPU,存储器的速度更快、容量更小、价格更贵
我们可以把最经常访问的数据放在最顶部,这样子CPU可以很快的速度取出数据进行计算
那么怎么判断哪些数据是最经常访问的数据呢?这就要引入局部性原理
2.3. 局部性原理
局部性原理分成时间和空间两部分,
时间局部性:被引用过的存储器位置可能会被再次引用
空间局部性:被引用过的存储器位置附近的数据很有可能将被引用
根据这个原理,CPU会把这次访问的数据及其附近的数据都存入缓存层,以便下一次快速访问
引入缓存缓存后,虽然CPU访问存储器的速度提高了,但是却出现了缓存一致性的问题。
3. 缓存一致性/可见性问题
现在的CPU都是多核处理器,如果多线程并发访问同一个数据,那么这个数据在每个处理器的缓存层都有一个副本,处理器1更新了这个数据后,处理器2何时才能知道这个更新呢?这个就是缓存一致性的问题:当前的处理器无法及时看到其他处理器写入到内存的数据
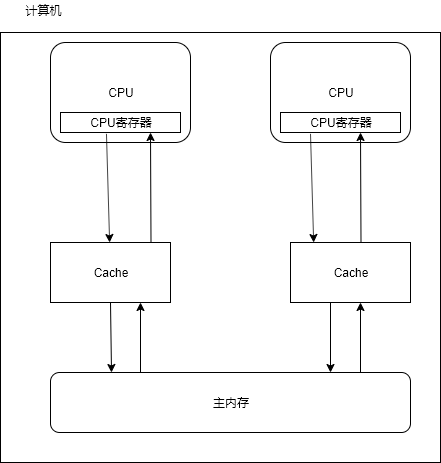
3.1. 如何解决
3.1.1. 总线加锁
处理器从主内存读取数据到高速缓存,会在总线对这个数据加锁。直到这个处理器操作完,其他处理器无法读写这个数据。
因此这种方案的缺点在于性能太低,一个处理器在读的时候,不允许其他处理器的任何操作。而读操作其实是可以并发执行的,因此引入了MESI缓存一致性协议
3.1.2. MESI缓存一致性协议
多个处理器可以同时从主内存读取数据到高速缓存中。
当某个处理器修改了缓存的数据后,会同步会回主内存。
其他处理器通过总线嗅探感知到数据已经变化,会让缓存中的数据失效
接下来我们看另一个问题:有序性
4. CPU流水线技术
CPU执行指令可以大致分为取指、译码、计算、访问存储器、写回寄存器等几个步骤。我们可以模拟工厂流水线的工作,第一条指令执行到译码的阶段时,可以同时执行第二条执行的取指阶段,提高吞吐量,如下图
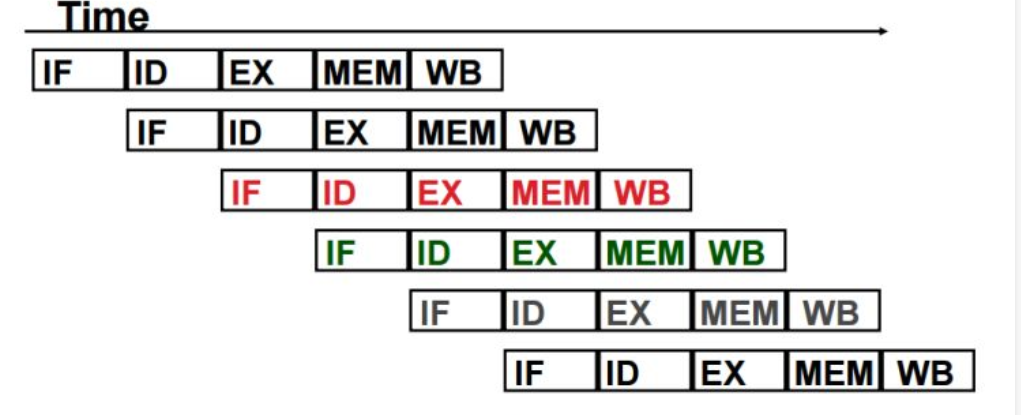
我们看看百度百科对CPU流水线技术的解释:
CPU流水线技术并没有加速单条指令的执行,每条指令的操作步骤一个也不能少,只是多条指令的不同操作步骤同时执行,因而从总体上看加快了指令流速度,缩短了程序执行时间。
4.1. 乱序执行/重排序
为了更好地适配CPU流水线技术,程序里面的每行代码的执行顺序,有可能会被编译器和CPU根据某种策略,给打乱掉,从而让指令的执行能够尽可能的并行起来。这就叫乱序执行/重排序。
重排序分为处理器重排序和编译器重排序两种。
5. 重排序/有序性问题
由于现在的CPU都是多核的,且引入了缓存层,这就导致逻辑次序上后写入内存的数据未必真的最后写入。换句话说,多核CPU的情况下重排序可能会导致最后得到的不是预期的结果。
5.1. 如何解决
5.1.1. 使用内存屏障禁止乱序执行
不同架构的处理器在其指令集中提供了不同的指令来发起内存屏障,使用了内存屏障指令后可以禁止指令重排序。
内存屏障对应在编程语言当中就是提供特殊的关键字来调用处理器相关的指令(如Java中的volatile关键字)
5.1.1.1. 内存屏障的类型
如下,Store就是将处理器缓存中的数据刷新到内存中【写】,而Load则是从内存拷贝数据到缓存当中【读】
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1;LoadLoad;Load2 | 确保Load1不能重排序到Load2之后 |
| StoreStore Barriers | Store1;StoreStore;Store2 | 确保Store1不能重排序到Store2之后 |
| LoadStore Barriers | Load1;LoadStore;Store2 | 确保Load1不能重排序到Store2之后 |
| StoreLoad Barriers | Store1;StoreLoad;Load1 | 确保Store1不能重排序到Load1之后 |
其中LoadStore+StoreStore叫释放屏障;LoadLoad+LoadStore叫获取屏障
6. 内存一致性模型
6.1. 什么是内存一致性模型
百度百科的解释如下:
本质上是软件与存储器之间的协约问题。如果软件遵守约定的规则,存储器就能正常工作;反之,存储器就不能保证操作的正确性
内存一致性模型只是一个标准,它规定了程序的内存操作(读操作和写操作)所有可能的执行顺序中哪些是正确的(不正确则会出现可见性、有序性、原子性等问题)。
而既然内存一致性模型只是一个标准,那么不同的处理器架构肯定对他有不同的实现。但是不管怎么说,只要实现了内存一致性模型,那么他就解决了可见性、有序性、原子性等问题。
6.2. 分类
6.2.1. 顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证
6.2.1.1. 两大特性
- 一个线程中的所有操作必须按照程序的顺序来执行。
- (不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
7. 参考
- 谈乱序执行和内存屏障_乱序执行,指令重排,内存屏障_Floating Cat-CSDN博客
- cpu流水线_百度百科
- 如何理解计算机操作系统中的局部性原理? - 知乎
- 为什么CPU流水线设计的级越长,完成一条指令的速度就越快? - 知乎
- 内存一致性模型_百度百科
- 内存一致性模型 - 维基百科,自由的百科全书
- Memory model (programming) - Wikipedia
Java源码分析系列笔记-1.JMM模型之先谈硬件的更多相关文章
- Java源码分析系列之HttpServletRequest源码分析
从源码当中 我们可以 得知,HttpServletRequest其实 实际上 并 不是一个类,它只是一个标准,一个 接口而已,它的 父类是ServletRequest. 认证方式 public int ...
- Java源码分析系列
1) 深入Java集合学习系列:HashMap的实现原理 2) 深入Java集合学习系列:LinkedHashMap的实现原理 3) 深入Java集合学习系列:HashSet的实现原理 4) 深入Ja ...
- MyCat源码分析系列之——结果合并
更多MyCat源码分析,请戳MyCat源码分析系列 结果合并 在SQL下发流程和前后端验证流程中介绍过,通过用户验证的后端连接绑定的NIOHandler是MySQLConnectionHandler实 ...
- MyCat源码分析系列之——BufferPool与缓存机制
更多MyCat源码分析,请戳MyCat源码分析系列 BufferPool MyCat的缓冲区采用的是java.nio.ByteBuffer,由BufferPool类统一管理,相关的设置在SystemC ...
- [Tomcat 源码分析系列] (二) : Tomcat 启动脚本-catalina.bat
概述 Tomcat 的三个最重要的启动脚本: startup.bat catalina.bat setclasspath.bat 上一篇咱们分析了 startup.bat 脚本 这一篇咱们来分析 ca ...
- MyBatis 源码分析系列文章导读
1.本文速览 本篇文章是我为接下来的 MyBatis 源码分析系列文章写的一个导读文章.本篇文章从 MyBatis 是什么(what),为什么要使用(why),以及如何使用(how)等三个角度进行了说 ...
- spring源码分析系列 (8) FactoryBean工厂类机制
更多文章点击--spring源码分析系列 1.FactoryBean设计目的以及使用 2.FactoryBean工厂类机制运行机制分析 1.FactoryBean设计目的以及使用 FactoryBea ...
- spring源码分析系列 (5) spring BeanFactoryPostProcessor拓展类PropertyPlaceholderConfigurer、PropertySourcesPlaceholderConfigurer解析
更多文章点击--spring源码分析系列 主要分析内容: 1.拓展类简述: 拓展类使用demo和自定义替换符号 2.继承图UML解析和源码分析 (源码基于spring 5.1.3.RELEASE分析) ...
- spring源码分析系列 (1) spring拓展接口BeanFactoryPostProcessor、BeanDefinitionRegistryPostProcessor
更多文章点击--spring源码分析系列 主要分析内容: 一.BeanFactoryPostProcessor.BeanDefinitionRegistryPostProcessor简述与demo示例 ...
- spring源码分析系列 (3) spring拓展接口InstantiationAwareBeanPostProcessor
更多文章点击--spring源码分析系列 主要分析内容: 一.InstantiationAwareBeanPostProcessor简述与demo示例 二.InstantiationAwareBean ...
随机推荐
- 客户端“自废武功”背后的深层秘密——CORS跨域是怎么回事?
客户端"自废武功"背后的深层秘密--CORS跨域是怎么回事? 嘿,对于刚入门的开发新手,你是不是曾经遇到过这样的情况:你正在愉快地开发一个 Web 应用,代码写得热火朝天,前后端配 ...
- MySQL-InnoDB行锁
InnoDB的锁类型 InnoDB存储引擎支持行锁,锁类型有两种: 共享锁(S锁) 排他锁(X锁) S和S不互斥,其他均互斥. 除了这两种锁以外,innodb还支持一种锁,叫做意向锁. 那么什么是意向 ...
- git库移植
记一次个人项目移植到组织项目的git应用,留爪. 1. 首先保证你本地有一份完整的库 2. 在 gitee 组织里新建一份裸库 3. 本地库移除所有远程库 git remote //查看所有远程库 g ...
- frameset frame 实例和用法
转
看这个比较好
- openGL库环境简单配置
主要是针对openGL的一些初步的学习,因为openCV主要是处理图像视频,是从现有的得到数据,而openGL好像是从数据进行绘图,学习一下.在<计算机图形学编程>一书中,它把图形编程定性 ...
- springboot将vo生成文件到目录
依赖 org.springframework spring-mock 2.0.8 com.alibaba fastjson 1.2.62 service实现 public RestResponseBo ...
- 多线程,Join()
一.定义:就是该线程是指的主线程等待子线程的终止.也就是在子线程调用了join()方法,后面的代码,只有等到子线程结束了才能执行 二.不加join: class Thread1 extends Thr ...
- php 微信小程序转义403
function code 微信 iv 偶现 encryptedData 41003 encodeURIComponent 关于小程序微信授权登录提示41003 文章简介 原因一(iv和encrypt ...
- centos安装npm和 nodejs
NPM安装 00X01:创建目录 mkdir /usr/local/node/ cd /usr/local/node/ 00x02:下载安装包 wget https://npm.taobao.org/ ...
- WPF 解决PasswordBox 属性Password无法绑定到后台的问题
在 WPF 中,你可以使用密码框的 Password 属性来绑定到后台,但是由于安全性考虑,WPF 的密码框不直接支持双向绑定.然而,你仍然可以通过其他方式实现将密码框的内容绑定到后台. 一种常见的方 ...