TF-IDF定义及实现
TF-IDF定义及实现
定义
TF-IDF的英文全称是:Term Frequency - Inverse Document Frequency,中文名称词频-逆文档频率,常用于文本挖掘,资讯检索等应用,在nlp以及推荐等领域都是一个常用的指标,用于衡量字词的重要性。比较直观的解释是,如果一个词本来出现的频率就很高,如the,那么它就几乎无法带给读者一些明确的信息。一般地,以TF-IDF衡量字词重要性时,某个字词在某个文档中出现的频率越高,那么该字词对该文档就有越大的重要性,它可能会是文章的关键词;但若字词在词库中出现的频率越高,那么字词的重要性越低,如the。
计算公式
\]
TF-IDF即是两者相乘,词频乘以逆文档频率。
\]
下标i,j的含义:编号为j的文档中的词语i在该文档中的词频,即所占比例,n为该词语的数量。
\]
N是文档总数,$ N_i $ 表示文档集中包含了词语i的文档数。对分子分母加一是为了避免某些词语未在文档中出现过导致的分母为零的情况。IDF针对某个词计算了它的逆文档频率,即包含该词语的文档比例的倒数(再取对数),若IDF值越小,分母越大,说明这个词语在文档集中比较常见不具有鲜明的信息代表性,TF-IDF的值就小。总之TF-IDF的值我们通常希望它越大越好,大值代表性强。
实现
1. 数据定义预处理
import numpy as np
import pandas as pd
doc1 = "The cat sat on my bed"
doc2 = "The dog sat on my keens"
#构建词库
wordSet = set(doc1.split()).union(set(doc2.split()))#union是并集操作
wordSet

2. 统计词频
dict1 = dict.fromkeys(wordSet, 0)
dict2 = dict.fromkeys(wordSet, 0)
for word in doc1.split():
dict1[word]+=1
for word in doc2.split():
dict2[word]+=1
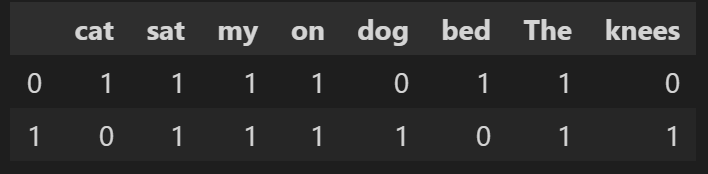
pd.DataFrame([wordDictA, wordDictB])
3. 计算词频 TF,对单个文档统计
def computeTF(wordDict, doc):
sumCount = len(doc.split())
tfDict = dict()
for word, count in wordDict:
dict[word] = count / sumCount
return tfDict
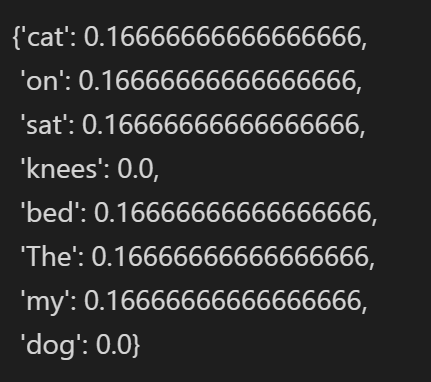
tf1 = computeTF(dict1, doc1)
tf2 = computeTF(dict2, doc2)
4.逆文档频率IDF, 全局只有一份逆文档频率,对所有文档统计
def computeIDF(dicts, wordSet):
"""传入的是文档的字典集和词库,即全部文档"""
docNum = len(docs) #文档总数
#对每个词语查看有几个文档包含它
IDFDict = dict.fromkeys(wordSet, 0)
for word in wordSet:
for _dict in dicts:
IDFDict[word] += (_dict[word] > 0)#该文档中有这个词就加1
for word, idf in IDFDict:
IDFDict[word] = math.log10((docNum + 1) / (IDFDict[word] + 1))
return IDFDict
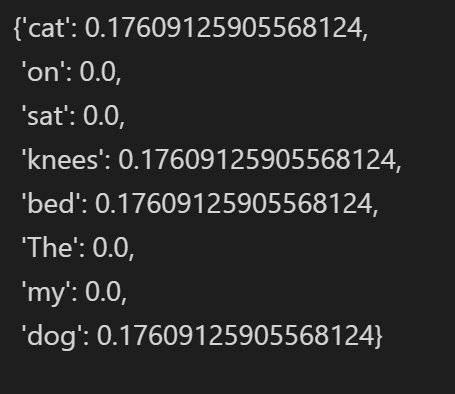
IDF = computeIDF([dict1, dict2], wordSet)
IDF
5.最终计算
def computeTFIDF( tf, idfs ):
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
tfidf1 = computeTFIDF( tf1, idf )
tfidf2 = computeTFIDF( tf2, idf )

可以看到由于单词The,dog,my,on,set在两个文档中都存在故TF-IDF值为0,而其他单词因为具有一定的分辨能力,所以TF-IDF有一定的数值可以用来分辨两句话。
以上内容参考自视频B站,点击即可前往。
TF-IDF定义及实现的更多相关文章
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 使用solr的函数查询,并获取tf*idf值
1. 使用函数df(field,keyword) 和idf(field,keyword). http://118.85.207.11:11100/solr/mobile/select?q={!func ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
随机推荐
- c# 连接SQLite 查询数据 写入txt文本
using Newtonsoft.Json.Linq; using System; using System.Data.SQLite; using System.IO; namespace @publ ...
- java获取当前类的绝对路径
转自: http://blog.csdn.net/elina_1992/article/details/47419097 1.如何获得当前文件路径 常用: (1).Test.class.getRe ...
- JSP中动态include和静态include的区别
a.静态include:语法:<%@ include file="文件名" %>,相当于复制,编辑时将对应的文件包含进来,当内容变化时,不会再一次对其编译,不易维护. ...
- porps传参
porps传参(最常用的 布尔传值)(基于前面的步骤进行修改) ①index.js //定义动态路由 props:trueconst routes =[ {path:"/user/:id/: ...
- 【javascript】chormeV8源码阅读之 GC(垃圾回收)过程 笔记
1.为何需要垃圾回收 在V8引擎逐行执行JavaScript代码的过程中,当遇到函数的情况时,会为其创建一个函数执行上下文(Context)环境并添加到调用堆栈的栈顶,函数的作用域(handl ...
- 数据库结构差异比较-SqlServer
/****** Object: StoredProcedure [dbo].[p_comparestructure_2005] Script Date: 2022/10/8 10:00:20 **** ...
- 火狐浏览器调试eval源码
火狐浏览器调试eval源码 firefox浏览器在网页调试上,有一个没法和chrome一比高下的功能,就是eval脚本的调试,有时前端架构使用了基于eval的方式,有时候可能是自己一个多行函数,每每遇 ...
- https传输流程(加密方式、证书、传输安全)
http的缺点 http的数据是明文传输 如果用明文传输 很容易被第三方获取到传输的数据 因此我们一般要在网络传输过程中对数据进行加密 常见的加密方式 对称加密 秘钥key 待加密数据data a和b ...
- centos7开放8080端口
1. firewall-cmd --state :令防火墙处于开启状态 systemctl start firewalld.service: 2. firewall-cmd --zone=publi ...
- 使用vite创建vue3 遇到 process is not defined
今天新建项目遇到报错,查资料得出,需要在vite.config.js中添加代码如下 import { defineConfig } from 'vite' import vue from '@vite ...