论文解读(VGAE)《Variational Graph Auto-Encoders》
Paper Information
Title:Variational Graph Auto-Encoders
Authors:Thomas Kipf, M. Welling
Soures:2016, ArXiv
Others:1214 Citations, 14 References
1 A latent variable model for graph-structured data
VGAE 使用了一个 GCN encoder 和 一个简单的内积 decoder ,架构如下图所示:
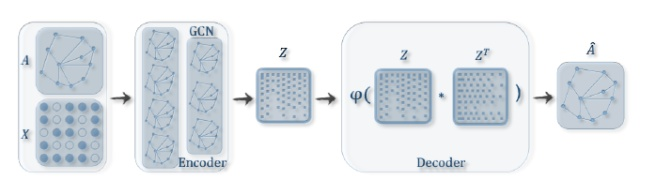
Definitions:We are given an undirected, unweighted graph $\mathcal{G}=(\mathcal{V}, \mathcal{E})$ with $N=|\mathcal{V}|$ nodes. We introduce an adjacency matrix $\mathbf{A}$ of $\mathcal{G}$ (we assume diagonal elements set to $1$ , i.e. every node is connected to itself) and its degree matrix $\mathbf{D}$ . We further introduce stochastic latent variables $\mathbf{z}_{i}$ , summarized in an $N \times F$ matrix $\mathbf{Z}$ . Node features are summarized in an $N \times D$ matrix $\mathbf{X}$ .
Inference model:使用一个两层的 GCN 推理模型
$q(\mathbf{Z} \mid \mathbf{X}, \mathbf{A})=\prod_{i=1}^{N} q\left(\mathbf{z}_{i} \mid \mathbf{X}, \mathbf{A}\right) \text { with } \quad q\left(\mathbf{z}_{i} \mid \mathbf{X}, \mathbf{A}\right)=\mathcal{N}\left(\mathbf{z}_{i} \mid \boldsymbol{\mu}_{i}, \operatorname{diag}\left(\boldsymbol{\sigma}_{i}^{2}\right)\right)$
其中:
- $\boldsymbol{\mu}=\operatorname{GCN}_{\boldsymbol{\mu}}(\mathbf{X}, \mathbf{A})$ is the matrix of mean vectors $\boldsymbol{\mu}_{i} $;
- $\log \boldsymbol{\sigma}=\mathrm{GCN}_{\boldsymbol{\sigma}}(\mathbf{X}, \mathbf{A})$;
def encode(self, x, adj):
hidden1 = self.gc1(x, adj)
return self.gc2(hidden1, adj), self.gc3(hidden1, adj) mu, logvar = self.encode(x, adj)
GCN 的第二层分别输出 mu,log $\sigma$ 矩阵,共用第一层的参数。
这里 GCN 定义为:
$\operatorname{GCN}(\mathbf{X}, \mathbf{A})=\tilde{\mathbf{A}} \operatorname{ReLU}\left(\tilde{\mathbf{A}} \mathbf{X} \mathbf{W}_{0}\right) \mathbf{W}_{1}$
其中:
- $\mathbf{W}_{i}$ 代表着权重矩阵
- $\operatorname{GCN}_{\boldsymbol{\mu}}(\mathbf{X}, \mathbf{A})$ 和 $\mathrm{GCN}_{\boldsymbol{\sigma}}(\mathbf{X}, \mathbf{A})$ 共享第一层的权重矩阵 $\mathbf{W}_{0} $
- $\operatorname{ReLU}(\cdot)=\max (0, \cdot)$
- $\tilde{\mathbf{A}}=\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}$ 代表着 symmetrically normalized adjacency matrix
至于 $z$ 的生成:
def reparameterize(self, mu, logvar):
if self.training:
std = torch.exp(logvar)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu)
else:
return mu z = self.reparameterize(mu, logvar)
Generative model:我们的生成模型是由潜在变量之间的内积给出的:
$p(\mathbf{A} \mid \mathbf{Z})=\prod_{i=1}^{N} \prod_{j=1}^{N} p\left(A_{i j} \mid \mathbf{z}_{i}, \mathbf{z}_{j}\right) \text { with } p\left(A_{i j}=1 \mid \mathbf{z}_{i}, \mathbf{z}_{j}\right)=\sigma\left(\mathbf{z}_{i}^{\top} \mathbf{z}_{j}\right)$
其中:
- $\mathbf{A}$ 是邻接矩阵
- $\sigma(\cdot)$ 是 logistic sigmoid function.
class InnerProductDecoder(nn.Module):
"""Decoder for using inner product for prediction.""" def __init__(self, dropout, act=torch.sigmoid):
super(InnerProductDecoder, self).__init__()
self.dropout = dropout
self.act = act def forward(self, z):
z = F.dropout(z, self.dropout, training=self.training)
adj = self.act(torch.mm(z, z.t()))
return adj self.dc = InnerProductDecoder(dropout, act=lambda x: x) adj = self.dc(z)
Learning:优化变分下界 $\mathcal{L}$ 的参数 $W_i$ :
$\mathcal{L}=\mathbb{E}_{q(\mathbf{Z} \mid \mathbf{X}, \mathbf{A})}[\log p(\mathbf{A} \mid \mathbf{Z})]-\mathrm{KL}[q(\mathbf{Z} \mid \mathbf{X}, \mathbf{A}) \| p(\mathbf{Z})]$
其中:
- $\operatorname{KL}[q(\cdot) \| p(\cdot)]$ 代表着 $q(\cdot)$ 和 $p(\cdot)$ 之间的 KL散度。
- 高斯先验 $p(\mathbf{Z})=\prod_{i} p\left(\mathbf{z}_{\mathbf{i}}\right)=\prod_{i} \mathcal{N}\left(\mathbf{z}_{i} \mid 0, \mathbf{I}\right)$
Non-probabilistic graph auto-encoder (GAE) model
计算表示向量 $Z$ 和重建的邻接矩阵 $\hat{\mathbf{A}}$
$\hat{\mathbf{A}}=\sigma\left(\mathbf{Z Z}^{\top}\right), \text { with } \quad \mathbf{Z}=\operatorname{GCN}(\mathbf{X}, \mathbf{A})$
2 Experiments on link prediction
引文网络中链接预测任务的结果如 Table 1 所示。
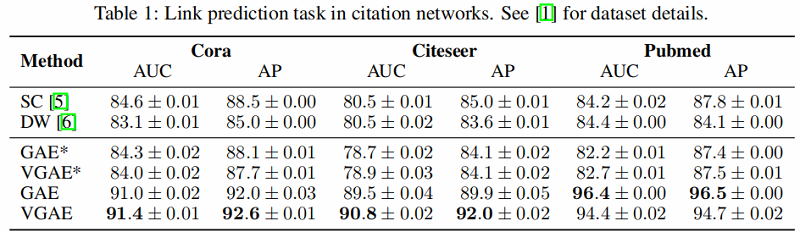
GAE* and VGAE* denote experiments without using input features, GAE and VGAE use input features.
论文解读(VGAE)《Variational Graph Auto-Encoders》的更多相关文章
- 论文解读《Bilinear Graph Neural Network with Neighbor Interactions》
论文信息 论文标题:Bilinear Graph Neural Network with Neighbor Interactions论文作者:Hongmin Zhu, Fuli Feng, Xiang ...
- 论文解读《Cauchy Graph Embedding》
Paper Information Title:Cauchy Graph EmbeddingAuthors:Dijun Luo, C. Ding, F. Nie, Heng HuangSources: ...
- 论文解读(GraphMAE)《GraphMAE: Self-Supervised Masked Graph Autoencoders》
论文信息 论文标题:GraphMAE: Self-Supervised Masked Graph Autoencoders论文作者:Zhenyu Hou, Xiao Liu, Yukuo Cen, Y ...
- 论文解读(KP-GNN)《How Powerful are K-hop Message Passing Graph Neural Networks》
论文信息 论文标题:How Powerful are K-hop Message Passing Graph Neural Networks论文作者:Jiarui Feng, Yixin Chen, ...
- 论文解读(SR-GNN)《Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data》
论文信息 论文标题:Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training Data论文作者:Qi Zhu, ...
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息 论文标题:Learning Graph Augmentations to Learn Graph Representations论文作者:Kaveh Hassani, Amir Hosein ...
- 论文解读(GCC)《Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering》
论文信息 论文标题:Efficient Graph Convolution for Joint Node RepresentationLearning and Clustering论文作者:Chaki ...
- 论文解读(AGC)《Attributed Graph Clustering via Adaptive Graph Convolution》
论文信息 论文标题:Attributed Graph Clustering via Adaptive Graph Convolution论文作者:Xiaotong Zhang, Han Liu, Qi ...
- 论文解读(DGI)《DEEP GRAPH INFOMAX》
论文标题:DEEP GRAPH INFOMAX 论文方向:图像领域 论文来源:2019 ICLR 论文链接:https://arxiv.org/abs/1809.10341 论文代码:https:// ...
随机推荐
- HMS Core助力宝宝巴士为全球开发者展现高品质儿童数字内容
本文分享于HMS Core开发者论坛<宝宝巴士携HMS Core为全球家庭用户提供优质儿童数字内容>采访稿整理 宝宝巴士是国内有着十多年出海经验的开发者,其旗下有超过200多款儿童益智互动 ...
- 使用VMware安装win10虚拟机
(1)打开VMware: (2)打开左上角的文件,点击新建虚拟机: (3)选择典型,下一步: (4)选择稍后安装操作系统,下一步: (5)选择win10×64,下一步: (6)可随意修改虚拟机名称,位 ...
- 我们一起来学Shell - shell的并发及并发控制
文章目录 bash的并发 未使用并发的脚本 简单修改 使用wait命令 控制并发进程的数量 文件描述符 查看当前进程打开的文件 自定义当前进程用描述符号操作文件 管道 我们一起来学Shell - 初识 ...
- jenkins pipeline构建项目
以前用的jenkins自由风格发布代码.界面丑陋,出现问题位置不够清晰.今天改进一下流程使用jenkins pipeline构建项目. 学习使我快乐 步骤一.安装pipeline插件 点击系统管理-& ...
- 『德不孤』Pytest框架 — 4、Pytest跳过测试用例
目录 1.无条件跳过skip 2.有条件跳过skipif 3.练习 自动化测试执行过程中,我们常常出现这种情况:因为功能阻塞,未实现或者环境有问题等等原因,一些用例执行不了, 如果我们注释掉或删除掉这 ...
- IGMP协议测试-网络测试仪实操
一.前言:IGMP协议用于IPv4系统向任何邻居组播路由器报告其组播成员资格.IP组播路由器自己本身也可以是一到多个组播组的成员.这时,组播路由器要实现协议的组播路由器部分. IGMP存在三个不同版本 ...
- RHEL6搭建网络yum源仓库
RHEL的更新包只对注册用户生效,所以需要自己手动改成Centos的更新包 一.查看rhel本身的yum安装包 rpm -qa | grep yum 二.卸载这些软件包 rpm -qa | grep ...
- 【计算机基础】IL代码-CLR平台上的字节码【什么是字节码?它与虚拟机的关系?】
字节码(英语:Bytecode)将虚拟机可以读懂的代码称之为字节码.将源码编译成虚拟机读的懂的代码,需要虚拟机转译后才能成为机器代码的中间代码 叫做字节码. 字节码主要为了实现特定软件运行和软件环境. ...
- 【windows 操作系统】什么是窗口?|按钮也是窗口
起因 在看操作系统消息机制的时候,看到一句化:全局消息队列把消息发送到窗口所在的线程消息队列.突然就怀疑起了窗口的意思.于是就有这边基类. 文章来源:https://docs.microsoft.co ...
- 『无为则无心』Python日志 — 65、日志模块logging的使用
目录 1.logger类用法 2.handler类用法 3.formatter类用法 4.filter类用法 1.logger类用法 logger类:logger用于提供日志接口,常用于配置和发送日志 ...