LLM-RAG项目细节-数据处理、分块..
rag项目细节
当模型没有某部分知识的时候,你将文档丢给大模型,告诉他了这些知识,然后大模型根据你的文档对你的问题进行回答

文档处理
未经处理的手机扫描pdf或者打印机扫描pdf则为不可编辑形式文档
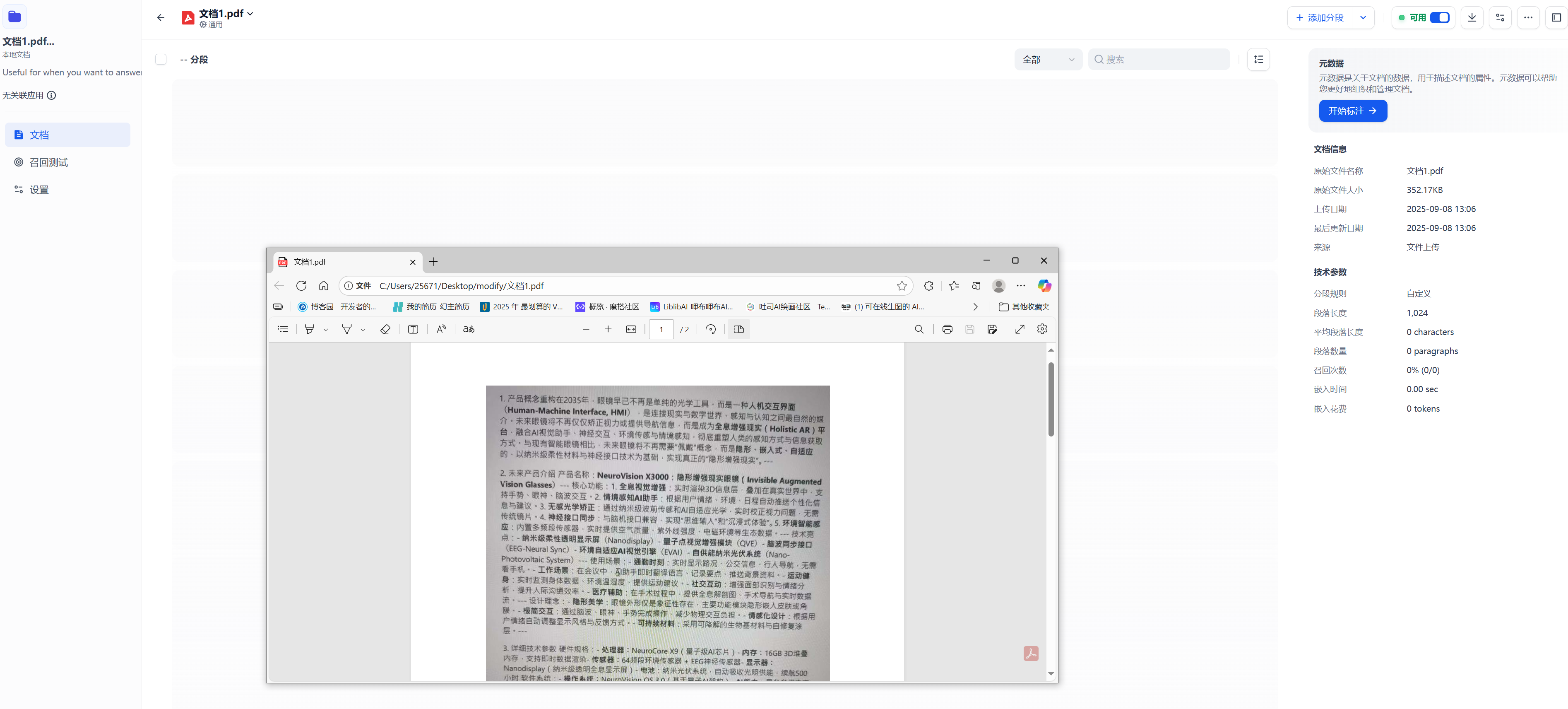
在一些没有ocr能力或者ocr能力不强的rag框架下会直接0字符不会有任何内容
通过mineru转换为可编辑的markdown形式


上传mineru处理过的文件成功识别到字符数
切块

将这种段落格式的文档丢给dify来看看他会怎么切块
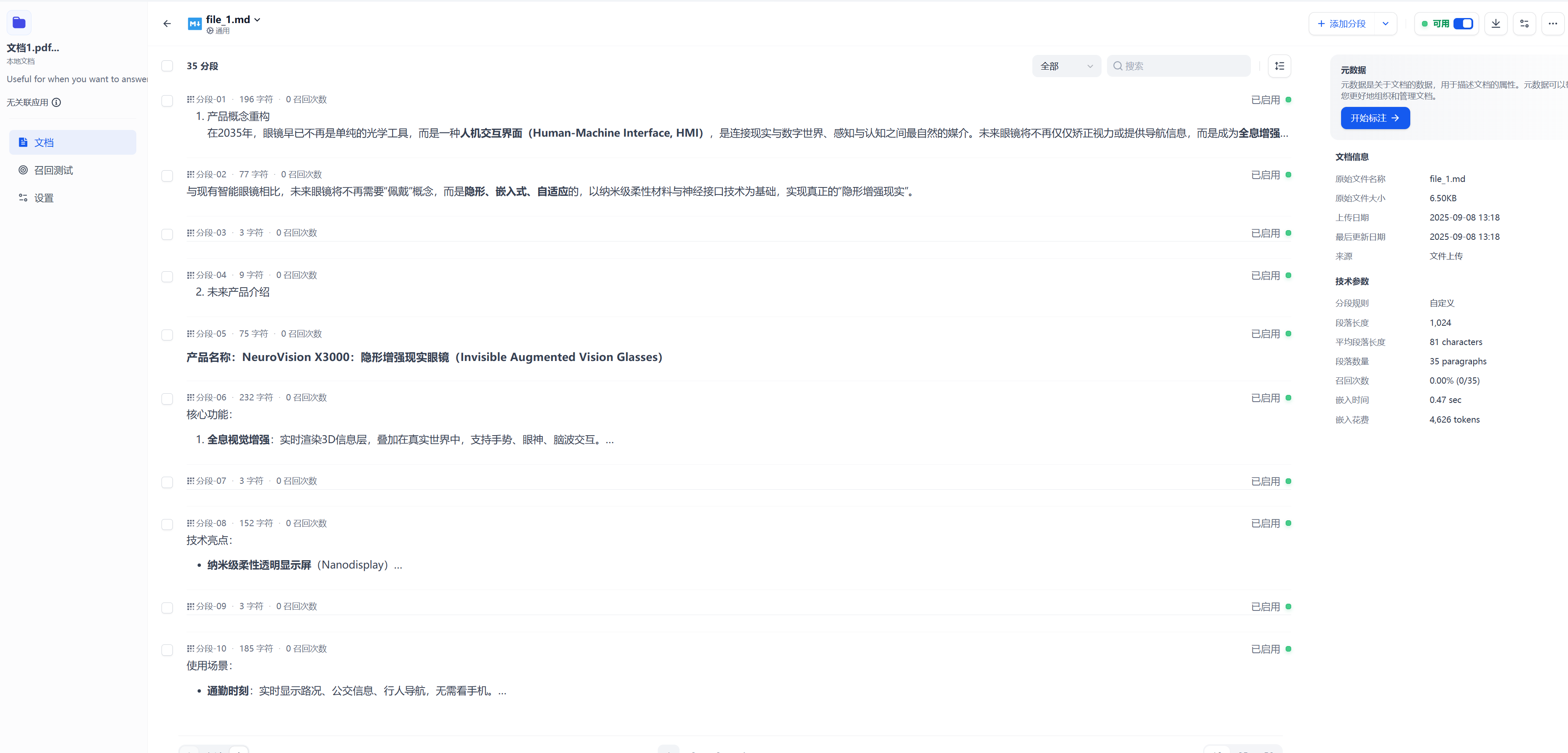
可以看到每个块的字符数特别少,块很多。这会导致召回的质量非常的低信息不完整
尝试召回,效果并不好

召回测试非常重要,针对五进行召回测试
这里如果切块没有切好,召回的信息不完整或者过多都会影响性能,目前我们是召回信息不完整。这里出问题rag项目没必要进行下去,我们正在做 通过问题去向量数据库里检索切块内容
文档ocr解决了dify可以识别编辑文字
大模型一次吃不下一个文档所以必须切块、切块提高了效率可以并发、好的切块每段信息会是完整切字符保持平均
对初始文本进行python数据处理
python批处理代码如下
import os
def process_file(file_path):
"""
读取文件,删除所有回车,然后删除####符号(保留内容),保存为原文件名+re
"""
# 读取文件
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 删除所有回车换行符
content = content.replace('\n', '').replace('\r', '')
# 删除四个#符号(只删符号,保留后面的内容)
content = content.replace('####', '')
# 在###标题后面添加回车
content = content.replace('###', '###').replace('###', '\n###')
# 修正开头可能多出的换行
if content.startswith('\n'):
content = content[1:]
# 保存到新文件
output_file = file_path.rsplit('.', 1)[0] + 're.' + file_path.rsplit('.', 1)[1]
with open(output_file, 'w', encoding='utf-8') as f:
f.write(content)
print(f"处理完成!输出文件:{output_file}")
def process_all_files_in_folder(folder_path):
"""
遍历文件夹中的所有文件并处理
"""
for filename in os.listdir(folder_path):
file_path = os.path.join(folder_path, filename)
# 只处理文件,跳过文件夹
if os.path.isfile(file_path):
print(f"正在处理: {filename}")
process_file(file_path)
# 使用示例
process_all_files_in_folder('file-dir') # 遍历file-dir文件夹中的所有文件

经过python处理后整个文档被拆成大标题的6段。再次上传dify并测试召回


被召回的段落信息完整
embeding

设置一下厂商的api-key
这个选择一个用中文训练的embeding模型就好
帮助中文转为数字向量这个过程
我这里选qwen3embeding
向量数据库
为什么Dify选择Weaviate
RAG应用友好
非常适合构建检索增强生成(RAG)应用
支持文档切片、向量化、存储、检索的完整流程
开发体验好
安装部署相对简单,有Docker镜像
文档完善,社区活跃
提供直观的管理界面
扩展性强
支持水平扩展
可以处理大规模向量数据
这些特点使得Weaviate成为构建AI应用特别是知识库和问答系统的理想选择,这正是Dify这类LLM应用开发平台所需要的能力。
dify在用这个向量数据库,可以把这个容器删了换一下改源码换成qdrant。还是用dify的吧先把该项目演示完。不同向量数据库会有差别会对最后的rag效果产生影响
用户提问、小结
目前则是文档切块向量化丢进了数据库,用户提问题,问题会去数据库检索
检索出一个content里面为相似切块内容,用户提问带上系统提示词带上切块一起给大模型。大模型给出回复
dify未来产品客服系统搭建、rerank
system系统提示词
你是一个热情幽默活泼销售经理,你熟读知识库context里的内容,
并且根据context真实内容进行推销,必须是context里真实内容。
使用以下信息为你的内容,放在<context></context> XML标签内。
<context>
{{#context#}}
</context>
回答用户时:
如果你不知道,就直说你不知道。如果你在不确定的时候不知道,就寻求澄清。
避免提及你是从上下文中获取的信息。
并根据用户问题的语言来回答。
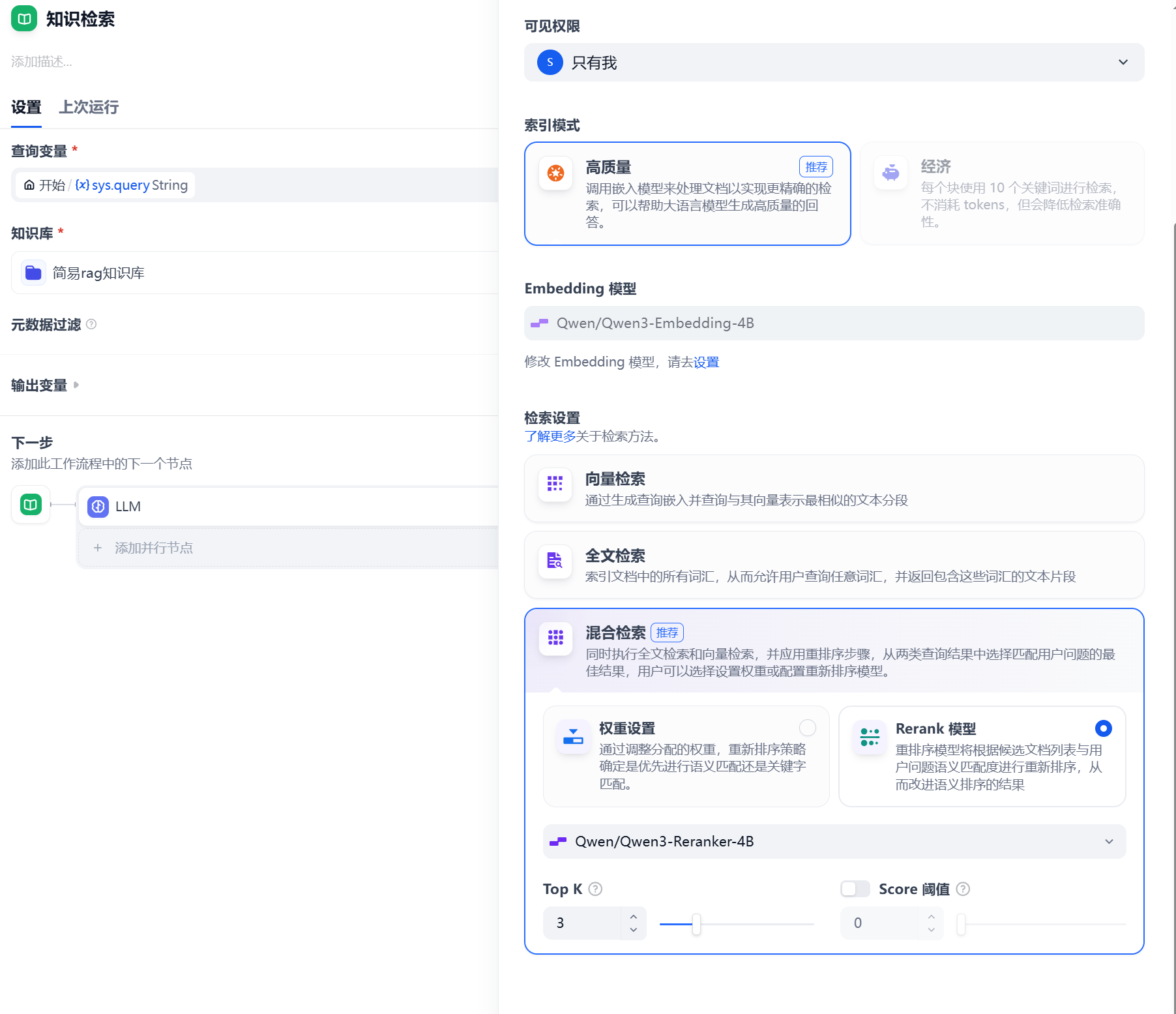
使用reranker粗排后精细排序
准确无误块大小合适,llm根据块和提问一起回答。效果不错
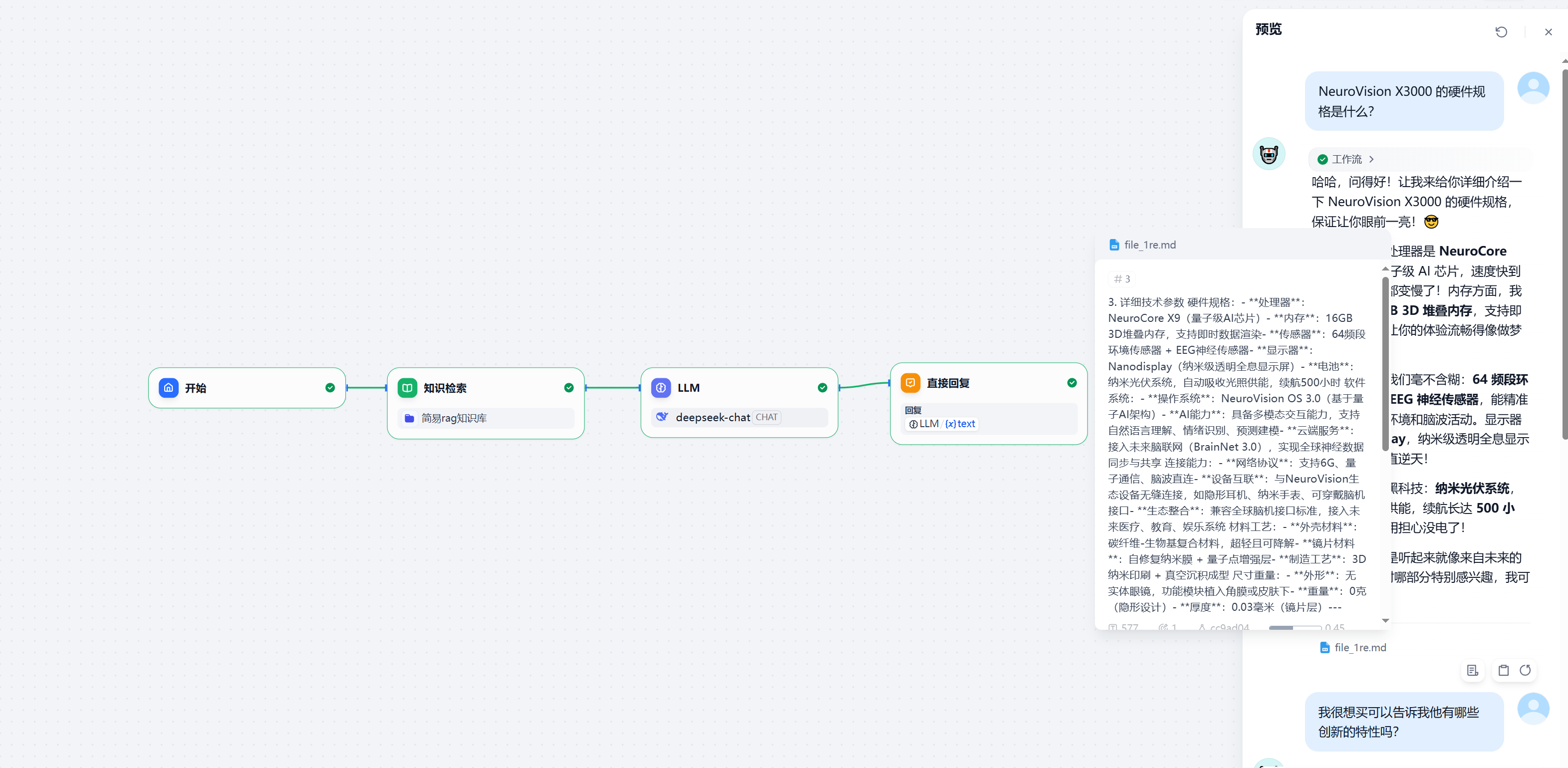
dify增加文档数量至20
问题测试
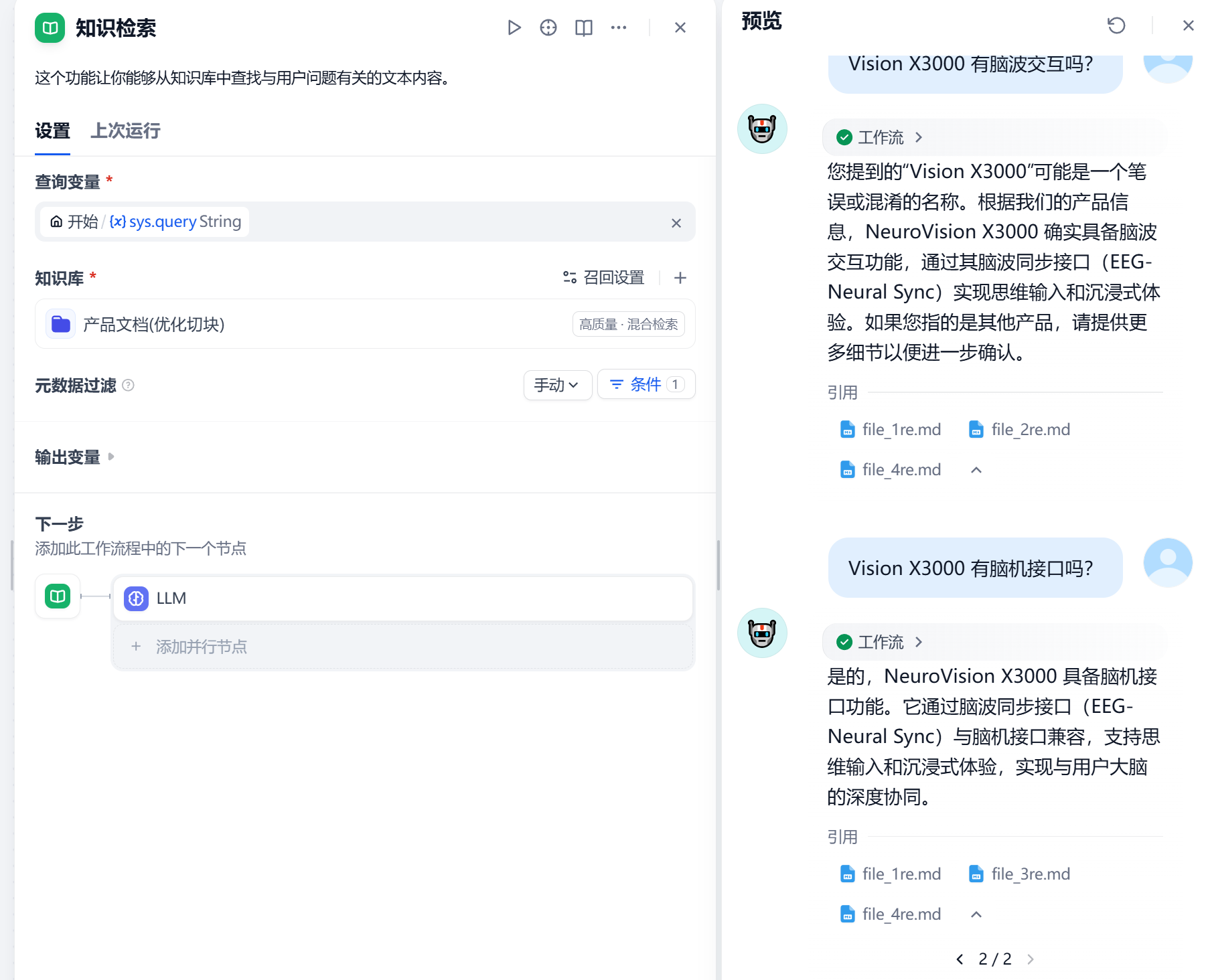
NeuroVision X3000 的硬件规格是什么?
NeuralGlow 的硬件规格是什么?
NeuroVision X3000 有脑波交互吗?
Vision X3000 有脑机接口吗?
topk参数

score阈值
两个参数的协同关系
python# 检索流程
similarities = [0.89, 0.697, 0.686, 0.609, 0.45, 0.32, 0.28]
# 第一步:topk控制数量(扩大/缩小搜索范围)
topk = 4
candidates = [0.89, 0.697, 0.686, 0.609] # 取前4个
# 第二步:score阈值过滤质量(过滤低分)
score_threshold = 0.65
final_results = [0.89, 0.697, 0.686] # 0.609被过滤掉
实际工作机制
topk = 搜索广度
topk=1: 只要最匹配的,风险:信息不足
topk=10: 广撒网,风险:引入噪音
topk=4: 平衡点(你的选择)
score = 质量门槛
score≥0.8: 高质量,但可能数量不够
score≥0.6: 中等质量,平衡点
score≥0.4: 低门槛,可能有噪音
最佳实践组合
python# 保守策略:精准优先
topk = 3, score_threshold = 0.7
# 平衡策略:你现在用的
topk = 4, score_threshold = 0.65
# 激进策略:召回优先
topk = 8, score_threshold = 0.5
针对你的情况
建议调整为:
pythontopk = 4 # 保持不变
score_threshold = 0.65 # 新增:过滤掉0.609那个块
元数据过滤(rag优化)
解决块数量过多引发的多跳问题(致命)以及检索效率不高的问题


块重写(rag优化)
无法命中

重写块(或者在数据处理那里进行批量操作或者块重叠)


提高命中块精确度
rag切块问题
假如有这样两个块
一个块为:产品介绍xxx这个产品多么多么好产品名称叫超级无敌旋风相机
另一个块:他的特性是拍照速度特别快而且无限胶卷,非常牛
那么用户问题 超级无敌旋风相机的特点是什么?
在向量数据库块非常多的情况下,大模型可能无法讲两个块的特点关联起来,我的发现对吗?
这是RAG系统中一个非常典型且重要的问题,被称为"信息分散问题"或"上下文割裂问题"。
向量检索时很可能发生:
查询"超级无敌旋风相机的特点"会优先匹配到块1(因为有确切的产品名称)
块2虽然有特性信息,但语义相似度可能不够高,无法被检索到
最终答案不完整或不准确
1.使用土方法重写块,粗暴改写超级无敌旋风相机的特性是拍照速度特别快而且无限胶卷,非常牛
简单直接,工作量大,有时需要python批处理,要注意语义流畅
2.构建知识图谱
3.优化元数据
4.块优化
LLM-RAG项目细节-数据处理、分块..的更多相关文章
- 仿百度壁纸客户端(六)——完结篇之Gallery画廊实现壁纸预览已经项目细节优化
仿百度壁纸客户端(六)--完结篇之Gallery画廊实现壁纸预览已经项目细节优化 百度壁纸系列 仿百度壁纸客户端(一)--主框架搭建,自定义Tab + ViewPager + Fragment 仿百度 ...
- 仿百度壁纸client(六)——完结篇之Gallery画廊实现壁纸预览已经项目细节优化
仿百度壁纸client(六)--完结篇之Gallery画廊实现壁纸预览已经项目细节优化 百度壁纸系列 仿百度壁纸client(一)--主框架搭建,自己定义Tab + ViewPager + Fragm ...
- 学霸数据处理项目之数据处理网页以及后台以及C#代码部分开发者手册
写在前面,本文将详细介绍学霸数据处理项目中的数据处理网页与后台函数,以及c#代码中每一个方法的意义及其一些在运行方面需要注意的细节,供开发人员使用,开发人员在阅读相关方法说明时请参照相关代码,对于本文 ...
- 开发一个微信小程序项目教程
一.注册小程序账号 1.进入微信公众平台(https://mp.weixin.qq.com/),注册小程序账号,根据提示填写对应的信息即可.2.注册成功后进入首页,在 小程序发布流程->小程序开 ...
- 高级软件工程2017第3次作业——结对项目:四则运算题目生成程序(基于GUI)
Deadline:2017-10-11(周三)21:00pm (注:以下内容参考集大作业 ) 前言 想过和别人一起探索世界吗?多么希望,遇到困难时,有人能一起探讨:想要懈怠时,有人推你一把:当你专注于 ...
- 用MVC5+EF6+WebApi 做一个小功能(二) 项目需求整理
在一个项目开始前,需求整理大概要占到整个项目周期15%甚至30%的比重,可以说需求理得越清楚,后续开发中返工几率越小.在一个项目中,开发新功能的花费的精力要远远小于修改功能的精力,这基本是一个共识.老 ...
- erp前端项目总结
目录 一.项目目录(vue-cli2) 二.开发实践 (一) 权限 (二) 各组件间传递数据 (四) 路由 (七) 组织部门业务员三级联动 (八) 优化性能,手动绑定下拉框数据 (九) 验证 (十) ...
- Java-Maven-Runoob:Maven 项目模板
ylbtech-Java-Maven-Runoob:Maven 项目模板 1.返回顶部 1. Maven 项目模板 Maven 使用 archetype(原型) 来创建自定义的项目结构,形成 Mave ...
- Ant Design项目记录和CSS3的总结和Es6的基本总结
这里主要是介绍自己运用ANT框架的一些小总结,以前写到word里,现在要慢慢传上来, 辅助生殖项目总结:从每个组件的运用的方法和问题来总结项目. 1.项目介绍 辅助生殖项目主要运用的是Ant.desi ...
- Storm项目:流数据监控1《设计文档…
博客公告: (1)本博客全部博客文章搬迁至<博客虫>http://blogchong.com/ (2)文章相应的源代码下载链接參考博客虫站点首页的"代码GIT". (3 ...
随机推荐
- MySQL——InnoDB存储引擎
.ibd文件结构 从 MySQL 5.6.6 版本开始,默认一个表是一个.ibd文件,关于表的所有信息都保存在这个文件里.数据库IO操作的基本单位是页,.idb的基本组成也是页,如下图所示,一个.id ...
- CSP-S 2024 游记
上午 上午打板+睡觉.希望能比去年有进步. 下午 下午进考场,好像来早了,一直没见到带考的老师,于是自己先进去了. 鼠标不好用,滚轮坏了,申请换一个.结果更不好用,过一会就卡一下.于是换了个位置,鼠标 ...
- C/C++语言字符串正则匹配问题
30分钟入门博客 http://www.awaysoft.com/regular.htm#mission 可能服务器到期了,说实话自己的博客还是部署到CSDN,博客园之类的好. 测试网页 https: ...
- opengl 学习 之 12 lesson
opengl 学习 之 12 lesson 简介 扩展函数值DEBUG!!! link http://www.opengl-tutorial.org/uncategorized/2017/06/07/ ...
- 金山pdf 阅读 点击链接如何跳转回来
简介 RT ALT + 左箭头
- ETL数据集成丨使用ETLCloud实现MySQL与Greenplum数据同步
我们在进行数据集成时,MySQL和Greenplum是比较常见的两个数据库,我们可以通过ETLCloud数据集成平台,可以快速实现MySQL数据库与数仓数据库(Greenplum)的数据同步. MyS ...
- SciTech-EECS-MCU/CPU: DMA(直接内存访问): 开始时由CPU进行协调配对+传数据时DMA+结束时触发硬件中断通知MCU/CPU并解除配对
MEM可以是: MCU/CPU自带的内存: 容量由"芯片设计师"根据常用场景统计确定大小. 常能满足大多数用途. MCU/CPU的外部内存: 容量由"硬件设计师" ...
- spring-ai 学习系列(2)-调用远程deepseek
上一节学习了spring-ai调用本地ollama,这次继续学习调用远程deepseek 一.pom依赖调整 加入openai的依赖 1 <dependency> 2 <groupI ...
- Rust从入门到精通02-安装
1.安装 Rustup 是rust 官方版本管理工具,安装rustup 会自动安装好 rust(还会自动安装Cargo,这是Rust 的构建系统和包管理器,很重要),所以我们只需要安装 rustup ...
- zephyr学习(立创实战派开发板): 2. zephyr 点灯+串口通信
配置好了zephyr 工作环境就可以开始自己的项目开发了. 参考:应用程序开发 - Zephyr Project Documentation --- Application Development - ...