FastAPI 核心机制:分页参数的实现与最佳实践
title: FastAPI 核心机制:分页参数的实现与最佳实践
date: 2025/3/13
updated: 2025/3/13
author: cmdragon
excerpt:
在构建现代Web应用程序时,分页是一个不可或缺的功能。无论是处理大量数据还是优化用户体验,分页都起到了至关重要的作用。本文将深入探讨如何在FastAPI中实现分页参数(如page、page_size以及总页数计算),并涵盖相关的核心机制、最佳实践、常见问题及解决方案。
categories:
- 后端开发
- FastAPI
tags:
- FastAPI
- 分页
- Web开发
- 数据库查询
- 性能优化
- 安全实践
- 错误处理

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
{kind=link}
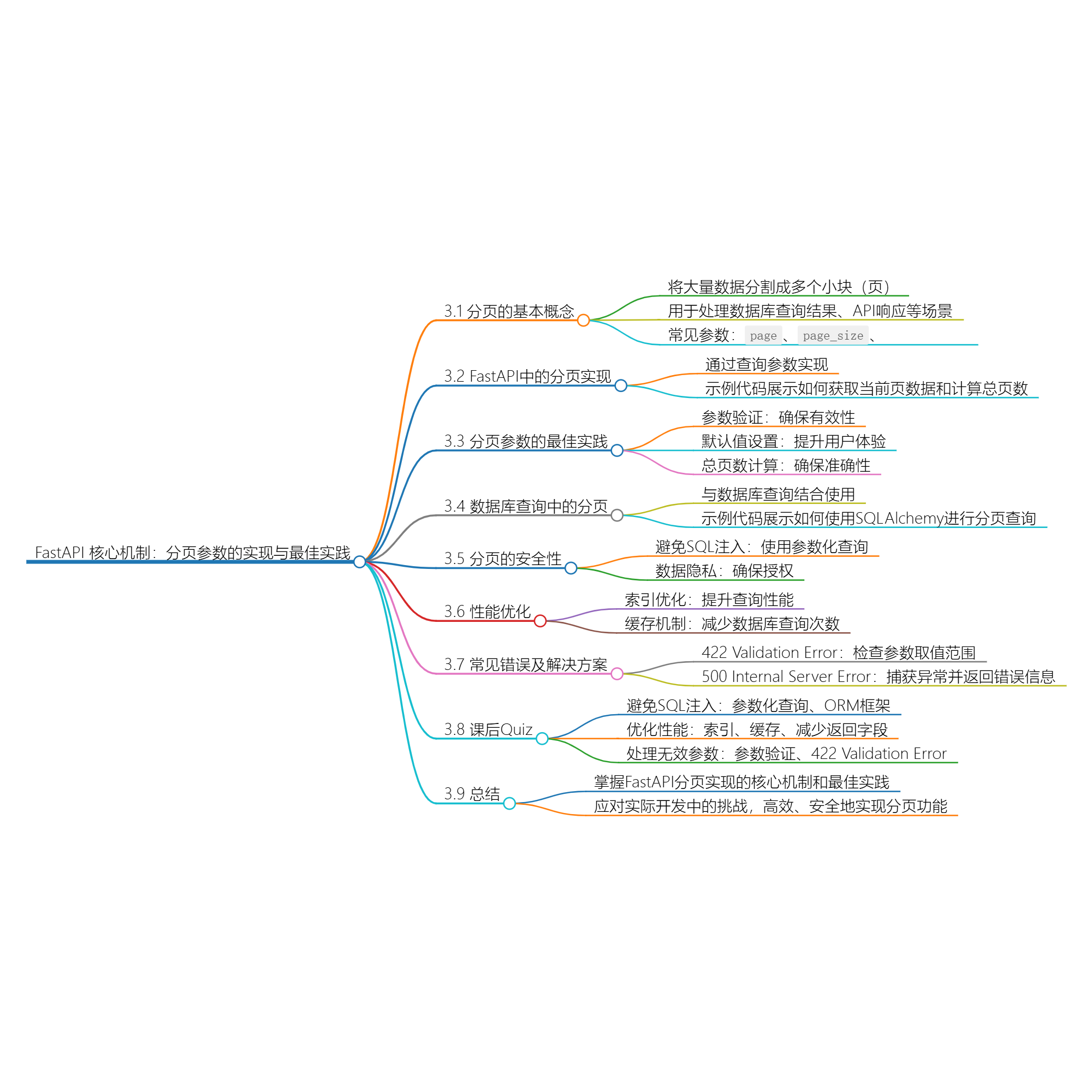
1. 分页的基本概念
分页是将大量数据分割成多个小块(即“页”),以便用户或系统可以逐步加载和处理这些数据。在Web应用中,分页通常用于处理数据库查询结果、API响应等场景。常见的分页参数包括:
page:当前页码。page_size:每页显示的数据条数。total_pages:总页数。
2. FastAPI中的分页实现
在FastAPI中,分页可以通过查询参数来实现。以下是一个简单的示例,展示了如何在FastAPI中实现分页功能。
from fastapi import FastAPI, Query
from typing import List, Optional
app = FastAPI()
# 模拟数据库数据
fake_items_db = [{"item_name": f"Item {i}"} for i in range(100)]
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0)):
start = (page - 1) * page_size
end = start + page_size
items = fake_items_db[start:end]
total_items = len(fake_items_db)
total_pages = (total_items + page_size - 1) // page_size
return {
"items": items,
"page": page,
"page_size": page_size,
"total_items": total_items,
"total_pages": total_pages,
}
在这个示例中,我们定义了两个查询参数page和page_size,并通过计算start和end
来获取当前页的数据。我们还计算了总页数total_pages,并将其包含在响应中。
3. 分页参数的最佳实践
3.1 参数验证
为了确保分页参数的有效性,我们需要对page和page_size进行验证。FastAPI提供了Query参数验证功能,可以轻松实现这一点。
from fastapi import Query
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100)):
# 分页逻辑
pass
在这个示例中,我们使用gt(大于)和le(小于等于)来限制page和page_size的取值范围。如果用户提供的参数不符合要求,FastAPI会自动返回422
Validation Error。
3.2 默认值设置
为分页参数设置合理的默认值可以提升用户体验。例如,将page_size的默认值设置为10或20,可以避免用户一次性加载过多数据。
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100)):
# 分页逻辑
pass
3.3 总页数计算
总页数的计算公式为:
total_pages = (total_items + page_size - 1) // page_size
这个公式确保了总页数的准确性,即使total_items不能被page_size整除。
4. 数据库查询中的分页
在实际应用中,分页通常与数据库查询结合使用。以下是一个使用SQLAlchemy进行分页查询的示例。
from sqlalchemy.orm import Session
from fastapi import Depends
from .database import SessionLocal
def get_db():
db = SessionLocal()
try:
yield db
finally:
db.close()
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100),
db: Session = Depends(get_db)):
start = (page - 1) * page_size
items = db.query(Item).offset(start).limit(page_size).all()
total_items = db.query(Item).count()
total_pages = (total_items + page_size - 1) // page_size
return {
"items": items,
"page": page,
"page_size": page_size,
"total_items": total_items,
"total_pages": total_pages,
}
在这个示例中,我们使用offset和limit来实现分页查询,并通过count方法获取总数据条数。
5. 分页的安全性
5.1 避免SQL注入
在使用原始SQL查询时,必须注意避免SQL注入攻击。SQLAlchemy等ORM框架已经内置了防止SQL注入的机制,但在使用原始SQL时,仍需谨慎。
from sqlalchemy.sql import text
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100),
db: Session = Depends(get_db)):
start = (page - 1) * page_size
query = text("SELECT * FROM items LIMIT :limit OFFSET :offset")
items = db.execute(query, {"limit": page_size, "offset": start}).fetchall()
total_items = db.execute(text("SELECT COUNT(*) FROM items")).scalar()
total_pages = (total_items + page_size - 1) // page_size
return {
"items": items,
"page": page,
"page_size": page_size,
"total_items": total_items,
"total_pages": total_pages,
}
在这个示例中,我们使用参数化查询来避免SQL注入。
5.2 数据隐私
在处理敏感数据时,确保分页查询不会泄露隐私信息。例如,避免在分页查询中返回未授权的数据。
6. 性能优化
6.1 索引优化
在数据库查询中,为分页字段(如id、created_at等)创建索引可以显著提升查询性能。
CREATE INDEX idx_items_created_at ON items (created_at);
6.2 缓存
对于频繁访问的分页数据,可以使用缓存机制(如Redis)来减少数据库查询次数。
from fastapi_cache import FastAPICache
from fastapi_cache.decorator import cache
@app.get("/items/")
@cache(expire=60)
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100)):
# 分页逻辑
pass
在这个示例中,我们使用fastapi-cache库来缓存分页查询结果,缓存有效期为60秒。
7. 常见错误及解决方案
7.1 422 Validation Error
当分页参数不符合验证规则时,FastAPI会返回422 Validation Error。解决方案是确保分页参数的取值范围正确,并在API文档中明确说明。
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100)):
# 分页逻辑
pass
7.2 500 Internal Server Error
当数据库查询失败或分页逻辑出现错误时,可能会返回500 Internal Server Error。解决方案是捕获异常并返回友好的错误信息。
from fastapi import HTTPException
@app.get("/items/")
async def read_items(page: int = Query(1, gt=0), page_size: int = Query(10, gt=0, le=100),
db: Session = Depends(get_db)):
try:
start = (page - 1) * page_size
items = db.query(Item).offset(start).limit(page_size).all()
total_items = db.query(Item).count()
total_pages = (total_items + page_size - 1) // page_size
return {
"items": items,
"page": page,
"page_size": page_size,
"total_items": total_items,
"total_pages": total_pages,
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
在这个示例中,我们捕获了所有异常,并返回500 Internal Server Error。
8. 课后Quiz
如何避免SQL注入攻击?
- 使用参数化查询。
- 避免拼接SQL语句。
- 使用ORM框架。
如何优化分页查询的性能?
- 为分页字段创建索引。
- 使用缓存机制。
- 减少查询返回的字段数量。
如何处理分页参数无效的情况?
- 使用FastAPI的
Query参数验证功能。 - 返回422 Validation Error。
- 在API文档中明确说明参数要求。
- 使用FastAPI的
常见报错解决方案:
- 422 Validation Error:检查分页参数的取值范围,确保符合验证规则。
- 500 Internal Server Error:捕获异常并返回友好的错误信息,检查数据库查询逻辑。
- 404 Not Found:确保分页参数不会导致查询结果为空,处理边界情况。
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:FastAPI 核心机制:分页参数的实现与最佳实践 | cmdragon's Blog
往期文章归档:
- FastAPI 错误处理与自定义错误消息完全指南:构建健壮的 API 应用 ️ | cmdragon's Blog
- FastAPI 自定义参数验证器完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI 参数别名与自动文档生成完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI Cookie 和 Header 参数完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI 表单参数与文件上传完全指南:从基础到高级实战 | cmdragon's Blog
- FastAPI 请求体参数与 Pydantic 模型完全指南:从基础到嵌套模型实战 | cmdragon's Blog
- FastAPI 查询参数完全指南:从基础到高级用法 | cmdragon's Blog
- FastAPI 路径参数完全指南:从基础到高级校验实战 | cmdragon's Blog
- FastAPI路由专家课:微服务架构下的路由艺术与工程实践 | cmdragon's Blog
- FastAPI路由与请求处理进阶指南:解锁企业级API开发黑科技 | cmdragon's Blog
- FastAPI路由与请求处理全解:手把手打造用户管理系统 | cmdragon's Blog
- FastAPI极速入门:15分钟搭建你的首个智能API(附自动文档生成) | cmdragon's Blog
- HTTP协议与RESTful API实战手册(终章):构建企业级API的九大秘籍 | cmdragon's Blog
- HTTP协议与RESTful API实战手册(二):用披萨店故事说透API设计奥秘 | cmdragon's Blog
- 从零构建你的第一个RESTful API:HTTP协议与API设计超图解指南 | cmdragon's Blog
- Python异步编程进阶指南:破解高并发系统的七重封印 | cmdragon's Blog
- Python异步编程终极指南:用协程与事件循环重构你的高并发系统 | cmdragon's Blog
- Python类型提示完全指南:用类型安全重构你的代码,提升10倍开发效率 | cmdragon's Blog
- 三大平台云数据库生态服务对决 | cmdragon's Blog
- 分布式数据库解析 | cmdragon's Blog
- 深入解析NoSQL数据库:从文档存储到图数据库的全场景实践 | cmdragon's Blog
- 数据库审计与智能监控:从日志分析到异常检测 | cmdragon's Blog
- 数据库加密全解析:从传输到存储的安全实践 | cmdragon's Blog
- 数据库安全实战:访问控制与行级权限管理 | cmdragon's Blog
- 数据库扩展之道:分区、分片与大表优化实战 | cmdragon's Blog
- 查询优化:提升数据库性能的实用技巧 | cmdragon's Blog
- 性能优化与调优:全面解析数据库索引 | cmdragon's Blog
- 存储过程与触发器:提高数据库性能与安全性的利器 | cmdragon's Blog
- 数据操作与事务:确保数据一致性的关键 | cmdragon's Blog
- 深入掌握 SQL 深度应用:复杂查询的艺术与技巧 | cmdragon's Blog
- 彻底理解数据库设计原则:生命周期、约束与反范式的应用 | cmdragon's Blog
- 深入剖析实体-关系模型(ER 图):理论与实践全解析 | cmdragon's Blog
- 数据库范式详解:从第一范式到第五范式 | cmdragon's Blog
- PostgreSQL:数据库迁移与版本控制 | cmdragon's Blog
- Node.js 与 PostgreSQL 集成:深入 pg 模块的应用与实践 | cmdragon's Blog
FastAPI 核心机制:分页参数的实现与最佳实践的更多相关文章
- Spring进阶之路(1)-Spring核心机制:依赖注入/控制反转
原文地址:http://blog.csdn.net/wangyang1354/article/details/50757098 我们经常会遇到这样一种情景,就是在我们开发项目的时候经常会在一个类中调用 ...
- MFC六大核心机制之二:运行时类型识别(RTTI)
上一节讲的是MFC六大核心机制之一:MFC程序的初始化,本节继续讲解MFC六大核心机制之二:运行时类型识别(RTTI). typeid运算子 运行时类型识别(RTTI)即是程序执行过程中知道某个对象属 ...
- MFC六大核心机制之一:MFC程序的初始化
很多做软件开发的人都有一种对事情刨根问底的精神,例如我们一直在用的MFC,很方便,不用学太多原理性的知识就可以做出各种窗口程序,但喜欢钻研的朋友肯定想知道,到底微软帮我们做了些什么,让我们在它的框架下 ...
- 第七章 探秘Qt的核心机制-信号与槽
第七章 探秘Qt的核心机制-信号与槽 注:要想使用Qt的核心机制信号与槽,就必须在类的私有数据区声明Q_OBJECT宏,然后会有moc编译器负责读取这个宏进行代码转化,从而使Qt这个特有的机制得到使用 ...
- Qt核心机制与原理
转: https://blog.csdn.net/light_in_dark/article/details/64125085 ★了解Qt和C++的关系 ★掌握Qt的信号/槽机制的原理和使用方法 ★ ...
- 前端工程化系列[06]-Yeoman脚手架核心机制
在前端工程化系列[05] Yeoman脚手架使用入门这边文章中,对Yeoman的使用做了简单的入门介绍,这篇文章我们将接着探讨Yeoman这个脚手架工具内部的核心机制,主要包括以下内容 ❏ Yeoma ...
- Flask核心机制--上下文源码剖析
一.前言 了解过flask的python开发者想必都知道flask中核心机制莫过于上下文管理,当然学习flask如果不了解其中的处理流程,可能在很多问题上不能得到解决,当然我在写本篇文章之前也看到了很 ...
- javashop技术培训总结,架构介绍,Eop核心机制
javashop技术培训一.架构介绍1.Eop核心机制,基于spring的模板引擎.组件机制.上下文管理.数据库操作模板引擎负责站点页面的解析与展示组件机制使得可以在不改变核心代码的情况下实现对应用核 ...
- 7 -- Spring的基本用法 -- 3... Spring 的核心机制 : 依赖注入
7.3 Spring 的核心机制 : 依赖注入 Spring 框架的核心功能有两个. Spring容器作为超级大工厂,负责创建.管理所有的Java对象,这些Java对象被称为Bean. Spring容 ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(1)
大数据处理肯定是分布式的了,那就面临着几个核心问题:可扩展性,负载均衡,容错处理.Spark是如何处理这些问题的呢?接着上一篇的"动手写WordCount",今天要做的就是透过这个 ...
随机推荐
- IDEA自动导包(全局设置)
选择[File]-->[other settings]-->[settings for new projects](全局设置),然后搜索[Auto Import],勾选以下两个选项即可: ...
- Qt/C++音视频开发69-保存监控pcm音频数据到mp4文件/监控录像/录像存储和回放/264/265/aac/pcm等
一.前言 用ffmpeg做音视频保存到mp4文件,都会遇到一个问题,尤其是在视频监控行业,就是监控摄像头设置的音频是PCM/G711A/G711U,解码后对应的格式是pcm_s16be/pcm_ala ...
- FluentAssertions:C#单元测试断言库,让测试代码更加直观、易读!
推荐一个C#开源库,用于单元测试中的断言,它提供了一系列的扩展方法,使得单元测试的断言看起来更加自然流畅. 01 项目简介 FluentAssertions 是一个基于 .NET 的断言库,它提供了一 ...
- ubuntu opencv安装与卸载
安装opencv 1.在下面网站上下载所需版本的源文件Releases - OpenCVhttps://opencv.org/releases/ 2.解压并进入该文件夹 3.命令行执行如下指令 ...
- 即时通讯技术文集(第43期):直播技术合集(Part3) [共13篇]
为了更好地分类阅读 52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第 43 期. [-1-] 直播系统聊天技术(一):百万在线的美拍直播弹幕系统的实时推送技术实践 ...
- 得物从0到1自研客服IM系统的技术实践之路
本文由得物技术王卫强分享,为了更好的阅读体验,有较多的内容修订和排版优化. 一.引言 客服IM的核心业务其实就是在线沟通,客服IM的好处是使得客服与用户通过实时沟通的方式可以在最短的时间内帮助用户解决 ...
- Linux服务器环境安装mysql
背景 1.安装环境:kvm虚拟机 2.运行环境:linux 3.架构:x86 4.安装mysql版本:mysql-5.7 1.安装准备 # Mysql官网 https://downloads.mysq ...
- Linux 压缩命令集合
01. tar格式 解包:tar xvf FileName.tar 打包:tar cvf FileName.tar DirName(注:tar是打包,不是压缩!) 02. gz格式 解压1:gunzi ...
- Solution Set - “潮汐守候终结放逐月圆”
目录 0.「NOI Simu.」游戏 1.「NOI Simu.」海盗 2.「集训队作业 2020-2021」「LOJ #3405」Gem Island 2 3.「UR #12」「UOJ #181」密码 ...
- 一个适用于 .NET 的开源整洁架构项目模板
前言 项目架构模式在软件开发中扮演着至关重要的角色,它们为开发者提供了一套组织和管理代码的指导原则,以提高软件的可维护性.可扩展性.可重用性和可测试性.今天大姚给大家分享一个适用于 .NET 的开源整 ...