TF-IDF定义及实现
TF-IDF定义及实现
定义
TF-IDF的英文全称是:Term Frequency - Inverse Document Frequency,中文名称词频-逆文档频率,常用于文本挖掘,资讯检索等应用,在nlp以及推荐等领域都是一个常用的指标,用于衡量字词的重要性。比较直观的解释是,如果一个词本来出现的频率就很高,如the,那么它就几乎无法带给读者一些明确的信息。一般地,以TF-IDF衡量字词重要性时,某个字词在某个文档中出现的频率越高,那么该字词对该文档就有越大的重要性,它可能会是文章的关键词;但若字词在词库中出现的频率越高,那么字词的重要性越低,如the。
计算公式
\]
TF-IDF即是两者相乘,词频乘以逆文档频率。
\]
下标i,j的含义:编号为j的文档中的词语i在该文档中的词频,即所占比例,n为该词语的数量。
\]
N是文档总数,$ N_i $ 表示文档集中包含了词语i的文档数。对分子分母加一是为了避免某些词语未在文档中出现过导致的分母为零的情况。IDF针对某个词计算了它的逆文档频率,即包含该词语的文档比例的倒数(再取对数),若IDF值越小,分母越大,说明这个词语在文档集中比较常见不具有鲜明的信息代表性,TF-IDF的值就小。总之TF-IDF的值我们通常希望它越大越好,大值代表性强。
实现
1. 数据定义预处理
import numpy as np
import pandas as pd
doc1 = "The cat sat on my bed"
doc2 = "The dog sat on my keens"
#构建词库
wordSet = set(doc1.split()).union(set(doc2.split()))#union是并集操作
wordSet

2. 统计词频
dict1 = dict.fromkeys(wordSet, 0)
dict2 = dict.fromkeys(wordSet, 0)
for word in doc1.split():
dict1[word]+=1
for word in doc2.split():
dict2[word]+=1
pd.DataFrame([wordDictA, wordDictB])
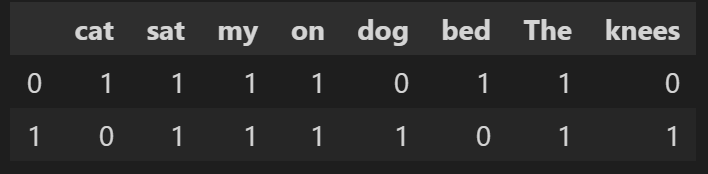
3. 计算词频 TF,对单个文档统计
def computeTF(wordDict, doc):
sumCount = len(doc.split())
tfDict = dict()
for word, count in wordDict:
dict[word] = count / sumCount
return tfDict
tf1 = computeTF(dict1, doc1)
tf2 = computeTF(dict2, doc2)
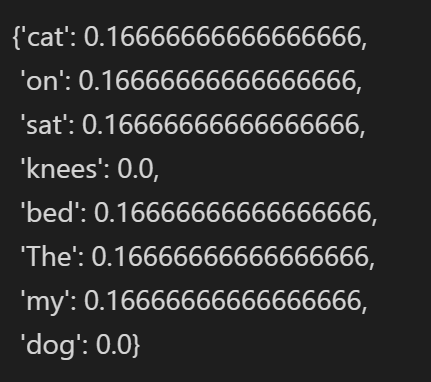
4.逆文档频率IDF, 全局只有一份逆文档频率,对所有文档统计
def computeIDF(dicts, wordSet):
"""传入的是文档的字典集和词库,即全部文档"""
docNum = len(docs) #文档总数
#对每个词语查看有几个文档包含它
IDFDict = dict.fromkeys(wordSet, 0)
for word in wordSet:
for _dict in dicts:
IDFDict[word] += (_dict[word] > 0)#该文档中有这个词就加1
for word, idf in IDFDict:
IDFDict[word] = math.log10((docNum + 1) / (IDFDict[word] + 1))
return IDFDict
IDF = computeIDF([dict1, dict2], wordSet)
IDF
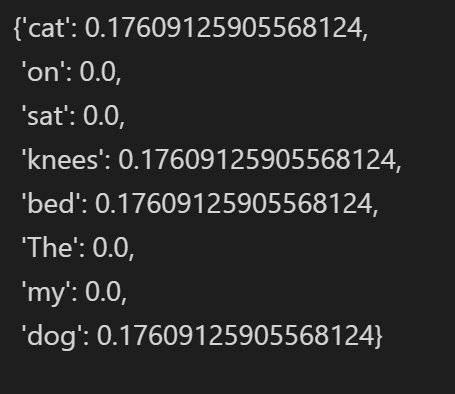
5.最终计算
def computeTFIDF( tf, idfs ):
tfidf = {}
for word, tfval in tf.items():
tfidf[word] = tfval * idfs[word]
return tfidf
tfidf1 = computeTFIDF( tf1, idf )
tfidf2 = computeTFIDF( tf2, idf )

可以看到由于单词The,dog,my,on,set在两个文档中都存在故TF-IDF值为0,而其他单词因为具有一定的分辨能力,所以TF-IDF有一定的数值可以用来分辨两句话。
以上内容参考自视频B站,点击即可前往。
TF-IDF定义及实现的更多相关文章
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 使用solr的函数查询,并获取tf*idf值
1. 使用函数df(field,keyword) 和idf(field,keyword). http://118.85.207.11:11100/solr/mobile/select?q={!func ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
随机推荐
- idea鼠标光标变黑块
在编辑文档和在编程时经常敲着敲着竖线就变成了黑块,这样输入新的代码就会改变其他代码,这是因为输入方式改成了改写模式 只要按fn+insert就可以解决了 搜索 复制
- CMake指定的任务可执行文件"cmd.exe" 未能运行。System.IO.IOException:未能创建临时文件。临时文件夹已满或其路径不正确。对路径"......exec.cmd "的访问被拒绝
我觉得是我使用VS2022的原因,网上也没有找到相同的问题.
- CentOS7带图形界面不能扫描网卡。
CentOS7在带有图形界面,在配置/sysconfig/network-script/ifcfg-ens*后不能识别到网卡,有可能是NetworkManager打开导致,可以使用systemctl ...
- sql运算符优先级
1.() 2.* / % 3.+正 -负 + - +连接(字符串) 4.= > < >= <= <> != !> !< 5.not 6.and 7.b ...
- Httpt请求
在c#中常见发送http请求的方式如下 HttpWebRequest: .net 平台原生提供,这是.NET创建者最初开发用于使用HTTP请求的标准类.使用HttpWebRequest可以让开发者控制 ...
- 【javascript】export 与 export default 区别
总是记不得,自己打一遍 通过export方式导出,在导入时要加{ },export default则不需要,因为它本身只能有一个
- python&C++区别
1.类的定义 struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), ne ...
- 火狐浏览器调试eval源码
火狐浏览器调试eval源码 firefox浏览器在网页调试上,有一个没法和chrome一比高下的功能,就是eval脚本的调试,有时前端架构使用了基于eval的方式,有时候可能是自己一个多行函数,每每遇 ...
- mysql error Code 1441:datetime function: datetime field overflow
mysql error Code 1441:datetime function: datetime field overflow 网上找了好久,也没有解决 最后发现有个left join 表,on关 ...
- 如何加密一个sheel脚本!
脚本写完后,如果要发布给其它人使用的话,可能会因安全原因而受阻,特别是脚本中包含密码等原因,而对脚本加密则可以解决此问题,本文提供了CentOS7/8环境下,加密shell脚本需要安装的程序和方法. ...