【python】M3U8下载器脚本
【python】M3U8下载器脚本
脚本目标:
1. 输入M3U8文件的链接,得到视频
2.使用异步操作,这样可以快很多,不加锁,因为懒得写,而且影响不大
已知条件:
1.m3u8文件其实就是一个记录了ts文件下载链接的工具文件,每个ts文件就是视频的一部分,把所有ts文件下载下来,合并就可以得到完整的视频
脚本思路:
1.创建一个文件夹,用来存放下载好的m3u8文件和下载好的ts文件
2.下载并打开m3u8文件,根据m3u8文件下载ts文件,这边设计了两种情况,a.ts的下载链接是完整的 b.ts的下载链接是需要拼接的
3.根据m3u8文件自动校验文件是否下载完整
4.由于很多时候ts文件的命名是没有规律的,所以再次打开m3u8文件,根据里面的顺序,以追加的形式写入到一个新的ts文件里
代码实现:
先创建好文件夹,这边使用了相对路径
def init():
if os.path.exists("./temp_data"):
return
else:
os.mkdir("./temp_data")
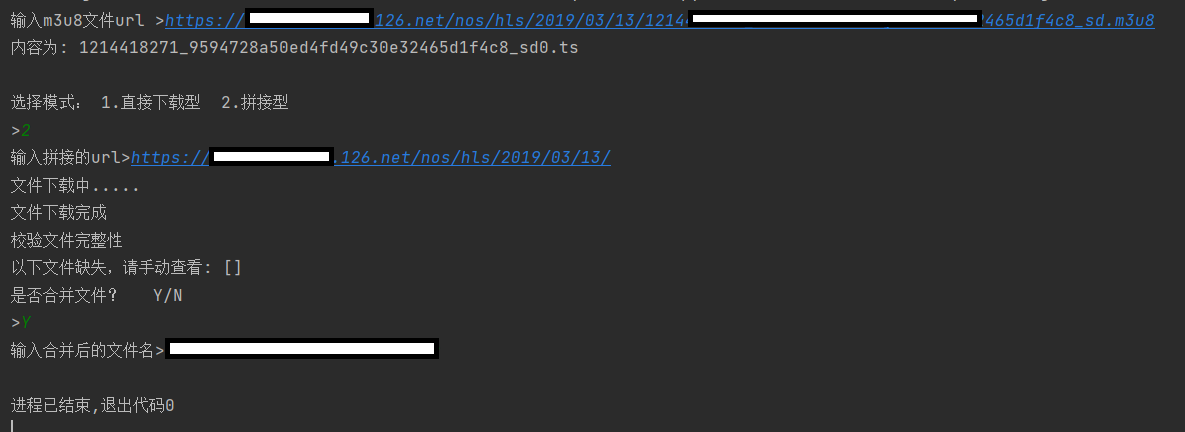
得到m3u8下载链接,获得m3u8文件名,这边假设是https://xxxxxxx126.net/nos/hls/2019/03/13/1214418271_9xxxxxxx32465d1f4c8_sd.m3u8,那么就设置“1214418271_9xxxxxxx32465d1f4c8_sd.m3u8”为文件名
url =str(input("输入m3u8文件url >"))
name = url.rsplit("/")[-1]
下载m3u8文件
def m3u8_files_download(url,name): #下载m3u8文件
resp = requests.get(url)
with open(f"temp_data/{name}.txt",mode="wb") as f:
f.write(resp.content)
resp.close()
给出第一个ts的下载链接,用户自己判断一下是需要拼接的,还是无需拼接的完整url
def get_type(name):
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
print("内容为:",line)
print("选择模式: 1.直接下载型 2.拼接型")
choice = input(">")
return str(choice)
写一个启动器,根据不同的选择,创建不同的任务,创建的任务为异步任务
async def starter(choice,name):
tasks=[]
async with aiohttp.ClientSession() as session:
if choice =="1":
with open(f"/temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
download_url = line.strip()
line = line.split("/")
file_name = str(line[-1]).strip() # 得下载的ts文件名
task = download_ts(file_name,download_url,session)
tasks.append(task)
print("文件下载中.....")
await asyncio.wait(tasks) # 等待任务执行结束
print("文件下载完成")
if choice=="2":
url = str(input("输入拼接的url>"))
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
line = line.strip()
file_name = line # 得下载的ts文件名
download_url = url+line
task = download_ts(file_name,download_url,session)
tasks.append(task)
print("文件下载中.....")
await asyncio.wait(tasks) # 等待任务执行结束
print("文件下载完成")
下载ts文件,用aiohttp来代理requests
async def aio_download_ts(download_url,line_name,session):
async with session.get(download_url,headers=header) as resp:
async with aiofiles.open(f"temp_data/{line_name}",mode="wb") as f:
await f.write(await resp.content.read())
print(f"文件{line_name}下载完成!!")
校验文件的完整性:依据m3u8文件,判断文件是否存在
def verification(name):
files=[]
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
line=line.strip()
if os.path.exists(f"temp_data/{line}"):
continue
else:
files.append(line)
print("以下文件缺失,请手动查看:",files)
合并文件,实现的方式时创建一个ts文件,依据m3u8文件里的文件顺序,依次将二进制文件写入到新的ts文件里
def merge_ts(file_name):
new_name = str(input("输入合并后的文件名>"))
with open(f"./{new_name}.ts", "ab+") as f:
with open(f"temp_data/{file_name}.txt","r") as f2:
for line in f2:
if line.startswith("#"):
continue
else:
line = line.strip().split("/")[-1].strip()
ts_name = line
try:
with open(f"temp_data/{ts_name}","rb") as f3:
f.write(f3.read())
except:
continue
最后再写一个主函数,执行这一切
def main():
init()
url =str(input("输入m3u8文件url >"))
name = url.rsplit("/")[-1]
m3u8_files_download(url,name)#下载m3u8文件
choice=get_type(name)
asyncio.run(starter(choice,name))
print("校验文件完整性")
verification(name)
print("是否合并文件? Y/N")
if str(input(">"))=="Y":
merge_ts(name)
else:
print("结束")
最终功能代码
import aiohttp
import aiofiles
import asyncio
import requests
import os
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36"}
def merge_ts(file_name):
new_name = str(input("输入合并后的文件名>"))
with open(f"./{new_name}.ts", "ab+") as f:
with open(f"temp_data/{file_name}.txt","r") as f2:
for line in f2:
if line.startswith("#"):
continue
else:
line = line.strip().split("/")[-1].strip()
ts_name = line
try:
with open(f"temp_data/{ts_name}","rb") as f3:
f.write(f3.read())
except:
continue
async def aio_download_ts(download_url,line_name,session):
async with session.get(download_url,headers=header) as resp:
async with aiofiles.open(f"temp_data/{line_name}",mode="wb") as f:
await f.write(await resp.content.read())
print(f"文件{line_name}下载完成!!")
def m3u8_files_download(url,name): #下载m3u8文件
resp = requests.get(url)
with open(f"temp_data/{name}.txt",mode="wb") as f:
f.write(resp.content)
resp.close()
def get_type(name):
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
print("内容为:",line)
print("选择模式: 1.直接下载型 2.拼接型")
choice = input(">")
return str(choice)
def init():
if os.path.exists("./temp_data"):
return
else:
os.mkdir("./temp_data")
def verification(name):
files=[]
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
line=line.strip()
if os.path.exists(f"temp_data/{line}"):
continue
else:
files.append(line)
print("以下文件缺失,请手动查看:",files)
async def download_ts(file_name,download_url,session): async with session.get(download_url,headers=header) as resp:
async with aiofiles.open(f"temp_data/{file_name}",mode="wb") as f:
await f.write(await resp.content.read()) async def starter(choice,name):
tasks=[]
async with aiohttp.ClientSession() as session:
if choice =="1":
with open(f"/temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
download_url = line.strip()
line = line.split("/")
file_name = str(line[-1]).strip() # 得下载的ts文件名
task = download_ts(file_name,download_url,session)
tasks.append(task)
print("文件下载中.....")
await asyncio.wait(tasks) # 等待任务执行结束
print("文件下载完成")
if choice=="2":
url = str(input("输入拼接的url>"))
with open(f"temp_data/{name}.txt","r") as f:
for line in f:
if line.startswith("#"):
continue
else:
line = line.strip()
file_name = line # 得下载的ts文件名
download_url = url+line
task = download_ts(file_name,download_url,session)
tasks.append(task)
print("文件下载中.....")
await asyncio.wait(tasks) # 等待人物执行结束
print("文件下载完成") def main():
init()
url =str(input("输入m3u8文件url >"))
name = url.rsplit("/")[-1]
m3u8_files_download(url,name)#下载m3u8文件
choice=get_type(name)
asyncio.run(starter(choice,name))
print("校验文件完整性")
verification(name)
print("是否合并文件? Y/N")
if str(input(">"))=="Y":
merge_ts(name)
else:
print("结束")
main()
使用自欺欺人术,直接把ts文件后缀改成MP4,看着舒服点。
实现效果

视频打开能正常观看,脚本完成
后记:关于脚本的使用
理论上把aiohttp,aiofiles,asyncio三个库安装好,复制粘贴应该就可以直接用,也可以把一些需要手工提供的量,在脚本中写死,以在不同的爬虫中使用。
ENDING..........
【python】M3U8下载器脚本的更多相关文章
- 以下三种下载方式有什么不同?如何用python模拟下载器下载?
问题始于一个链接https://i1.pixiv.net/img-zip-...这个链接在浏览器打开,会直接下载一个不完整的zip文件 但是,使用下载器下载却是完整文件 而当我尝试使用python下载 ...
- python动态视频下载器
这里向大家分享一下python爬虫的一些应用,主要是用爬虫配合简单的GUI界面实现视频,音乐和小说的下载器.今天就先介绍如何实现一个动态视频下载器. 爬取电影天堂视频 首先介绍的是python爬取电影 ...
- 用python实现的百度音乐下载器-python-pyqt-改进版
之前写过一个用python实现的百度新歌榜.热歌榜下载器的博文,实现了百度新歌.热门歌曲的爬取与下载.但那个采用的是单线程,网络状况一般的情况下,扫描前100首歌的时间大概得到40来秒.而且用Pyqt ...
- Python实现多线程HTTP下载器
本文将介绍使用Python编写多线程HTTP下载器,并生成.exe可执行文件. 环境:windows/Linux + Python2.7.x 单线程 在介绍多线程之前首先介绍单线程.编写单线程的思路为 ...
- 用 python 实现一个多线程网页下载器
今天上来分享一下昨天实现的一个多线程网页下载器. 这是一个有着真实需求的实现,我的用途是拿它来通过 HTTP 方式向服务器提交游戏数据.把它放上来也是想大家帮忙挑刺,找找 bug,让它工作得更好. k ...
- [python]非常小的下载图片脚本(非通用)
说在最前面:这不是一个十分通用的下载图片脚本,只是根据我的一个小问题,为了减少我的重复性工作写的脚本. 问题 起因:我的这篇博文什么是真正的程序员浏览量超过了4000+. 问题来了:里面的图片我都是用 ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python实战:美女图片下载器,海量图片任你下载
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- python多进程断点续传分片下载器
python多进程断点续传分片下载器 标签:python 下载器 多进程 因为爬虫要用到下载器,但是直接用urllib下载很慢,所以找了很久终于找到一个让我欣喜的下载器.他能够断点续传分片下载,极大提 ...
随机推荐
- vscode golang 不能自动补全问题
问题描述: 使用vscode编辑go语言时,有时候会莫名其妙的代码不能自动补全,struct的属性值不能自动提示,这时候如果重新启动vscode也没有效果,就可能是gocode插件出了问题或者有了更新 ...
- 【Git】一台电脑与多个分布式版本管理平台连接
六. 一台电脑与多个版本控制平台 1. 一台电脑同时通过ssh连接github和码云gitee 打开git bash 进入.ssh cd ~/.ssh 分别生成两个平台的公钥和私钥 $ ssh-key ...
- 基于SqlSugar的数据库访问处理的封装,支持.net FrameWork和.net core的项目调用
由于我们有时候需要在基于.net framework的项目上使用(如Winform端应用),有时候有需要在.net core的项目上使用(如.net core的WebAPI),那么我们把基于SQLSu ...
- 三个小项目入门Go语言|字节青训营笔记
前言 这是青训营的第一课,今天的课程比较快速的讲解了go语言的入门,并配合三个小的项目实践梳理所学知识点,这里详细回顾一下这三个项目,结合课后作业要求做一些代码补充,并附上自己的分析,青训期间的所有课 ...
- 归约与分组 - 读《Java 8实战》
区分Collection,Collector和collect 代码中用到的类与方法用红框标出,可从git库中查看 收集器用作高级归约 // 按货币对交易进行分组 Map<Currency, Li ...
- linux篇-公司网络故障那些事(路由器变交换机)
首先这次网络故障是断电引起的 我给大家画个模型 三层的为八口交换机 一层的为五口打印机 笔记本代表两台无线打印机 首先八口的连接了公司采购电脑一台,业务电脑一台,其他电脑三台 第二个五口交换的连接财务 ...
- Vue关闭语法检测
为什么?为了防止写到一半保存,报错.关闭默认的语法检测 新建vue.config.js 1.vue.config.js的作用是允许你修改脚手架中wekpack的默认参数. 2.vue.config.j ...
- .net6.0 中一个接口多个实现的服务注册与注入
1.现有一个数据库操作接口 如下 它有两个数据操作实现 Sqlserver 和MySql的数据库操作实现类 现在我们需要 将这个两个类 注册到MVC中 注意这里注册的服务类型都是 IDataBas ...
- 「ARC 139F」Many Xor Optimization Problems【线性做法,踩标】
「ARC 139F」Many Xor Optimization Problems 对于一个长为 \(n\) 的序列 \(a\),我们记 \(f(a)\) 表示从 \(a\) 中选取若干数,可以得到的最 ...
- Python数据分析--Numpy常用函数介绍(6)--Numpy中矩阵和通用函数
在NumPy中,矩阵是 ndarray 的子类,与数学概念中的矩阵一样,NumPy中的矩阵也是二维的,可以使用 mat . matrix 以及 bmat 函数来创建矩阵. 一.创建矩阵 mat 函数创 ...