关于 CMS 垃圾回收器,你真的懂了吗?

大家好,我是树哥。
前段时间有个小伙伴去面试,被问到了 CMS 垃圾回收器的详细内容,没答出来。实际上,CMS 垃圾回收器是回收器历史上很重要的一个节点,其开启了 GC 回收器关注 GC 停顿时间的历史。今天,就让树哥带你一起来学一波吧!
CMS 回收器的历史
如果你是一个比较资深的 Java 开发者,那你或许会对 CMS 垃圾回收器嗤之以鼻,然后说一句:CMS 垃圾回收器早就过时了,现在都流行 G1、ZGC 垃圾回收器了!学这个东西一点用都没有!
确实如资深开发者所说,现在 CMS 垃圾回收器是比较过时的配置了。CMS 垃圾回收器于 JDK1.5 时期推出,在 JDK9 中被废弃,在 JDK14 中被移除。 而用来替换 CMS 垃圾回收器的便是我们常说的 G1 垃圾回收器。
但 G1 垃圾回收器也是在 CMS 的基础上进行改进的,因此简单了解下 CMS 垃圾回收器也是有必要的。
CMS 回收器简介
CMS(Concurrent Mark Sweep)垃圾回收器是第一个关注 GC 停顿时间的垃圾收集器。 在这之前的垃圾回收器,要么就是串行垃圾回收方式,要么就是关注系统吞吐量。这样的垃圾回收器对于强交互的程序很不友好,而 CMS 垃圾回收器的出现,则打破了这个尴尬的局面。因此,CMS 垃圾回收器诞生之后就受到了大家的欢迎,导致现在还有非常多的应用还在继续使用它。
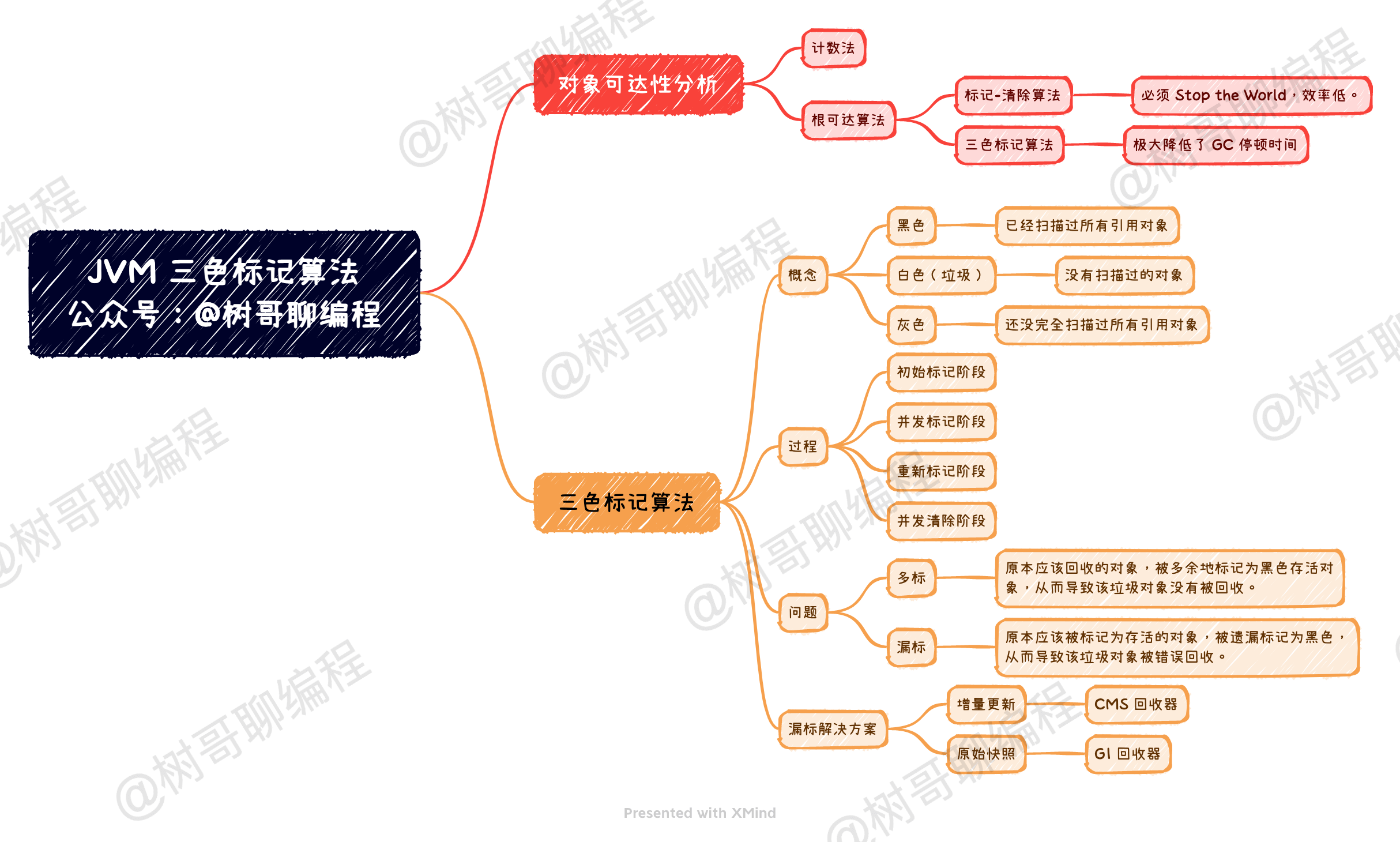
CMS 垃圾回收器之所以能够实现对 GC 停顿时间的控制,其本质来源于对「根可达算法」的改进,即三色标记算法。在 CMS 垃圾回收器出现之前,无论是 Serious 垃圾回收器,还是 ParNew 垃圾回收器,亦或是 Parallel Scavenge 垃圾回收器,他们在进行垃圾回收的时候都需要 Stop the World,即无法实现垃圾回收线程与用户线程并发执行。而 CMS 垃圾回收器通过三色标记算法,实现了垃圾回收线程与用户线程并发执行,从而极大地降低了系统响应时间,提高了强交互应用程序的体验。
对于 CMS 垃圾回收器来说,其实通过「标记-清除」算法实现的,它的运行过程分为 4 个步骤,包括:
- 初始标记
- 并发标记
- 重新标记
- 并发清除
初始标记,指的是寻找所有被 GCRoots 引用的对象,该阶段需要「Stop the World」。 这个步骤仅仅只是标记一下 GC Roots 能直接关联到的对象,并不需要做整个引用的扫描,因此速度很快。
并发标记,指的是对「初始标记阶段」标记的对象进行整个引用链的扫描,该阶段不需要「Stop the World」。 对整个引用链做扫描需要花费非常多的时间,因此通过垃圾回收线程与用户线程并发执行,可以降低垃圾回收的时间,从而降低系统响应时间。这也是 CMS 垃圾回收器能极大降低 GC 停顿时间的核心原因,但这也带来了一些问题,即:并发标记的时候,引用可能发生变化,因此可能发生漏标(本应该回收的垃圾没有被回收)和多标(本不应该回收的垃圾被回收)了。
重新标记,指的是对「并发标记」阶段出现的问题进行校正,该阶段需要「Stop the World」。 正如并发标记阶段说到的,由于垃圾回收算法和用户线程并发执行,虽然能降低响应时间,但是会发生漏标和多标的问题。所以对于 CMS 回收器来说,它需要这个阶段来做一些校验,解决并发标记阶段发生的问题。
并发清除,指的是将标记为垃圾的对象进行清除,该阶段不需要「Stop the World」。 在这个阶段,垃圾回收线程与用户线程可以并发执行,因此并不影响用户的响应时间。

从上面的描述步骤中我们可以看出:CMS 之所以能极大地降低 GC 停顿时间,本质上是将原本冗长的引用链扫描进行切分。通过 GC 线程与用户线程并发执行,加上重新标记校正的方式,减少了垃圾回收的时间。
CMS 回收器优缺点
从上面的描述我们可以知道,CMS 回收器的优点是:并发收集垃圾、低停顿。但其也有下面几个明显的缺点:
对 CPU 资源消耗较大。 CMS 回收器在并发标记和并发清理阶段,是需要启用多个线程进行处理的,这就意味着它需要占用一部分线程资源,即 CPU 资源。默认情况下 CMS 启用的垃圾回收线程数是(CPU数量 + 3)/4,当 CPU 数量越大时,启用的垃圾回收线程数占比就越小。
但如果 CPU 数量越小,例如只有 2 个 CPU 时,垃圾回收线程占用就达到了 50%,也就是说需要拿 50% 的 CPU 时间来进行垃圾回收。这就会极大地降低系统的吞吐量,这是让人无法接受的情况。
无法处理浮动垃圾。 由于 CMS 并发标记阶段会发生漏标的情况,因此会有一些本该回收的垃圾对象无法被回收。此外,在 CMS 进行并发清理的时候,用户线程同时在运行,也会产生一些浮动垃圾。因此对于 CMS 回收器来说,其需要留出一些空间给这些浮动垃圾存储。
在 JDK1.5 的默认设置中,当老年代空间已用空间大于 68% 之后,CMS 垃圾回收器便会开始进行垃圾清理。这个数值相对比较保守一些,我们可以通过 -XX:CMSInitiatingOccupancyFraction 参数自行调节。在 JDK1.6 种,该阈值被提升至 92%。
如果在 CMS 运行期间发现预留的内存无法满足程序需要,就会提示「Concurrent Mode Failure」错误。此时虚拟机采用后备方案:临时启用 Serial Old 回收器来重新进行老年代的垃圾回收,这时候 Stop the World 的时间可能就会很长了。
产生空间碎片。 由于 CMS 是基于「标记-清除」算法实现的回收器,因此其会产生很多空间碎片,这会导致给大对象分配的时候很麻烦,会提前触发 Full GC。为了解决这个问题,CMS 回收器提供了 -XX:+UseCMSCompactAtFullCollection 参数来解决这个问题,意思是在空间不够的时候进行空间整理,这个参数默认是打开的。
该参数通常和 -XX:CMSFullGCsBeforeCompaction 一起使用,后者用于设置执行多少次不压缩的 Full GC 之后,跟着来一次带压缩的 Full GC(默认值是 0,表示每次进入 Full GC 时都进行碎片整理)。
总结
CMS 回收器,诞生于 JDK1.5,失落于 JDK9,卒于 JDK14。它的诞生,开启了垃圾回收器专注于优化 GC 停顿时间的历史,随后的 G1、ZGC 都在 CMS 的基础之上改进、优化而来。
而 CMS 回收器之所以能实现对 GC 停顿时间的强力控制,全都归功于对于「根可达算法」的优化。其将串行的引用链扫描,拆分成了「初始标记」和「并发标记」两个阶段,从而极大地降低了 GC 停顿时间,最后再通过「重新标记」解决了并发执行产生的问题。
参考资料
- CMS 低延迟垃圾收集器详解 - 掘金
- 深入理解 JAVA 垃圾收集器 CMS,G1 工作流程原理 - 掘金
- 深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第 2 版)- 周志明 - 微信读书
关于 CMS 垃圾回收器,你真的懂了吗?的更多相关文章
- 探索ParNew和CMS垃圾回收器
前言 上篇文章我们一起分析了JVM的垃圾回收机制,了解了新生代的内存模型,老年代的空间分配担保原则,并简单的介绍了几种垃圾回收器.详细内容小伙伴们可以去看一下我的上篇文章:秒懂JVM的垃圾回收机制. ...
- 【JVM】CMS垃圾回收器
一.简介 Concurrent Mark Sweep,是一种以获取最短回收停顿时间为目标的收集器,尤其重视服务的响应速度. CMS是老年代垃圾回收器,基于标记-清除算法实现.新生代默认使用ParNew ...
- jvm——CMS 垃圾回收器(未完)
https://matt33.com/2018/07/28/jvm-cms/ 阶段1:Initial Mark stop-the-wolrd 标记那些直接被 GC root 引用或者被年轻代存活对象所 ...
- GC: CMS垃圾回收器一(英文版)
Memory Management in the Java HotSpot™ Virtual Machine Concurrent Mark-Sweep (CMS) Collector For man ...
- GC: CMS垃圾回收器三(实践)
jstat -gc -t [pid] 1000 监控日志... ,抽取其中关键记录不一定连续 应用启动时间 2015-06-23 10:22:27 ,换算后,第二条记录时间是2015-06-24 22 ...
- JVM七大垃圾回收器上篇Serial、ParNeW、Parallel Scavenge、 Serial Old、 Parallel Old、 CMS、 G1
GC逻辑分类 垃圾收集器没有在规范中进行过多的规定,可以由不同的厂商.不同版本的JVM来实现. 由于JDK的版本处于高速迭代过程中,因此Java发展至今已经衍生了众多的GC版本. 从不同角度分析垃圾收 ...
- java架构之路-(12)JVM垃圾回收算法和垃圾回收器
接上次JVM虚拟机堆内存模型来继续说,上次我们主要说了什么时候可能把对象直接放在老年代,还有我们的可能性分析,提出GCroot根的概念.这次我们主要来说说垃圾回收所使用的的算法和我们的垃圾回收器,需要 ...
- JVM 专题二十一:垃圾回收(五)垃圾回收器 (二)
3. 回收器 3.1 Serial回收器:串行回收 3.1.1 概述 Serial收集器是最基本.历史最悠久的垃圾收集器了.JDK1.3之前回收新生代唯一的选择. Serial收集器作为Hotspot ...
- JVM 垃圾回收器工作原理及使用实例介绍(转载自IBM),直接复制粘贴,需要原文戳链接
原文 https://www.ibm.com/developerworks/cn/java/j-lo-JVMGarbageCollection/ 再插一个关于线程和进程上下文,待判断 http://b ...
随机推荐
- 注解,lombok
使用注解开发 UserMapper public interface UserMapper { @Select("select * from db4.user") List< ...
- Atlas2.2.0编译、安装及使用(集成ElasticSearch,导入Hive数据)
1.编译阶段 组件信息: 组件名称 版本 Atals 2.2.0 HBase 2.2.6 Hive 3.1.2 Hadoop 3.1.1 Kafka 2.11_2.4.1 Zookeeper 3.6. ...
- mysql的命令二
1.插入数据 格式一:insert into table_name valuse (字段1,字段2): insert test1 values ('wangsan',22,'male'); 格式二:i ...
- 设计模式存在哪些关联关系,六种关系傻傻分不清--- UML图示详解
前言 UML俗称统一建模语言.我们可以简单理解成他是一套符号语言.不同的符号对应不同的含义.在之前设计模式章节中我们文章中用到的就是UML类图,UML除了类图意外还有用例图,活动图,时序图. 关于UM ...
- Vue2手写源码---响应式数据的变化
响应式数据变化 数据发生变化后,我们可以监听到这个数据的变化 (每一步后面的括号是表示在那个模块进行的操作) 手写简单的响应式数据的实现(对象属性劫持.深度属性劫持.数组函数劫持).模板转成 ast ...
- SpringCloud基础概念学习笔记(Eureka、Ribbon、Feign、Zuul)
SpringCloud基础概念学习笔记(Eureka.Ribbon.Feign.Zuul) SpringCloud入门 参考: https://springcloud.cc/spring-cloud- ...
- 从零搭建Pytorch模型教程(四)编写训练过程--参数解析
前言 训练过程主要是指编写train.py文件,其中包括参数的解析.训练日志的配置.设置随机数种子.classdataset的初始化.网络的初始化.学习率的设置.损失函数的设置.优化方式的设置. ...
- CF1682D Circular Spanning Tree
题意: 构造题,节点1~n顺时针排列成圆形,告诉你每个点度数奇偶性,让你构造一棵树,树边不相交. 思路: 因为每条边给总度数贡献2,因此如果度数为1的点有奇数个,直接输出no.显然0个度数为1的,也输 ...
- Linux文件拷贝脚本
在工作中,我们经常遇到要从Linux服务器拷贝日志至本地或者定期清理日志的需求,在服务器上,大型系统的日志是按模块存储的,这就导致日志的文件目录较多且层级不统一.我们从众多的目录手工筛选要下载或者删除 ...
- 基于Kubernetes v1.24.0的集群搭建(一)
一.写在前面 K8S 1.24作为一个很重要的版本更新,它为我们提供了很多重要功能.该版本涉及46项增强功能:其中14项已升级为稳定版,15项进入beta阶段,13项则刚刚进入alpha阶段.此外,另 ...