记录-内网部署vllm分布式推理DeepSeekR1:70b
背景
前段时间接到需求要在内网部署DeepSeekR1:70b,由于手里的服务器和显卡比较差(四台 四块Tesla T4- 16g显存的服务器),先后尝试了ollama、vllm、llamacpp等,最后选择用vllm的分布式推理来部署。
需要准备的资源
- vllm的docker镜像(可以从docker hub 下载,使用docker save -o命令保存拿到内网服务器中)
- run_cluster.sh脚本(用来启动docker镜像和进行ray通信,下面会贴上我目前在用的版本)
- 模型文件(huggingface下载,国内可以用hf-mirror镜像站),需要下载到所有分布式机器的磁盘中,最好保持存储路径一致。
- nvidia驱动、cuda等是必备的,不提了
部署过程
载入vllm的docker镜像
docker load -i vllm.tar编写脚本vi run_cluster.sh
所有机器都使用如下脚本
点击查看代码
``#!/bin/bash
# Check for minimum number of required arguments
if [ $# -lt 4 ]; then
echo "Usage: $0 docker_image head_node_address --head|--worker path_to_hf_home [additional_args...]"
exit 1
fi
DOCKER_IMAGE="$1"
HEAD_NODE_ADDRESS="$2"
NODE_TYPE="$3" # Should be --head or --worker
PATH_TO_HF_HOME="$4"
shift 4
# Additional arguments are passed directly to the Docker command
ADDITIONAL_ARGS=("$@")
# Validate node type
if [ "${NODE_TYPE}" != "--head" ] && [ "${NODE_TYPE}" != "--worker" ]; then
echo "Error: Node type must be --head or --worker"
exit 1
fi
# Define a function to cleanup on EXIT signal
cleanup() {
docker stop node
docker rm node
}
trap cleanup EXIT
# Command setup for head or worker node
RAY_START_CMD="ray start --block"
if [ "${NODE_TYPE}" == "--head" ]; then
RAY_START_CMD+=" --head --port=6379"
else
RAY_START_CMD+=" --address=${HEAD_NODE_ADDRESS}:6379"
fi
# Run the docker command with the user specified parameters and additional arguments
#docker run \
# -d \
# --entrypoint /bin/bash \
docker run \
--entrypoint /bin/bash \
--network host \
--name node \
--shm-size 10.24g \
--gpus all \
-v "${PATH_TO_HF_HOME}:/root/.cache/huggingface" \
"${ADDITIONAL_ARGS[@]}" \
"${DOCKER_IMAGE}" -c "${RAY_START_CMD}"
查看网卡信息
输入ip a
找到这台机器对应的编号,用在之后的启动命令中

启动脚本(每台机器都需要启动,选择任意一台为主节点,其他为工作节点)
启动命令:( --head为主机 --worker为其他机器使用,命令中的ip都需要填写主机的ip)
主机脚本 bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --head /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0
工作机脚本 bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --worker /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0
后台运行 也可以通过nohup后台运行,如:nohup bash run_cluster.sh vllm/vllm-openai:v0.6.4.post1 主机ip --worker /data/vllm_model -v /data/vllm_model/:/model/ -e GLOO_SOCKET_IFNAME=ens13f0 -e NCCL_SOCKET_IFNAME=ens13f0 >/ray_file 2>&1 &
/data/vllm_model为你模型文件的位置,如下图则启动成功
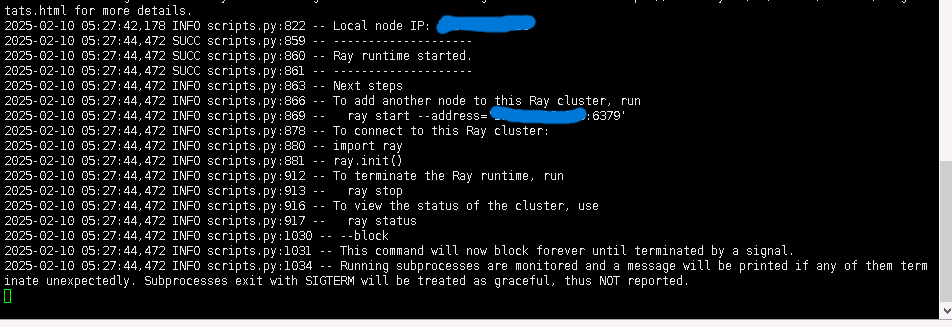
所有都成功启动后可以使用任何一台机器的ssh会话,因为已经通信,所以哪台机器都可以启动vllm。注意不要关闭任何一台机器的run_cluster启动的页面,
使用docker ps 查看运行的镜像
进入镜像内部
输入docker exec -it 镜像号 /bin/bash进入
输入ray status可以查看当前通信状态
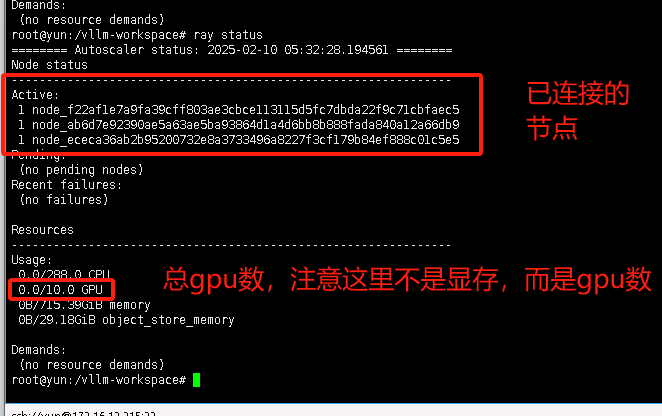
直接在docker中启动vllm
命令:vllm serve /model/DeepSeek-R1-Distill-Llama-70B --tensor-parallel-size 4 --pipeline-parallel-size 4 --dtype=float16
注:我的vllm运行命令中tensor-parallel对应每台服务器的gpu数,pipeline-parallel-size对应服务器数,--dtype=float16这个由于Tesla T4计算精度的问题需要添加这个配置降低模型的精度,如果显卡计算能力8.0以上可以不加这个配置。关于分布式并行的参数这里博主没有深究含义,如果有更好的使用方式也可以交流下。
参数含义
--tensor-parallel-size
这个参数表示 张量并行(Tensor Parallelism) 的规模。
将一个神经网络的 权重矩阵 切分到多个 GPU 上。
通常用于切分 Transformer 中的 attention 或 FFN 层的权重。
例如设置为 4,意味着一个 attention 层的计算会被分成 4 份,在 4 个 GPU 上并行进行。
适用于具有较大权重矩阵的模型,如 LLaMA、GPT 等,能充分利用多个 GPU 的显存和计算资源。
--pipeline-parallel-size
这个参数表示 流水线并行(Pipeline Parallelism) 的规模。
将整个模型的 不同层 分配到不同的 GPU 上,形成一个“流水线”。
每个 GPU 处理模型的一部分,然后把结果传给下一个 GPU。
设置为 2 表示模型被分成 2 段,分别在两个 GPU 上依次运行。
适用于模型层数较多时进一步扩展模型到更多 GPU 上。
记录-内网部署vllm分布式推理DeepSeekR1:70b的更多相关文章
- Redis-3.2.1集群内网部署
摘要: Redis-3.2.1集群内网部署 http://rubygems.org国内连不上时的一种Redis集群部署解决方案.不足之处,请广大网友指正,谢谢! 一. 关于redis cluster ...
- centos7谷歌chrome内网部署演示
上传需要的包,注释网关创建内网环境 [root@localhost ~]# ls anaconda-ks.cfg chrome mcw4 mcw4.tar.gz mcwchromerpm.tar.gz ...
- 内网部署Docker版本Gitlab
Gitlab部署: 1. 还原备份文件后记得拷贝gitlab-secrets.json,不然会遇到500错误 2. 下载Docker以及依赖项rpm包 3. 在外网机器下载镜像 a. 拉取——Dock ...
- 内网部署YApi
官网地址:https://hellosean1025.github.io/yapi/devops/index.html 环境要求 nodejs(7.6+) mongodb(2.6+),安装看这篇文章: ...
- yapi内网部署 centos
1.部署方案 官方说明: https://hellosean1025.github.io/yapi/devops/index.html 2.需要注意的点 (1)在centos等服务启上最好使用“命令行 ...
- DLINK 企业路由器内网部署web开启端口转发后还需要开启是否支持端口回流功能
跑后台使用的服务器,配置一般都很低,带宽只有2Mb 一些大型文件比如app的更新包使用这种服务器不可行 但是公司的网络是100Mb对等静态ip专线 所以能利用起来,每年将会省下8万块 说干就干,这个步 ...
- 外网访问内网工具ngrok tunnel 使用总结
需求分析 在软件开发测试过程中,我们会经常遇到需要网站部署测试.给客户演示.APP开发的调试这样的需求.通常的做法是申请一个域名和空间,将网站放到外网上给客户演示. 这种方法确实可行不过会有两点不好, ...
- EasyNVR内网摄像机接入网关+EasyNVS云端管理平台,组件起一套轻量级类似于企业级萤石云的解决方案
背景分析 对于EasyNVR我们应该都了解,主要应用于互联安防直播,对于EasyNVR,我们可以清楚的发现,EasyNVR的工作机制是EasyNVR拉取摄像机的RTSP/Onvif视频流,然后客户端可 ...
- Centos下内网DNS主从环境部署记录
一.DNS是什么?DNS(Domain Name System),即域名系统.它使用层次结构的命名系统,将域名和IP地址相互映射,形成一个分布式数据库系统. DNS采用C-S架构,服务器端工作在UDP ...
- yum仓库配置与内网源部署记录
使用yum的好处主要就是在于能够自动解决软件包之间的依赖.这使得维护更加容易.这篇文章主要就是记录部署内网源的操作过程以及yum工具如何使用 因为需要.数据库要从Oracle迁移至MySQL.在部署M ...
随机推荐
- 直播预览层添加滤镜效果(CIFilter使用场景)
直播预览层添加滤镜效果 原理,在显示之前,提前对图片进行滤镜处理,把处理后的图片展示出来就好了. CIFiter(滤镜类):给图片添加特殊效果(模糊,高亮等等). CIFiter滤镜分类(一个滤镜可能 ...
- 手撸原生js放大镜效果
普及知识:放大镜特效涉及到的几个值 offsetWidth 获取元素的宽度offsetHeight 获取元素的高度offsetLeft父元素没有定位时,获取元素距离页面的左边距,父元素有定位时 ...
- Integer包装类中的IntegerCache结构
public void test3() { Integer i = new Integer(1); Integer j = new Integer(1); System.out.println(i = ...
- ESP32 VScode环境问题
vsdcode esp-idf插件安装 报错: Espressif\tools\idf-python\3.11.2\python.exe -m pip" is not valid. (ERR ...
- linux安装hbase
下载后解压到/opt/Servers/hbase-1.4.6 使用Hbase自带的zookeeper================================================== ...
- Iceberg根据快照查看文件,根据文件查看哪个快照写入
一.背景 用户查询iceberg表时报文件为空,因为存在写入和治理程序同时操作iceberg表,需要查看空文件是哪个快照产生的,方便确定是flink写入缺陷还是spark治理缺陷 二.通过Sql查询文 ...
- mybatis之增删改查
核心配置文件中配置数据库连接及注册mapper.xml mapper.xml用来编写执行的sql(namespace为对应的接口类,标签id为接口类中的方法名) User为实体对象类 UserDao为 ...
- P4774 [NOI2018] 屠龙勇士 题解
传送门 题解 思路 由题目可知,一条龙被攻击 \(x\) 次并回复若干次后生命值恰好为 \(0\) 则死亡,可以得出如下式子: \[\large ATK_i \cdot x \equiv a_i(\m ...
- 程序员转型AI:行业分析
系列目录 1.程序员转型AI:行业分析 2.程序员转型AI:转型计划 3.程序员转型AI:落地实践 4.程序员转型AI:展望未来 一.背景分析 进入2025年,AI已经爆发式增长,且进入实际商业变现阶 ...
- [BZOJ3037] 创世纪 题解
基环内向树上 dp,不过在这里提供给一种非典型做法. 考虑将环上的每一条边都断开,这样就会形成多棵树,先在这些树上进行树形 \(dp\).设 \(dp_{i,0/1}\) 表示不选/选 \(i\) 时 ...