R数据分析:cox模型如何做预测,高分文章复现
今天要给大家分享的文章是
Cone EB, Marchese M, Paciotti M, Nguyen DD, Nabi J, Cole AP, Molina G, Molina RL, Minami CA, Mucci LA, Kibel AS, Trinh QD. Assessment of Time-to-Treatment Initiation and Survival in a Cohort of Patients With Common Cancers. JAMA Netw Open. 2020 Dec 1;3(12):e2030072. doi: 10.1001/jamanetworkopen.2020.30072. PMID: 33315115; PMCID: PMC7737088.
作者做了癌症结局与延迟治疗时间的关系。作者希望能给在疫情背景下怎么样更好地分流癌症患者这一实际问题提供实证依据。作者纳入了4个癌症,发现了基本上Time-to-treatment initiation (TTI)约长,癌症患者的5年和10年死亡率越高。这个结果和目前的部分指南其实是矛盾的,所以整篇文章还是有一定实际意义的。
本文依然是关注文章如何在做法上在统计上进行复现,启发大家如何用自己的数据做一个同样设计的研究。
文章回顾
作者将关心的主变量TTI进行了分类处理,将延迟治疗时间分了4类:
TTI was a categorical variable with 4 levels: 8 to 60, 61 to 120, 121 to 180, and greater than 180 days
为了准确地回答TTI如何影响了全因死亡率,作者还纳入了一系列的协变量包括:clinical demographic variables,clinical demographic variables,Modality of any treatment。构建了一个cox模型。
作者呈现出来的结果包括两个表,如下图,分别是纳入的不同癌症人群的人群特征和按照延迟治疗时间分组后的癌症特征:
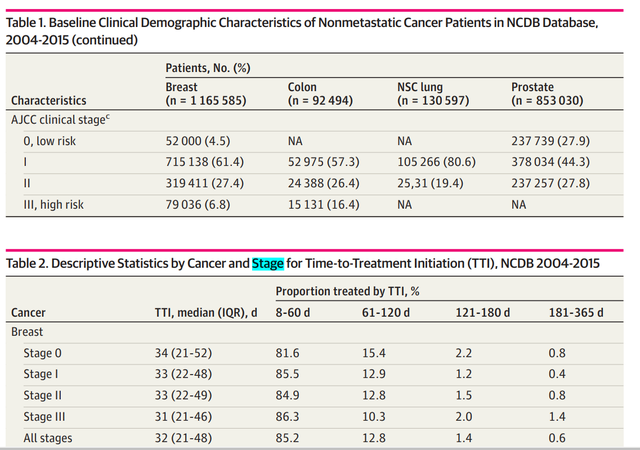
这两个表都是属于非常简单的描述统计,大家用用tableone或者gtsummary都可以很方便的做出来(请参考之前文章)。
具体到主分析,作者以all-cause mortality为结局变量,用训练好的cox模型以图的形式展示了不同TTI组随着时间变化predicted 5-year and 10-year all-cause mortality的变化情况:
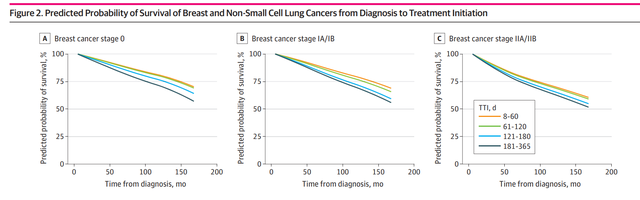
上图就是文章中截取的,展示的是通过cox模型预测出来的不同TTI类别组的随着时间变化的生存概率。整篇文章的主要统计工作就是这些,那么我们今天要做的就是复现出来整个预测概率并出图。
实例操练
我手上有数据如下:
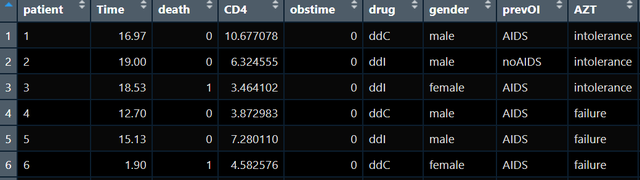
我希望训练一个cox模型然后像文章一样通过模型预测情况看一看,不同用药组随着时间变化其生存概率的变化是如何的。
首先我用我的数据训练一个简单的cox模型,需要用到coxph函数,整体代码如下:
fit <- coxph(Surv(Time, death) ~ CD4 + drug + gender, data = data)在上面的代码中我只是随意选择了3个变量:CD4 + drug + gender,或者说我在CD4 + gender存在的情况下我关心不同的drug(对应文章中的TTI)对患者随着时间变化的生存概率的影响情况。给大家展示下模型结果
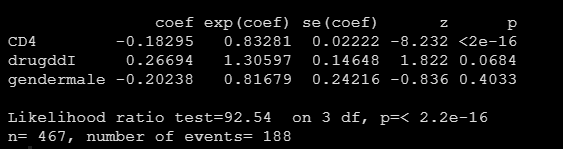
可以看到drug的效应并不显著,但是不影响我们示例作图。
到目前我们的cox模型训练好了,接下来我们需要用这个模型预测各组(此时是Drug变量的不同水平)从而得到模型的预测值,这个预测值一定是用控制了一系列的协变量之后的cox模型得到的预测值,作者的处理办法是将协变量都固定在均值水平:
Deriving predicted outcomes, while setting the covariate values at their mean, allowed us to estimate the mean difference in outcomes for each patient under different TTI while conserving their clinical and demographic characteristics
对于我们的cox模型来讲,我们关心的是drug这个变量,其余的变量同样的均需要固定在均值水平,生成新数据的代码如下:
ND1 <- with(aids.id, expand.grid(CD4 = 3, drug = levels(drug),
gender = factor("male", levels = levels(gender))))在上面的代码中,我们将协变量1--CD4固定在了3,将协变量性别固定为了男性,这个时候我们将数据带入训练好的cox模型中可以得到预测值surv_probs_Cox,直接用plot进行作图:
plot(surv_probs_Cox, col = c("black", "red"),
xlab = "Follow-Up Time (months)", ylab = "Survival Probabilities",
bty='l',
lwd=2
)
grid(ny=5,nx=NA,col='gray',lty = 1)运行代码后得到下图,下面的图就展示了随着时间变化不同用药的病人死亡概率的差异。
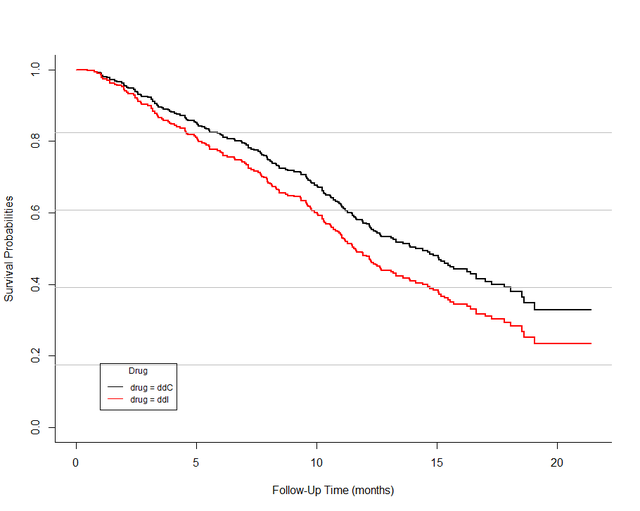
当然啦,为了和原文更像一点,我们可以用同样的数据在ggplot2中重新画下,并且像原文章一样将曲线变为smoothed curve,效果如下:
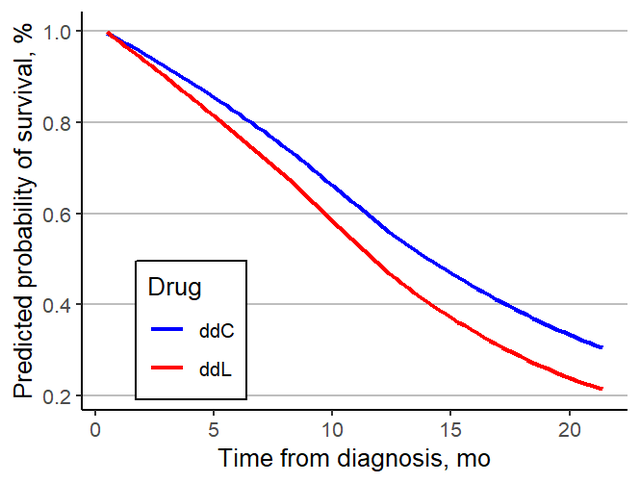
基本上和原文的展示形式一样了。每种癌症做完,形成大图,整篇文章的主分析也就完成了,好了,本文毕。
小结
今天给大家写了一篇文章的结果呈现方法,希望传递的信息是我们做cox模型,不一定都是在正文中给出一系列的HR,当我们能收到的临床数据很少的时候我们用图来展示结果有可能更加的easily interpreted by clinicians and policymakers。
R数据分析:cox模型如何做预测,高分文章复现的更多相关文章
- R数据分析:潜类别轨迹模型LCTM的做法,实例解析
最近看了好多潜类别轨迹latent class trajectory models的文章,发现这个方法和我之前常用的横断面数据的潜类别和潜剖面分析完全不是一个东西,做纵向轨迹的正宗流派还是这个方法,当 ...
- R数据分析:纵向数据如何做中介,交叉滞后中介模型介绍
看似小小的中介,废了我好多脑细胞,这个东西真的不简单,从7月份有人问我,我多重中介,到现在的纵向数据中介,从一般的回归做法,到结构方程框架下的路径分析法,到反事实框架做法,从中介变量和因变量到是连续变 ...
- R数据分析:跟随top期刊手把手教你做一个临床预测模型
临床预测模型也是大家比较感兴趣的,今天就带着大家看一篇临床预测模型的文章,并且用一个例子给大家过一遍做法. 这篇文章来自护理领域顶级期刊的文章,文章名在下面 Ballesta-Castillejos ...
- R数据分析:生存分析与有竞争事件的生存分析的做法和解释
今天被粉丝发的文章给难住了,又偷偷去学习了一下竞争风险模型,想起之前写的关于竞争风险模型的做法,真的都是皮毛哟,大家见笑了.想着就顺便把所有的生存分析的知识和R语言的做法和论文报告方法都给大家梳理一遍 ...
- R数据分析:二分类因变量的混合效应,多水平logistics模型介绍
今天给大家写广义混合效应模型Generalised Linear Random Intercept Model的第一部分 ,混合效应logistics回归模型,这个和线性混合效应模型一样也有好几个叫法 ...
- R数据分析:纵向分类结局的分析-马尔可夫多态模型的理解与实操
今天要给大家分享的统计方法是马尔可夫多态模型,思路来源是下面这篇文章: Ward DD, Wallace LMK, Rockwood K Cumulative health deficits, APO ...
- R数据分析:生存分析的列线图的理解与绘制详细教程
列线图作为一个非常简单明了的临床辅助决策工具,在临床中用的(发文章的)还是比较多的,尤其是肿瘤预后: Nomograms are widely used for cancer prognosis, p ...
- R数据分析:如何简洁高效地展示统计结果
之前给大家写过一篇数据清洗的文章,解决的问题是你拿到原始数据后如何快速地对数据进行处理,处理到你基本上可以拿来分析的地步,其中介绍了如何选变量如何筛选个案,变量重新编码,如何去重,如何替换缺失值,如何 ...
- R数据分析:临床预测模型中校准曲线和DCA曲线的意义与做法
之前给大家写过一个临床预测模型:R数据分析:跟随top期刊手把手教你做一个临床预测模型,里面其实都是比较基础的模型判别能力discrimination的一些指标,那么今天就再进一步,给大家分享一些和临 ...
- R语言︱机器学习模型评估方案(以随机森林算法为例)
笔者寄语:本文中大多内容来自<数据挖掘之道>,本文为读书笔记.在刚刚接触机器学习的时候,觉得在监督学习之后,做一个混淆矩阵就已经足够,但是完整的机器学习解决方案并不会如此草率.需要完整的评 ...
随机推荐
- Windows应急响应-Auto病毒
目录 应急背景 分析样本 开启监控 感染病毒 查看监控 分析病毒行为 autorun.inf分析 2.异常连接 3.进程排查 4.启动项排查 查杀 1.先删掉autorun.inf文件 2.使用xue ...
- placement new --特殊的内存分配
placement new 是 C++ 中的一种特殊的内存分配技术,用来在指定的内存地址上直接构造对象.与普通的 new 运算符不同,placement new 并不分配新的内存,而是在已经分配好的内 ...
- 双指针习题:Kalindrome Array
Kalindrome Array 题目链接: Kalindrome Array - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 题面翻译 对于长度为 \(m\) 的序列 \(b\), ...
- Java中重写equals并重写hashcode方法的描述
1.两个对象的hashCode()相同,equals()不一定为true (1)重写equals()的同时,重写hashCode() a.定义Person类,私有属性name,age:有参构造,set ...
- CMDB实践指南:项目规划与实施策略解析
随着现代企业IT系统的日益复杂,如何有效管理这些庞大的IT资产和资源,成为每个企业必须面对的重要问题.CMDB应运而生,帮助企业集中管理IT资源,维护系统的稳定性,并支持故障排查与决策制定.本文将深入 ...
- 网页设计中常用的Web英文安全字体
原文地址:https://www.openkee.com/post-176.html 在 Web 编码中,CSS 默认应用的 Web 字体是有限的,你能看到的字体别人未必看得到.虽然在新版本的CSS3 ...
- Nuxt.js 应用中的 build:manifest 事件钩子详解
title: Nuxt.js 应用中的 build:manifest 事件钩子详解 date: 2024/10/22 updated: 2024/10/22 author: cmdragon exce ...
- 一文彻底搞定Redis与MySQL的数据同步
Redis 和 MySQL 一致性问题是企业级应用中常见的挑战之一,特别是在高并发.高可用的场景下.由于 Redis 是内存型数据库,具备极高的读写速度,而 MySQL 作为持久化数据库,通常用于数据 ...
- vue项目整合echarts
准备工作: 首先我们初始化一个vue项目,执行vue init webpack echart,接着我们进入初始化的项目下.安装echarts, npm install echarts -S //或 ...
- 🎈Fluent Editor 富文本开源2个月的总结:增加格式刷、截屏、TypeScript 类型声明等新特性
你好,我是 Kagol,个人公众号:前端开源星球. Fluent Editor 是一个基于 Quill 2.0 的富文本编辑器,在 Quill 基础上扩展了丰富的模块和格式,框架无关. 功能强大.开箱 ...