deepseek-v3.2-exp: 节前发版之打工人的悲鸣
节前发版:Deepseek v3.2 exp
加班快乐...
架构
与Deepseek-V3.1相比,新一般的架构更改仅仅在后续训练中引入了新的稀疏注意力机制DSA。
DSA:deepseek稀疏注意力
主要包括两个部分:一个ligtning indexer(索引器)和一个细粒度的token选择机制。
Lightning indexer
Step 1: 计算索引分数。
计算了 当前询问 Q token \(h_t\in \mathbb{R}^d\) 与一个 前序token \(h_s\in\mathbb{R}^d\) 的索引分数,决定了Qtoken将会选择哪一个token。
\]
其中我们有:
- \(H^I\) 索引头的数目。
- \(q_{t,j}^I\in\mathbb{R}^{d^I}\) 和 \(w_{t,j}^I\in\mathbb{R}\) 从Q token \(h_t\) 中导出。
- \(k_s^I\in R^{d^I}\) 从前序的 \(h_s\) 中导出。
作者选择了ReLU来提升吞吐率。即使lightning indexer仅有很少数量的头并且可以在FP8上部署,其计算效率也是非常显著的。
Step 2: 选择前k个索引分数最高的 \(c_s\), 计算注意力输出。
给定了索引分数 \(I_{t,s}\),我们的细粒度token索引机制将会仅仅取出那些具有前k个索引分数的token。随后,注意力输出 \(o_t\) 将会在当前Q token \(h_t\) 和稀疏化选出的 \(c_s\) 中进行。
\(c_s\) 其实是MLA中低秩投影计算出来的向量,用于减少KVCache的存储开销,提高推理效率。
\]
下面是新旧结构的对比。上图为新的结构。下图为曾经的就结构。
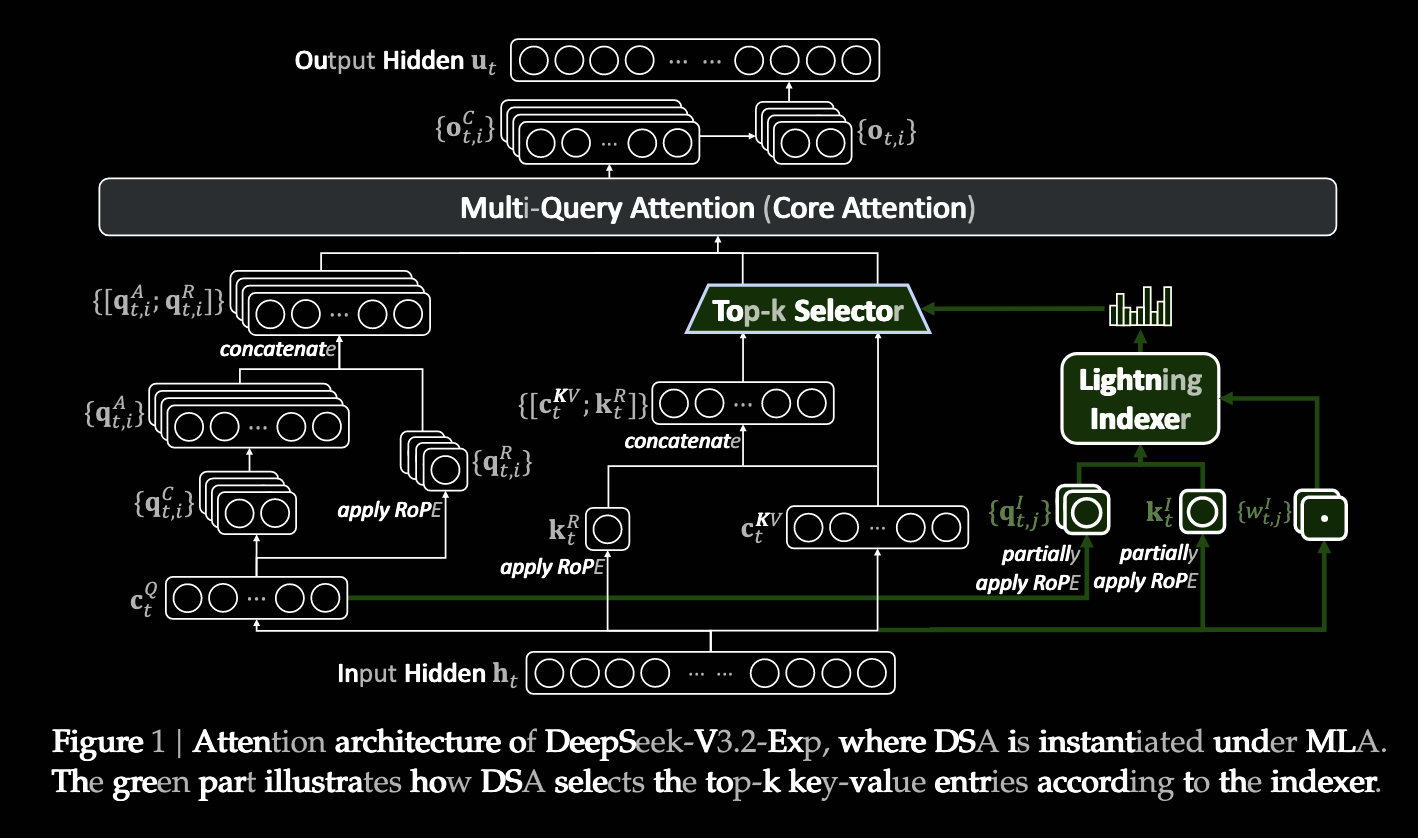
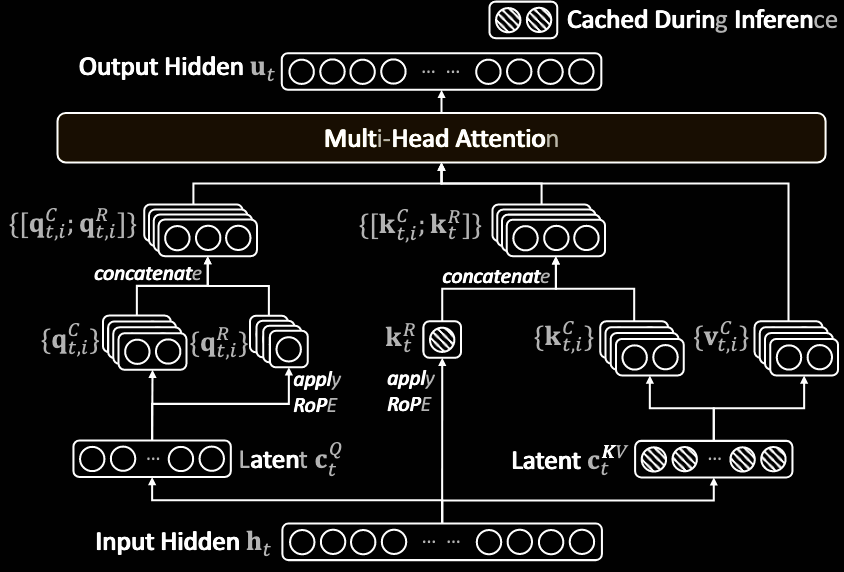
在MLA下实例化DSA
为了考虑从v3.1继续训练,需要基于MLA上实例化DSA。在kernel层面,每一个KV项都需要在多个查询之间共享,提升计算效率。因此,我们在MLA的MQA模式上部署了DSA。这样每一个潜在层(latent vector)将会在每个头之间共享(多个头共用一个潜在向量 \(c_i\))。
训练
从v3.1-Terminus 后继续训练,上下文长度扩展到128K。
Step 1: 稠密 warm-up 阶段
用于初始化lightning indexer。继续保持稠密注意力机制,其余参数全部冻结,仅剩下lightning indexer进行训练。
为了保持indexer输出与原先的主要注意力分布对齐,对于第t个查询token,我们首先将多个头的主要注意力分数进行相加,然后在序列维度上进行 L1-正则化,生成目标分布 \(p_{t,:}\in\mathbb{R}^t\). 基于 \(p_{t,:}\), 我们设置一个 KL-散度 loss作为我们训练indexer的优化目标。
\]
作者声称采用了 \(10^{-3}\) 的学习率训练了1000步。每一步具有128K长度的16个序列,总共2.1B个token。
Step 2: 稀疏训练阶段
在进行稠密训练之后,进入到了细粒度的token选择,并以此来优化整体模型的参数,来获得DSA的稀疏模式。在这一阶段,我们不在选择所有的token,而是通过上文的方式选择通过indexer判断出来的,索引分数最大的K个token:
\(\mathcal{S}_t=\{s\,|\,I_{t,s}\in\text{Top-k}(I_{t,:})\}\)
\]
需要值得注意的是我们将indexer的输入从计算图中分离,也就是分开indexer和DSA的其他部份,分别进行优化。
- indexer仍然仅仅根据 \(\mathcal{L}^I\) 进行优化。
- 其他部分通过模型其他部分的loss进行优化。
稀疏训练采用学习率 \(7.3\times 10^{-6}\),每个query选择2048个KV token。训练15000步,具有480个长度为128K的token,总共是943.7B token数量。
Step 3: 后训练
后训练与先前deepseek-v3的后训练类似,主要有两步:
- 专家知识蒸馏。
- 混合RL训练。
专家知识蒸馏
- 对于每个任务我们都训练了一个专门的针对这个领域知识的模型,这些模型都是从相同的预训练v3.2基座模型的ckpt而来。
- 针对写作任务和通用问答任务,我们划分了5个领域:数学,竞赛类编程,通用因果逻辑,多智能体编码,多智能体搜索。
- 对于每个专家,我们都通过大规模强化学习方式进行训练。
- 并且,我们部署了不同的模型来生成针对思维链(CoT)的训练数据,以及直接回答(非思维链模式)的训练数据。
- 当专家模型完成后,他们将被用于为最后的ckpt生成领域专用的知识。最终ckpt在各个领域与专家模型的差距将通过后续的强化学习来进行弥补。
混合强化学习
- 与v3.1相同,仍然采用的是GRPO强化学习方式。
- 与前面分不同阶段强化学习不同的是,作者将多个阶段的RL学习(因果,智能体,人类对齐训练)混合到了一起。
- 优势是可以讲多个领域的表现有效进行平衡并且设法克服在多阶段训练中造成的灾难性遗忘问题。
- 对于因果和智能体任务,我们部署了基于规则的结果奖励,长度惩罚以及语言一致性奖励。
- 对于生成式任务,我们部署了一个生成式奖励模型,将按照自己的规则进行评估。
- reward进行了两方面的权衡:(1) 长度vs准确度。(2)一致性vs准确度。
评估结果
- 推理开销从原先的 \(O(L^2)\) (原先需要计算所有的 token,长度为 L) 变成 \(O(Lk)\) (Q token长度不变,但是KV低秩投影token通过lightning indexer选择K个)。对于lightning indexer,其计算复杂度仍然为 \(O(L^2)\),但是因为其具有的头数量比原先的MLA头数量少,因此常数因子的减少也显著提升了其计算效率。

deepseek-v3.2-exp: 节前发版之打工人的悲鸣的更多相关文章
- AEAI Portal V3.5.2门户集成平台发版说明
AEAI Portal门户集成平台为数通畅联的核心产品,本着分享传递的理念,数通畅联将Portal_server.Portal_portlet两个项目开源,目的在于满足客户与伙伴的OEM需求,以及为广 ...
- jenkins中通过git发版操作记录
之前说到的jenkins自动化构建发版是通过svn方式,今天这里介绍下通过git方式发本的操作记录. 一.不管是通过svn发版还是git发版,都要首先下载svn或git插件.登陆jenkins,依次点 ...
- php 7 正式发版
php 7 正式发版 php 在 2015年 12月 3 日 正式发布了 php7 以下是php7的新特性 性能是php5.6的2倍 显著的减少了内存的使用 抽象语法书 64位的支持 提高了异常层次 ...
- Database(Mysql)发版控制二
author:skate time:2014/08/18 Database(Mysql)发版控制 The Liquibase Tool related Database 一.Installation ...
- CICD自动化发版系统设计简介
第一篇. 版本迭代是每一个互联网公司必须经历的,尤其是中小型公司,相信不少人踩到过很多坑.接下来的一系列文章将介绍我设计的自动化发版系统! 很多公司没有把配置独立出去,代码的构建.发版通过一个Jenk ...
- java生产环境增量发版陷阱【原】
前言 在生产环境,我们为了降低发版风险,一般都只做增量发布,不做全量发布. 除非项目只有一到两人开发,对时间线和代码脉络结构一清二楚,才可全量发布. 然而增量发布也是有一定隐藏陷阱在里面的,以下就是笔 ...
- 用node.js写一个jenkins发版脚本
背景 每次到网页里手动发版有点烦,写个脚本来提高开发效率. CFG 在 jenkins 设置里获取 API TOKEN. 把 host 和账号密码拼接起来就可以通过鉴权. const token = ...
- Jenkins日常运维笔记-重启数据覆盖问题、迁移、基于java代码发版(maven构建)
之前在公司机房部署了一套jenkins环境,现需要迁移至IDC机房服务器上,迁移过程中记录了一些细节:1)jenkins默认的主目录放在当前用户家目录路径下的.jenkins目录中.如jenkins使 ...
- svn代码发版的脚本分享
背景:开发将其代码放到svn里面,如何将修改后存放到svn里的代码发布到线上?简单做法:写个shell脚本,用于代码发版.比如开发的代码存放svn的路径是:svn://112.168.19.120/h ...
- Android 发版的小工具
Android加固包签名 我们知道自己的apk在上传市场的时候, 为了更好的包含我们的代码需要加固服务, 加固后的apk是不能直接安装的, 需要我们手动签名. 关于Android签名的知识就不在赘述了 ...
随机推荐
- Rust修仙之道 第十二章:宽度境 · 类型尺寸认知与不定形之术
第十二章:宽度境 · 类型尺寸认知与不定形之术 "形有大小,道有边界.不能测其尺者,不可轻控其灵." 当顾行云修炼 Trait 技法至高阶,试图为"无定形灵体" ...
- Luogu P11157 【MX-X6-T3】さよならワンダーランド 题解
P11157 [MX-X6-T3]さよならワンダーランド 神秘思维题. 考虑到转化式子,拆成 \(j\ge a_i\) 和 \(j\le a_{i+j}\).前一个不等式是容易满足的,我们只需要在 \ ...
- SciTech-Mathmatics-Probability+Statistics-IV-Population:Parameter<->Sample:Statistics : Confidence Interval(置信区间)
SciTech-Mathmatics-Probability+Statistics-IV- Population:Parameter<->Sample:Statistics : CI(Co ...
- SciTech-Mathmatics-Physics-Particle Physics-Election+Photon+Quantum: Parallel Universe + Superposition + Wave-Particle Duality.
SciTech-Mathmatics-Quantum LaTex: https://tex.stackexchange.com/questions/483996/automatically-sized ...
- babylon.js 学习笔记(8)
接上回继续,现在的村庄已经有点象样了,但是远处的背景仍比较单调(如下图),今天来学习如何处理天空背景. babylon.js中,把整个空间假象成一个巨大的立方体(称为SkyBox),然后依次给立方体的 ...
- mysql ERROR 1045 (28000): 错误解决办法-九五小庞
找到配置文件my.ini ,然后将其打开,可以选择用记事本打开 打开后,搜索mysqld关键字 找到后,在mysqld下面添加skip-grant-tables,保存退出. PS:若提示不让保 ...
- unity代码编译时间分析工具
https://github.com/needle-tools/compilation-visualizer 工具2 Editor Iteration Profiler (EIP) 地址: https ...
- FFmpeg的安装及简单使用
简介 FFmpeg 是一个跨平台的音视频处理工具库/命令行工具,其核心作用是:对音视频文件或流进行解码.转换(编码).封装/解封装等处理. 友情提示 本次安装以Windows64位操作系统为例 一.下 ...
- CF1922E Increasing Subsequences
一个显然的思路就是构造很多互不相关的上升序列.但是这样构造出来的 \(n\) 是 \(O(\log_2^2 n)\) 量级的,所以需要考虑新做法. 假设我们本来有一个上升序列,我们能否往里面插数?如果 ...
- CloudQuery 社区版重启 | 我们做了哪些准备?
Hello,大家好! 几天前发布的那篇 社区启动预热文章 引起巨大反响,不少社区的小伙伴联系我们,询问这次重启与以往相比有哪些变化,会不会举行发布会之类问题.所以今天我们就来跟大家讲讲我们此次重启的构 ...