2条流程解决数据同步到全球部署的N个数据库
1、数据同步需求
自动识别源表中数据所归属的分公司进行自动同步,即将源表中A分公司的数据同步到A公司数据库表,源表中B分公司的数据同步到B公司数据库表,以此类推。
2、实现思路
- 一般ETL工具实现思路:建立同步到A分公司流程,抽取源表数据->过滤出A分公司->将过滤后的数据加载到A公司数据库表。再建立同步到B分公司流程,有多少个分公司就建立多少条流程。

缺点:开发工作量随分公司数量成正比,当所有表存在变更时需要对所有流程进行修改,日常运行监控、维护困难。
优点:当某个分公司数据库表有变更时,只需要维护对应的流程,不影响其他流程。
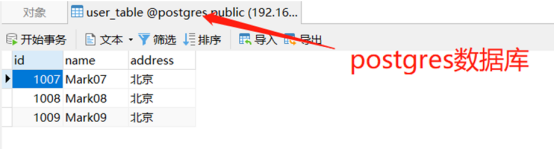
- Restcloud ETL工具实现思路:创建1个主流程、1个子流程,主流程用于获取需要同步的分公司并作为变量参数,并逐个输出给子流程。子流程获取主流程的变量参数作为数据过滤条件及动态获取对应目标数据源。
主流程工作原理:通过执行SQL脚本做Groupby分组计算出要同步的分公司并作为变量参数,利用【逐行拆分输出组件】控制循环调用子流程,逐个将变量参数传送给子流程。

创建1个子流程,获取主流程输出数据作为参数条件抽取需要同步的数据,及需要调取的数据源。

缺点:存在一定限制,如要求所有分公司的表名称、表结构相同。
优点:工作量小,日常运行监控、维护便捷。
3、示例
3.1 建立主流程
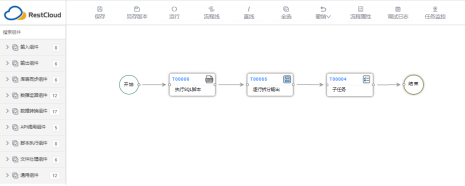
3.1.1配置【执行SQL脚本】组件
配置基本属性:指定读取源表的数据源
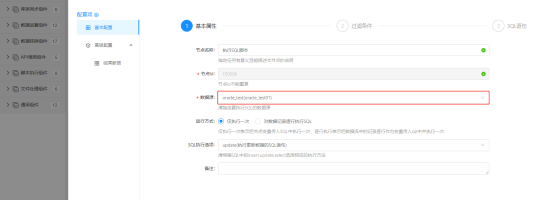
配置过滤条件:此处无需过滤数据,下一步跳过该项配置
配置SQL语句:编写SQL已经做Groupby分组计算出要同步的分公司并作为变量参数。
如果有存储分公司名单与数据源对应代码表,此处可以直接用【表输入】组件获取
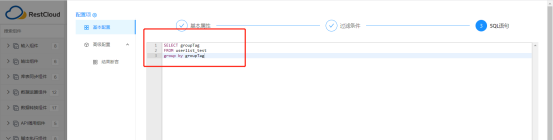
保存退出,完成【执行SQL脚本】配置。
3.1.2配置【逐行拆分输出】组件
3.1.3配置【子任务】组件
选择已配置后的子流程,选择数据流入(接收主流程输出数据)
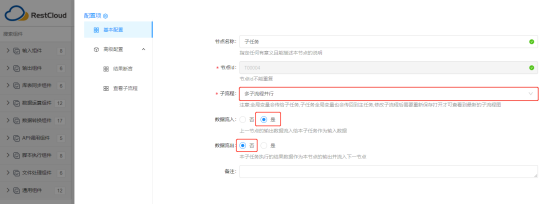
3.2 建立子流程
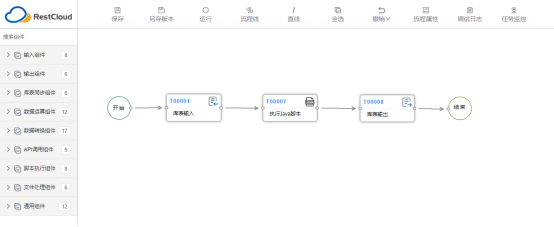
3.2.1 配置【库表输入】
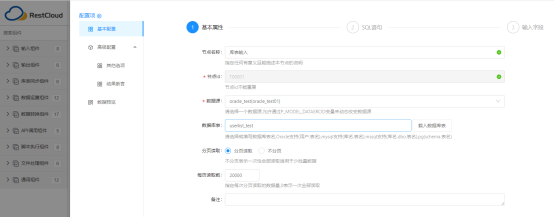
配置基本属性:指定读取源表的数据源
配置SQL语句:增加数据过滤条件参数
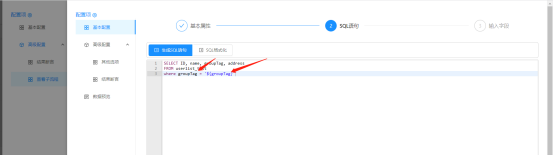
配置输入字段:系统自动读取,无需配置。直接点击保存退出完成【库表输入】组件配置。
3.2.2 配置【执行Java脚本】
配置基本属性:无需修改配置,直接下一步。
配置Java代码:代码逻辑(通过判断输入的参数值获取对应同步的目标数据源)
如输入参数A,对应同步到数据源“Stephen_MySql01”, Stephen_MySql01为配置A公司的的数据源名称。
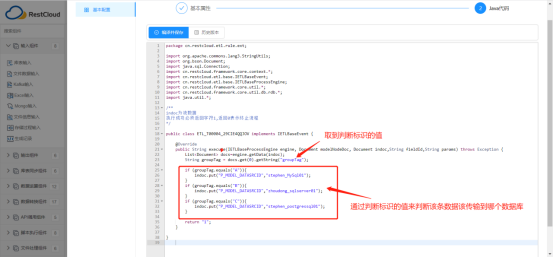
直接点击编译并保存,退出完成【执行Java脚本】组件配置
3.2.3 配置【库表输出】
配置基本属性:指定读取源表的数据源(此处根据参数动态获取指定输出数据源)
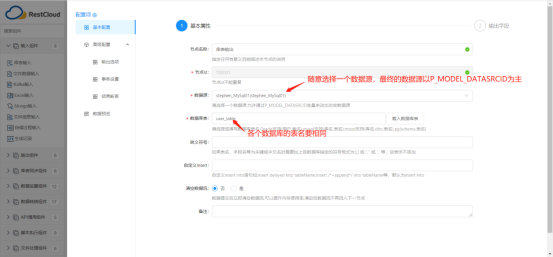
配置输出字段:根据目标表的字段情况,手工点击新增列完成输出字段配置。
由于数据源是动态原因,流程在不运行情况下无法获取到对应表,因此无法自动获取表结构。
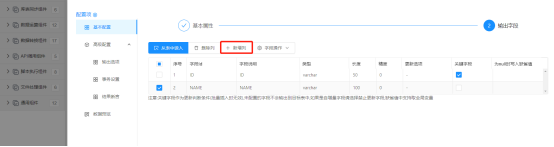
输出字段配置完成后,点击保存完成【库表输出】配置。
3.3 测试
3.3.1用例数据
源表数据如下:
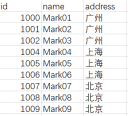
3.3.2效果要求:
address 为“广州”的数据同步到mysql数据库
address 为“上海”的数据同步到SQL serve数据库
address 为“北京”的数据同步到Postgres数据库
3.3.3运行结果
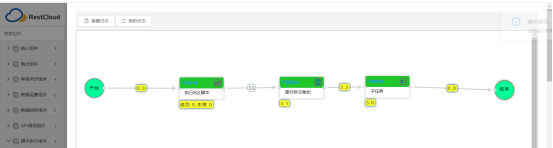
数据库结果
标识为“广州”的,就将该条数据插入到mysql数据库
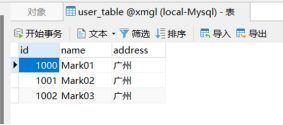
标识为“上海”的,就将该条数据插入到SQL server数据库
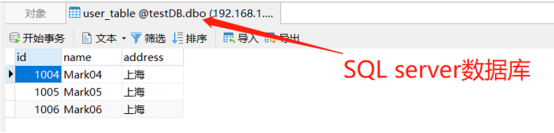
标识为“北京”的,就将该条数据插入到postgres数据库

2条流程解决数据同步到全球部署的N个数据库的更多相关文章
- C#多线程lock解决数据同步
1.代码实例: public class ThreadTest4 { public static void Init() { //多个线程修改同一个值,使用lock锁解决并发 ; i < ; i ...
- Spanner:谷歌新一代全球部署的列式数据库
Spanner 是一个可扩展的.全球分布式的数据库,提供分布式ACID. 架构 universe:一个部署的实例成为universe,目前谷歌有3个,分别为开发/测试/线上 Zone:一个数据中心,相 ...
- 5.hbase表新增数据同步之add_peer
一.前提主从集群之间能互相通讯: 二.在cluster1上(源集群): 1.查看集群已开启的peers hbase(main):011:0> list_peers PEER_ID CLUSTE ...
- 基于TreeSoft实现异构数据同步
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路. TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之 ...
- 基于TreeSoft实现mysql、oracle、sql server的数据同步
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护需求,TreeSoft推出了数据同步,数据处理等丰富功能 . TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之间架起沟通的桥 ...
- Oracle数据同步交换
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路. TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之 ...
- SQL Server数据同步交换
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路. TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之 ...
- MySQL数据同步交换
一.为了解决数据同步汇聚,数据分发,数据转换,数据维护等需求,TreeSoft将复杂的网状的同步链路变成了星型数据链路. TreeSoft作为中间传输载体负责连接各种数据源,为各种异构数据库之 ...
- java——多线程的实现方式、三种办法解决线程赛跑、多线程数据同步(synchronized)、死锁
多线程的实现方式:demo1.demo2 demo1:继承Thread类,重写run()方法 package thread_test; public class ThreadDemo1 extends ...
- Linux实战教学笔记21:Rsync数据同步工具
第二十一节 Rsync数据同步工具 标签(空格分隔): Linux实战教学笔记-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品,允许转载,转载 ...
随机推荐
- IIS的垃圾回收对后台任务及隐形后台任务的影响
IIS的垃圾回收引起的影响 错误排查 现象:在.net core api里创建的BackgroundService定义rabbitmq消费的逻辑,在一段时间运行后经常会出现消费任务中断,在日志里找了很 ...
- EF Core Demo1——初识DbContext
EF中的上下文(DbContext)简介 DbContext是实体类和数据库之间的桥梁,DbContext主要负责与数据交互,主要作用: 1.DbContext包含所有的实体映射到数据库表的实体集 ...
- Fiddler的安装和使用教程(详细)
一.安装 1.fiddler工具下载网址:http://www.telerik.com/download/fiddler. 2.运行 FiddlerSetup.exe一键完成安装. 3.安装成功后点击 ...
- 最新Typora1.9.5破解版下载与使用教程(Windows+Mac)
一.Typora是什么? 一款 Markdown 编辑器和阅读器,能知道Typora的小伙伴,肯定也会用的 二.使用步骤 1.下载软件 夸克网盘:https://pan.quark.cn/s/2d6d ...
- 信息资源管理文字题之“IT服务管理的理念以及ITIL管理体系中IT服务十大核心流程”
一.阐述IT服务管理的理念以及ITIL(信息技术基础架构库)管理体系中IT服务十大核心流程 二.答案 答:IT服务管理的理念是:以流程为导向,以客户为中心 ITIL标准中归纳了两大类核心流程:服务支持 ...
- 仿EXCEL插件,智表ZCELL产品V2.1 版本发布,增加列标、行标自定义设置及单元格属性自定义相关功能,优化公式随动功能
详细请移步 智表(ZCELL)官网www.zcell.net 更新说明 这次更新主要应用户要求,增加列标.行标自定义设置及单元格属性自定义相关功能,优化公式随动功能 ,欢迎大家体验使用. 本次版本更 ...
- JavaScript编程艺术:掌门人的代码之道
@charset "UTF-8"; .markdown-body { line-height: 1.75; font-weight: 400; font-size: 15px; o ...
- 用C#将多个jpg合成一个pdf
nuget安装iTextSharp: static void MergePDF(string picPath,string pdfPath) { string[] picFileNames=Direc ...
- python3里面实现将日志文件写入当前脚本运行的文本中
在 Python3 中,可以使用 logging 模块来实现将日志写入本地文本文件中.下面是一个简单的示例代码: import logging # 配置 logging 模块 logging.basi ...
- Spring、Spring Framework、Spring Boot、Spring Cloud的区别
Spring Spring是一个生态体系(也可以说是技术体系),是集大成者,它包含了Spring Framework.Spring Boot.Spring Cloud等(还包括Spring Cloud ...